One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
Zusammenfassung der Pressemitteilung
Forschende der Rice University und von Snap Inc. haben eine Technik namens ELIT entwickelt, kurz für Elastic Latent Interface Transformer, die Bild- und Videogenerierungsmodellen die Fähigkeit verleiht, Berechnungsgeschwindigkeit gegen Ausgabequalität spontan abzuwägen – ohne das Modell für jeden gewünschten Betriebspunkt neu zu trainieren. Das Kernproblem, das sie angingen, besteht darin, dass standardmäßige Diffusion-Transformer-Modelle für jeden Bildausschnitt denselben Rechenaufwand aufwenden, unabhängig davon, ob dieser Ausschnitt komplexe Details oder leeren Himmel enthält, und dass sie an feste Rechenkosten gebunden sind, die an die Bildauflösung gekoppelt sind. Um dies zu beheben, fügte das Team eine kleine Menge erlernbarer „Latent-Tokens“ zwischen den frühen und späten Verarbeitungsstufen des Modells ein, verbunden durch zwei leichtgewichtige Cross-Attention-Schichten, die sie Read und Write nennen. Während des Trainings verwirft das Modell einige dieser Latent-Tokens zufällig, was es zwingt, die wichtigsten Informationen in die Tokens zu packen, die es am häufigsten behält, wodurch eine natürlich geordnete Repräsentation entsteht. Zur Inferenzzeit kann eine Nutzerin oder ein Nutzer einfach wählen, wie viele Latent-Tokens verwendet werden, und damit die Berechnung direkt hoch- oder herunterregeln. Getestet über mehrere beliebte Architekturen hinweg, darunter DiT, U-ViT, HDiT und das Qwen-Image-Modell mit 20 Milliarden Parametern, verbesserte ELIT konsistent die Bildqualitätsmetriken – die FID-Werte wurden auf 512-Pixel-ImageNet-Benchmarks um bis zu 53 % gesenkt – und ermöglichte es Nutzenden zugleich, die Berechnung um rund 35 % bis 65 % bei nur geringem Qualitätsverlust zu reduzieren. Der Ansatz ermöglicht außerdem eine kostengünstigere Form der Classifier-Free Guidance, indem er die tokenarme Version desselben Modells als eingebaute „schwache“ Referenz verwendet, was die Guidance-Kosten um etwa ein Drittel reduziert.
Zusammenfassung
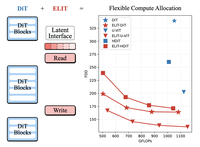
Diffusion Transformer (DiTs) erzielen eine hohe generative Qualität, koppeln jedoch FLOPs an die Bildauflösung, was prinzipielle Kompromisse zwischen Latenz und Qualität einschränkt, und verteilen die Berechnung gleichmäßig über die räumlichen Eingabe-Tokens, wodurch Ressourcen für unwichtige Regionen verschwendet werden. Wir führen den Elastic Latent Interface Transformer (ELIT) ein, einen Drop-in-, DiT-kompatiblen Mechanismus, der die Eingabebildgröße von der Berechnung entkoppelt. Unser Ansatz fügt eine latente Schnittstelle ein, eine erlernbare Token-Sequenz variabler Länge, auf der standardmäßige Transformer-Blöcke operieren können. Leichtgewichtige Read- und Write-Cross-Attention-Schichten bewegen Informationen zwischen räumlichen Tokens und Latents und priorisieren wichtige Eingaberegionen. Durch das Training mit zufälligem Verwerfen von End-Latents lernt ELIT, wichtigkeitsgeordnete Repräsentationen zu erzeugen, bei denen frühere Latents die globale Struktur erfassen, während spätere Informationen zur Verfeinerung von Details enthalten. Zur Inferenzzeit kann die Anzahl der Latents dynamisch angepasst werden, um den Rechenbeschränkungen zu entsprechen. ELIT ist bewusst minimal gehalten und fügt zwei Cross-Attention-Schichten hinzu, während das Rectified-Flow-Ziel und der DiT-Stack unverändert bleiben. Über Datensätze und Architekturen hinweg (DiT, U-ViT, HDiT, MM-DiT) liefert ELIT konsistente Verbesserungen. Auf ImageNet-1K 512px liefert ELIT einen durchschnittlichen Gewinn von $35,3\%$ und $39,6\%$ bei den FID- und FDD-Werten. Projektseite: https://snap-research.github.io/elit/
Details
Zitation
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist ELIT und welches Problem adressiert es? ELIT ist ein Drop-in-Mechanismus mit latenter Schnittstelle für Diffusion Transformer, der die Berechnung von der Bildauflösung entkoppelt und es einem einzigen generativen Modell ermöglicht, über mehrere Qualitäts- und Latenzbudgets hinweg zu arbeiten.
- Wie verändert ELIT einen Diffusion Transformer? Es fügt eine Menge von Latent-Tokens variabler Länge zwischen einem kurzen räumlichen Kopf und Schwanz ein und verwendet leichtgewichtige Read- und Write-Cross-Attention-Schichten, um Informationen zwischen Bild-Tokens und der latenten Schnittstelle zu bewegen.
- Wie ermöglicht ELIT flexible Inferenzbudgets? Während des Trainings werden End-Latent-Tokens zufällig verworfen, sodass frühere Tokens die wichtigsten Informationen lernen, und zur Inferenzzeit wählen Nutzende, wie viele Latent-Tokens behalten werden, um die FLOPs zu steuern.
- Welche empirischen Gewinne berichtet ELIT? Auf ImageNet-1K 512px verbessert ELIT FID und FDD erheblich über die DiT-, U-ViT- und HDiT-Backbones hinweg, einschließlich einer FID-Verbesserung von bis zu 53 Prozent für die in der Arbeit berichtete DiT-Einstellung.
- Skaliert ELIT auf große Generierungsmodelle? Ja, die Arbeit wendet ELIT auf Qwen-Image an, ein 20B-MM-DiT-Modell, und zeigt einen reibungslosen Kompromiss zwischen Berechnung und Qualität mit einer Beschleunigung von bis zu etwa 2,7x, während starke DPG-Bench-Werte beibehalten werden.
Wichtigste Beiträge
- Die Arbeit führt eine minimale Read/Write-Latent-Schnittstelle ein, die das Rectified-Flow-Ziel und den DiT-Hauptstack unverändert lässt, was ELIT leicht auf bestehende Diffusion-Transformer-Familien aufpfropfbar macht.
- ELIT demonstriert adaptive Berechnung, indem es die Read-Schicht nutzt, um informative räumliche Regionen in die latente Schnittstelle zu ziehen, statt gleich viel Berechnung für einfache oder aufgefüllte Regionen aufzuwenden.
- Die Multi-Budget-Trainingsstrategie erzeugt eine wichtigkeitsgeordnete Latent-Sequenz, die es einer einzigen Gewichtsmenge ermöglicht, viele Inferenzbudgets ohne erneutes Training zu unterstützen.
- Experimente zeigen konsistente Verbesserungen der Bildgenerierung über DiT, U-ViT und HDiT hinweg, günstige Videogenerierungsergebnisse auf Kinetics-700 sowie Kompatibilität mit trainingsfreien Beschleunigungsmethoden wie TeaCache.
- ELIT ermöglicht kostengünstige Guidance und Autoguidance, indem es budgetärmere Versionen desselben Modells als schwache Referenzen verwendet, was die Guidance-Kosten senkt und zugleich die Sample-Qualität verbessert.
Grenzen und Vorbehalte
- ELIT fügt Read- und Write-Schichten sowie eine Latent-Token-Planung hinzu, sodass es eine kleine architektonische Änderung statt einer rein trainingsfreien Beschleunigungsmethode ist; das Drop-in-Design und die breiten Backbone-Ergebnisse machen diese zusätzliche Komplexität gut gerechtfertigt.
- Das Qwen-Image-Experiment führt ein großes bestehendes Modell mit verfügbaren realen und synthetischen Daten fein nach, statt die vollständige proprietäre Trainingspipeline des Originalmodells zu reproduzieren, liefert aber dennoch wertvolle Belege dafür, dass ELIT auf MM-DiT-Systeme mit 20B Parametern skaliert.
- Die budgetärmsten Qwen-Image-Einstellungen tauschen etwas Benchmark-Qualität gegen Geschwindigkeit, was für ein elastisches Modell zu erwarten und nützlich ist, da Nutzende das Budget wählen können, das ihren Latenz- und Qualitätsanforderungen entspricht.
- Die meisten detaillierten Ablationen beziehen sich auf klassenbedingte ImageNet- und Kinetics-Einstellungen, sodass Details der Text-zu-Bild-Bereitstellung und nutzerseitige Qualitätspräferenzen natürliche künftige Evaluationsrichtungen bleiben.
- Die Methode verbessert die Berechnungsverteilung innerhalb von DiT-artigen Generatoren, statt alle anderen Effizienztechniken zu ersetzen, und die Kompatibilität mit TeaCache und Guidance-Strategien legt nahe, dass sie produktiv mit ergänzenden Beschleunigern kombiniert werden kann.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit ist am besten als ein starker Systems-und-Modellierungs-Beitrag für Diffusion Transformer zu lesen: ELIT gibt einem einzigen Modell praktische Kontrolle über Rechenbudgets, verbessert die Generierungsqualität über mehrere Backbones hinweg und skaliert die Idee auf große moderne Bildgeneratoren, während es die Kernänderungen an der Architektur kompakt hält.