One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
プレスリリース要約
ライス大学とSnap Inc.の研究者らは、Elastic Latent Interface Transformerの略であるELITと呼ばれる技術を開発した。これは、所望の動作点ごとにモデルを再訓練することなく、画像および動画生成モデルに計算速度と出力品質をその場でトレードオフする能力を与える。彼らが取り組んだ中心的な問題は、標準的な拡散トランフォーマーモデルが、画像の各パッチが複雑な詳細を含むか何もない空であるかにかかわらず、すべてのパッチに同じ量の計算を費やすこと、そして画像解像度に結びついた固定の計算コストに縛られていることである。これを修正するため、研究チームはモデルの初期と後期の処理段階の間に、ReadおよびWriteと呼ぶ二つの軽量なクロスアテンション層で接続された、学習可能な「潜在トークン」の小さな集合を挿入した。訓練中、モデルはそれらの潜在トークンの一部をランダムに脱落させ、これにより最も頻繁に保持するトークンに最も重要な情報を詰め込まざるを得なくなり、自然に順序付けられた表現が生み出される。推論時には、ユーザは使用する潜在トークンの数を単に選ぶだけで、計算量を直接的に上下に調整できる。DiT、U-ViT、HDiT、および200億パラメータのQwen-Imageモデルを含むいくつかの普及したアーキテクチャにわたって検証したところ、ELITは画像品質の指標を一貫して改善し、512ピクセルのImageNetベンチマークではFIDスコアを最大53%削減する一方で、ユーザがわずかな品質の損失だけで計算量をおよそ35%から65%削減できるようにもした。このアプローチはまた、同じモデルの低トークン版を組み込みの「弱い」基準として用いることで、より安価な形のclassifier-free guidanceを可能にし、誘導コストを約三分の一削減する。
要旨
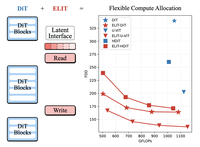
拡散トランスフォーマー(DiT)は高い生成品質を達成するが、FLOPsを画像解像度に固定してしまうため原理的な遅延と品質のトレードオフが制限され、また入力空間トークン全体に一様に計算を割り当てるため、重要でない領域に資源を割り当てて無駄にする。我々は、入力画像のサイズを計算から切り離す、ドロップイン可能でDiT互換の機構であるElastic Latent Interface Transformer(ELIT)を導入する。我々のアプローチは、標準的なトランスフォーマーブロックが動作できる学習可能な可変長トークン列である潜在インターフェースを挿入する。軽量なReadおよびWriteのクロスアテンション層が、空間トークンと潜在変数の間で情報を移動させ、重要な入力領域を優先する。末尾の潜在変数をランダムに脱落させて訓練することで、ELITは重要度順に並んだ表現を生成することを学習し、初期の潜在変数が大域的構造を捉える一方で、後の潜在変数は詳細を精緻化するための情報を含む。推論時には、潜在変数の数を計算上の制約に合わせて動的に調整できる。ELITは意図的に最小限であり、整流フローの目的関数とDiTスタックを変えないまま、二つのクロスアテンション層を加える。データセットおよびアーキテクチャ(DiT、U-ViT、HDiT、MM-DiT)にわたって、ELITは一貫した向上をもたらす。ImageNet-1K 512pxでは、ELITはFIDおよびFDDスコアでそれぞれ平均$35.3\%$および$39.6\%$の向上をもたらす。プロジェクトページ:https://snap-research.github.io/elit/
詳細
引用
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- ELITとは何であり、どのような問題に取り組むのか。ELITは拡散トランスフォーマーのためのドロップイン可能な潜在インターフェース機構であり、計算を画像解像度から切り離し、一つの生成モデルが複数の品質と遅延の予算にわたって動作できるようにする。
- ELITは拡散トランスフォーマーをどのように変えるのか。短い空間的なヘッドとテールの間に可変長の潜在トークンの集合を挿入し、軽量なReadおよびWriteのクロスアテンション層を用いて画像トークンと潜在インターフェースの間で情報を移動させる。
- ELITはどのように柔軟な推論予算を提供するのか。訓練中、末尾の潜在トークンがランダムに脱落させられるため初期のトークンが最も重要な情報を学習し、推論時にはユーザがFLOPsを制御するために保持する潜在トークンの数を選ぶ。
- ELITはどのような経験的向上を報告しているか。ImageNet-1K 512pxにおいて、ELITはDiT、U-ViT、HDiTのバックボーンにわたってFIDとFDDを大幅に改善し、本論文で報告されたDiTの設定では最大53パーセントのFIDの改善を含む。
- ELITは大規模な生成モデルへスケールするか。然り、本論文は20BのMM-DiTモデルであるQwen-ImageにELITを適用し、強力なDPG-Benchスコアを維持しながら最大およそ2.7倍の高速化を伴う滑らかな計算と品質のトレードオフを示している。
主な貢献
- 本論文は、整流フローの目的関数と主要なDiTスタックを変えないまま保つ最小限のRead/Write潜在インターフェースを導入し、ELITを既存の拡散トランスフォーマーの系列に容易に接ぎ木できるようにする。
- ELITは、易しい領域やパディングされた領域に等しい計算を費やすのではなく、Read層を用いて情報量の多い空間領域を潜在インターフェースに引き込むことで、適応的な計算を実証する。
- マルチ予算の訓練戦略は重要度順に並んだ潜在系列を作り出し、単一の重みの集合が再訓練なしに多くの推論予算を支えられるようにする。
- 実験は、DiT、U-ViT、HDiTにわたる一貫した画像生成の改善、Kinetics-700における良好な動画生成の結果、およびTeaCacheのような訓練不要の高速化手法との互換性を示している。
- ELITは、同じモデルのより低予算の版を弱い基準として用いることで、安価な誘導と自己誘導を可能にし、誘導コストを削減しながらサンプル品質を改善する。
限界と注意点
- ELITはReadおよびWrite層に加えて潜在トークンのスケジューリングを加えるため、純粋に訓練不要の高速化手法というよりは小さなアーキテクチャの変更である。ドロップイン可能な設計と幅広いバックボーンでの結果は、その追加された複雑さを十分に正当化している。
- Qwen-Imageの実験は、元のモデルの完全な独自の訓練パイプラインを再現するのではなく、利用可能な実データと合成データで大規模な既存モデルをファインチューニングしているが、それでもELITが20BパラメータのMM-DiTシステムへスケールするという価値ある証拠を提供している。
- 最低予算のQwen-Imageの設定は速度のためにいくらかのベンチマーク品質を犠牲にしており、これは弾力的なモデルにとって予想されることであり、ユーザが自身の遅延と品質のニーズに合う予算を選べるため有用である。
- 最も詳細なアブレーションの大半はクラス条件付きのImageNetとKineticsの設定に関するものであり、テキストから画像への展開の詳細とユーザ向けの品質選好は、自然な今後の評価の方向として残されている。
- 本手法は、他のすべての効率化技術を置き換えるのではなくDiTのような生成器の内部の計算割り当てを改善するものであり、TeaCacheおよび誘導戦略との互換性は、それを補完的な高速化手法と生産的に組み合わせられることを示唆している。
この結果の読み解き方
本論文は、拡散トランスフォーマーのための強力なシステムとモデリングの貢献として読むのが最も適切である。すなわち、ELITは一つのモデルに計算予算の実用的な制御を与え、いくつかのバックボーンにわたって生成品質を改善し、中核的なアーキテクチャの変更をコンパクトに保ちながら、その発想を大規模な現代の画像生成器へとスケールさせている。