新闻稿摘要
Meta 和莱斯大学的研究人员开发了 MetaEmbed,这是一种全新的多模态搜索方法,可让系统按需调整其准确性和速度。当前的多模态检索系统跨文本和图像进行搜索,面临着精度与计算效率之间的权衡——它们要么将所有信息压缩为单个会丢失细节的向量,要么使用数百个向量从而过于缓慢、不切实际。MetaEmbed 引入了可学习的“Meta Token”,它们能创建一小组从粗到细组织信息的上下文化嵌入。这一设计使用户可以选择在搜索时使用多少个向量,从而在质量与速度需求之间取得平衡。在标准基准测试上的实验表明,该系统在实现最先进性能的同时还能稳健扩展
摘要
通用多模态嵌入模型在捕捉查询与候选项之间的语义相关性方面取得了巨大成功。然而,现有方法要么将查询和候选项压缩为单个向量,可能限制对细粒度信息的表达能力,要么生成过多向量,使得多向量检索代价过高。在这项工作中,我们提出了 MetaEmbed,这是一个用于多模态检索的新框架,它重新思考了如何在大规模场景下构建多模态嵌入以及如何与之交互。在训练期间,固定数量的可学习 Meta Token 被附加到输入序列中。在测试时,它们最后一层的上下文化表示充当紧凑而富有表达力的多向量嵌入。通过我们提出的 Matryoshka Multi-Vector Retrieval 训练,MetaEmbed 学会了跨多个向量按粒度组织信息。因此,我们实现了多模态检索中的测试时扩展,用户可以通过选择用于索引和检索交互的 token 数量,在检索质量与效率需求之间取得平衡。在 Massive Multimodal Embedding Benchmark(MMEB)和 Visual Document Retrieval Benchmark(ViDoRe)上的大量评估证实,MetaEmbed 在实现最先进检索性能的同时,能够稳健地扩展到 32B 参数的模型。代码已发布于 https://github.com/facebookresearch/MetaEmbed。
详情
引用
@inproceedings{xiao2026metaembed,
title = {MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction},
author = {Xiao, Zilin and Ma, Qi and Gu, Mengting and Chen, Chun-cheng Jason and Chen, Xintao and Ordonez, Vicente and Mohan, Vijai},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2509.18095},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
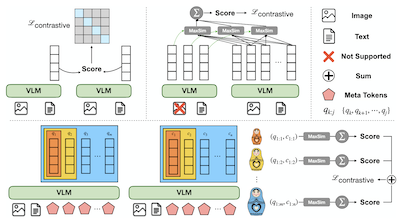
- 什么是 MetaEmbed,它解决了什么问题?MetaEmbed 是一个多模态检索框架,它使用紧凑的可学习 Meta Token,提供比单向量嵌入更具表达力的检索,同时避免数百个图块级向量带来的沉重开销。
- MetaEmbed 如何实现测试时扩展?它通过 Matryoshka Multi-Vector Retrieval 训练嵌套的 Meta Embedding 组,因此用户可以在索引和打分时选择更小或更大的检索预算,而无需重新训练。
- 为什么 Meta Token 对多模态检索有用?它们最后一层的上下文化状态充当一小组多向量嵌入,在保留细粒度查询-候选项交互的同时,使索引大小和打分成本保持可控。
- MetaEmbed 在 MMEB 上的表现如何?论文报告称,以 Qwen2.5-VL 初始化的 MetaEmbed 在 7B 模型上整体 Precision@1 达到 76.6,在 32B 模型上达到 78.7,优于所列出的基线。
- MetaEmbed 适用于视觉文档检索吗?是的,论文在 ViDoRe 上进行了评估,结果表明随着使用更多的 Meta Embedding,检索质量会提升,而 MMR 在低检索预算下仍能保持强劲性能。
主要贡献
- 论文引入 Meta Token,作为用于多模态检索的紧凑上下文化多向量嵌入,可处理文本、图像和混合模态的查询与候选项。
- Matryoshka Multi-Vector Retrieval 训练从粗到细的嵌套嵌入组,使单一模型和索引设计能够支持多个质量-延迟的工作点。
- MetaEmbed 在 MMEB 上取得了最先进的结果,并在 ViDoRe 上取得了强劲成绩,同时可扩展到 32B 视觉-语言模型骨干网络。
- 消融实验表明,多向量检索的收益随模型规模增长而增大,而 MMR 对于在低预算下保持检索质量至关重要。
- 效率分析表明,在中等预算下打分延迟仍然很小,并且可以通过选择平衡的检索设置来管理索引内存。
局限与注意事项
- 较高的检索预算会增加索引内存,但嵌套设计使其成为用户可控的权衡,而非固定的部署成本。
- 最大的预算可能会大幅增加打分的 FLOPs,但实测延迟在许多设置下仍然实用,并且论文表明在更小的预算下也能取得有用的准确性。
- MetaEmbed 仍然需要对强大的 VLM 骨干网络进行微调,因此未来的工作可以探索更轻量的训练方案;而 LoRA 设置和多架构实验已使该方法具有广泛的可及性。
- 评估侧重于标准的多模态和视觉文档检索基准,将超大规模生产索引和专门的企业领域留作自然的部署研究。
- 该方法面向检索而非直接的生成或问答,但更好的灵活检索是检索增强多模态系统的宝贵基础模块。
如何理解这一结果
这篇论文最好被理解为对可扩展多模态检索的有力贡献:MetaEmbed 保留了细粒度的后期交互,增加了实用的测试时预算调节旋钮,并表明在配备紧凑的多向量接口后,更大的 VLM 可以成为更有效的检索模型。