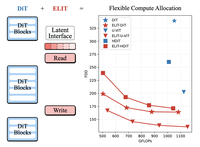
One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
보도 자료 요약
라이스 대학교와 Snap Inc.의 연구자들은 각각의 원하는 동작 지점마다 모델을 재학습하지 않고도 이미지 및 비디오 생성 모델이 연산 속도와 출력 품질을 즉석에서 절충할 수 있게 해 주는 ELIT(Elastic Latent Interface Transformer의 약자)라는 기법을 개발했다. 이들이 다룬 핵심 문제는 표준 디퓨전 트랜스포머 모델이 이미지의 어떤 패치가 정교한 세부를 담고 있든 텅 빈 하늘을 담고 있든 상관없이 모든 패치에 동일한 양의 연산을 소모하며, 이미지 해상도에 묶인 고정된 연산 비용에 고정되어 있다는 점이다. 이를 해결하기 위해 연구팀은 모델의 초기 처리 단계와 후기 처리 단계 사이에, Read와 Write라고 부르는 두 개의 경량 교차 어텐션 계층으로 연결된 소수의 학습 가능한 "잠재 토큰(latent token)"을 삽입했다. 학습 중에 모델은 이러한 잠재 토큰 중 일부를 무작위로 떨어뜨리는데, 이는 모델이 가장 자주 유지하는 토큰에 가장 중요한 정보를 담도록 강제하여 자연스럽게 정렬된 표현을 만들어낸다. 추론 시에는 사용자가 사용할 잠재 토큰의 개수를 간단히 선택하여 연산량을 직접 올리거나 내릴 수 있다. DiT, U-ViT, HDiT, 그리고 200억 파라미터의 Qwen-Image 모델을 포함한 여러 인기 아키텍처에서 시험한 결과, ELIT는 이미지 품질 지표를 일관되게 향상시켰으며 512픽셀 ImageNet 벤치마크에서 FID 점수를 최대 53%까지 낮췄고, 동시에 사용자가 미미한 품질 저하만으로 연산량을 대략 35%에서 65%까지 줄일 수 있게 했다. 이 접근법은 또한 동일 모델의 저토큰 버전을 내장된 "약한(weak)" 참조로 사용함으로써 더 저렴한 형태의 classifier-free guidance를 가능하게 하여, guidance 비용을 약 3분의 1만큼 줄인다.
초록
디퓨전 트랜스포머(DiT)는 높은 생성 품질을 달성하지만 FLOPs를 이미지 해상도에 고정하여 원칙적인 지연-품질 트레이드오프를 제한하며, 입력 공간 토큰 전반에 걸쳐 연산을 균일하게 할당하여 중요하지 않은 영역에 자원 할당을 낭비한다. 우리는 입력 이미지 크기를 연산으로부터 분리하는, 손쉽게 끼워 넣을 수 있고(drop-in) DiT 호환적인 메커니즘인 Elastic Latent Interface Transformer(ELIT)를 도입한다. 우리의 접근법은 표준 트랜스포머 블록이 동작할 수 있는 학습 가능한 가변 길이 토큰 시퀀스인 잠재 인터페이스(latent interface)를 삽입한다. 경량의 Read 및 Write 교차 어텐션(cross-attention) 계층은 공간 토큰과 잠재 변수 사이에서 정보를 옮기고 중요한 입력 영역에 우선순위를 부여한다. 후미 잠재 변수를 무작위로 떨어뜨리며 학습함으로써, ELIT는 앞쪽 잠재 변수가 전역 구조를 포착하고 뒤쪽 잠재 변수가 세부를 정제하는 정보를 담는, 중요도 순으로 정렬된 표현을 생성하도록 학습한다. 추론 시에는 연산 제약에 맞추어 잠재 변수의 개수를 동적으로 조정할 수 있다. ELIT는 의도적으로 최소화되어 있어, 두 개의 교차 어텐션 계층을 추가하면서도 rectified flow 목적함수와 DiT 스택은 그대로 둔다. 데이터셋과 아키텍처(DiT, U-ViT, HDiT, MM-DiT) 전반에 걸쳐 ELIT는 일관된 향상을 제공한다. ImageNet-1K 512px에서 ELIT는 FID와 FDD 점수에서 각각 평균 $35.3\%$ 및 $39.6\%$의 향상을 제공한다. 프로젝트 페이지: https://snap-research.github.io/elit/
세부 정보
인용
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
- ELIT란 무엇이며 어떤 문제를 다루는가? ELIT는 연산을 이미지 해상도로부터 분리하고 하나의 생성 모델이 여러 품질 및 지연 예산에 걸쳐 동작하도록 하는, 디퓨전 트랜스포머용의 손쉽게 끼워 넣을 수 있는 잠재 인터페이스 메커니즘이다.
- ELIT는 디퓨전 트랜스포머를 어떻게 바꾸는가? ELIT는 짧은 공간적 헤드(head)와 테일(tail) 사이에 가변 길이의 잠재 토큰 집합을 삽입하며, 경량의 Read 및 Write 교차 어텐션 계층을 사용하여 이미지 토큰과 잠재 인터페이스 사이에서 정보를 옮긴다.
- ELIT는 유연한 추론 예산을 어떻게 제공하는가? 학습 중에는 후미 잠재 토큰이 무작위로 떨어뜨려져 앞쪽 토큰이 가장 중요한 정보를 학습하게 되며, 추론 시에는 사용자가 유지할 잠재 토큰의 개수를 선택하여 FLOPs를 제어한다.
- ELIT는 어떤 실험적 향상을 보고하는가? ImageNet-1K 512px에서 ELIT는 DiT, U-ViT, HDiT 백본 전반에 걸쳐 FID와 FDD를 상당히 향상시키며, 여기에는 논문에서 보고된 DiT 설정에서의 최대 53 퍼센트 FID 향상이 포함된다.
- ELIT는 대규모 생성 모델로 확장되는가? 그렇다. 본 논문은 ELIT를 200억 파라미터 MM-DiT 모델인 Qwen-Image에 적용하여, 강력한 DPG-Bench 점수를 유지하면서 최대 약 2.7배의 가속과 함께 매끄러운 연산-품질 트레이드오프를 보인다.
주요 기여
- 본 논문은 rectified-flow 목적함수와 주된 DiT 스택을 그대로 유지하는 최소한의 Read/Write 잠재 인터페이스를 도입하여, ELIT를 기존 디퓨전 트랜스포머 계열에 쉽게 접목할 수 있게 한다.
- ELIT는 쉽거나 패딩된 영역에 동일한 연산을 소모하는 대신 Read 계층을 사용하여 정보가 풍부한 공간 영역을 잠재 인터페이스로 끌어옴으로써 적응적 연산을 입증한다.
- 다중 예산 학습 전략은 중요도 순으로 정렬된 잠재 시퀀스를 만들어, 단일한 가중치 집합이 재학습 없이도 다양한 추론 예산을 지원할 수 있게 한다.
- 실험은 DiT, U-ViT, HDiT 전반에 걸친 일관된 이미지 생성 향상, Kinetics-700에서의 우호적인 비디오 생성 결과, 그리고 TeaCache와 같은 학습이 필요 없는 가속 방법과의 호환성을 보인다.
- ELIT는 동일 모델의 저예산 버전을 약한 참조로 사용함으로써 저렴한 guidance와 autoguidance를 가능하게 하여, 샘플 품질을 향상시키는 동시에 guidance 비용을 줄인다.
한계 및 유의 사항
- ELIT는 Read와 Write 계층 및 잠재 토큰 스케줄링을 추가하므로, 순수하게 학습이 필요 없는 가속 방법이라기보다는 작은 아키텍처 변경에 해당한다. 손쉽게 끼워 넣을 수 있는 설계와 폭넓은 백본 결과는 그 추가된 복잡성을 충분히 정당화한다.
- Qwen-Image 실험은 원본 모델의 전체 독점 학습 파이프라인을 재현하는 대신 가용한 실제 및 합성 데이터로 대형 기존 모델을 미세조정하지만, 그럼에도 ELIT가 200억 파라미터 MM-DiT 시스템으로 확장된다는 가치 있는 증거를 제공한다.
- 가장 낮은 예산의 Qwen-Image 설정은 속도를 위해 일부 벤치마크 품질을 절충하는데, 이는 탄력적 모델에서 예상되는 일이며 사용자가 자신의 지연 및 품질 요구에 맞는 예산을 선택할 수 있다는 점에서 유용하다.
- 대부분의 상세한 절제(ablation) 실험은 클래스 조건부 ImageNet 및 Kinetics 설정에 대한 것이어서, 텍스트-이미지 배치 세부 사항과 사용자 대면 품질 선호도는 자연스러운 향후 평가 방향으로 남는다.
- 이 방법은 다른 모든 효율화 기법을 대체하기보다는 DiT 계열 생성기 내부의 연산 할당을 개선하며, TeaCache 및 guidance 전략과의 호환성은 ELIT가 상호 보완적인 가속기와 생산적으로 결합될 수 있음을 시사한다.
이 결과를 읽는 방법
이 논문은 디퓨전 트랜스포머를 위한 강력한 시스템 및 모델링 기여로 읽는 것이 가장 좋다. ELIT는 하나의 모델에 연산 예산에 대한 실용적인 제어권을 부여하고, 여러 백본에 걸쳐 생성 품질을 향상시키며, 핵심 아키텍처 변경을 작게 유지하면서 이 아이디어를 대형 현대 이미지 생성기로 확장한다.