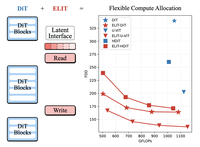
One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
Resumo do comunicado de imprensa
Pesquisadores da Rice University e da Snap Inc. desenvolveram uma técnica chamada ELIT, sigla para Elastic Latent Interface Transformer, que dá aos modelos de geração de imagem e vídeo a capacidade de equilibrar a velocidade de computação com a qualidade da saída em tempo real — sem retreinar o modelo para cada ponto de operação desejado. O problema central que abordaram é que os modelos padrão de transformadores de difusão consomem a mesma quantidade de computação em cada patch de uma imagem, independentemente de esse patch conter detalhes intrincados ou céu vazio, e estão atrelados a um custo computacional fixo ligado à resolução da imagem. Para resolver isso, a equipe inseriu um pequeno conjunto de "tokens latentes" aprendíveis entre os estágios iniciais e finais de processamento do modelo, conectados por duas camadas leves de atenção cruzada que eles chamam de Read e Write. Durante o treinamento, o modelo descarta aleatoriamente alguns desses tokens latentes, o que o força a compactar as informações mais importantes nos tokens que ele mantém com mais frequência, produzindo uma representação naturalmente ordenada. Em tempo de inferência, um usuário pode simplesmente escolher quantos tokens latentes usar, ajustando diretamente a computação para mais ou para menos. Testado em várias arquiteturas populares, incluindo DiT, U-ViT, HDiT e o modelo Qwen-Image de 20 bilhões de parâmetros, o ELIT melhorou de forma consistente as métricas de qualidade de imagem — reduzindo os escores FID em até 53% nos benchmarks do ImageNet de 512 pixels — ao mesmo tempo em que permitiu aos usuários cortar a computação em cerca de 35% a 65% com apenas uma modesta perda de qualidade. A abordagem também viabiliza uma forma mais barata de orientação sem classificador ao usar a versão de poucos tokens do mesmo modelo como uma referência "fraca" embutida, reduzindo os custos de orientação em cerca de um terço.
resumo
Os transformadores de difusão (DiTs) alcançam alta qualidade generativa, mas atrelam os FLOPs à resolução da imagem, limitando compensações principiadas entre latência e qualidade, e alocam computação de forma uniforme entre os tokens espaciais de entrada, desperdiçando alocação de recursos em regiões não importantes. Apresentamos o Elastic Latent Interface Transformer (ELIT), um mecanismo plug-and-play compatível com DiT que desacopla o tamanho da imagem de entrada da computação. Nossa abordagem insere uma interface latente, uma sequência de tokens aprendível de comprimento variável sobre a qual blocos de transformador padrão podem operar. Camadas leves de atenção cruzada Read e Write movem informações entre os tokens espaciais e os latentes e priorizam regiões de entrada importantes. Ao treinar com o descarte aleatório dos latentes de cauda, o ELIT aprende a produzir representações ordenadas por importância, com os latentes iniciais capturando a estrutura global enquanto os posteriores contêm informações para refinar detalhes. Na inferência, o número de latentes pode ser ajustado dinamicamente para atender às restrições de computação. O ELIT é deliberadamente minimalista, adicionando duas camadas de atenção cruzada enquanto mantém inalterados o objetivo de fluxo retificado e a pilha do DiT. Em diversos conjuntos de dados e arquiteturas (DiT, U-ViT, HDiT, MM-DiT), o ELIT proporciona ganhos consistentes. No ImageNet-1K 512px, o ELIT proporciona um ganho médio de $35.3\%$ e $39.6\%$ nos escores FID e FDD. Página do projeto: https://snap-research.github.io/elit/
detalhes
citação
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o ELIT e qual problema ele aborda? O ELIT é um mecanismo plug-and-play de interface latente para transformadores de difusão que desacopla a computação da resolução da imagem e permite que um único modelo generativo opere em múltiplos orçamentos de qualidade e latência.
- Como o ELIT modifica um transformador de difusão? Ele insere um conjunto de comprimento variável de tokens latentes entre uma cabeça e uma cauda espaciais curtas, usando camadas leves de atenção cruzada Read e Write para mover informações entre os tokens de imagem e a interface latente.
- Como o ELIT fornece orçamentos de inferência flexíveis? Durante o treinamento, os tokens latentes de cauda são descartados aleatoriamente para que os tokens iniciais aprendam as informações mais importantes, e na inferência os usuários escolhem quantos tokens latentes manter para controlar os FLOPs.
- Quais ganhos empíricos o ELIT relata? No ImageNet-1K 512px, o ELIT melhora substancialmente o FID e o FDD nos backbones DiT, U-ViT e HDiT, incluindo uma melhoria de FID de até 53 por cento no cenário DiT relatado no artigo.
- O ELIT escala para grandes modelos de geração? Sim, o artigo aplica o ELIT ao Qwen-Image, um modelo MM-DiT de 20B, e mostra uma compensação suave entre computação e qualidade com um aumento de velocidade de até cerca de 2,7x, mantendo escores fortes no DPG-Bench.
Principais contribuições
- O artigo introduz uma interface latente Read/Write minimalista que mantém inalterados o objetivo de fluxo retificado e a pilha principal do DiT, tornando o ELIT fácil de enxertar em famílias existentes de transformadores de difusão.
- O ELIT demonstra computação adaptativa ao usar a camada Read para trazer regiões espaciais informativas para a interface latente, em vez de gastar computação igual em regiões fáceis ou preenchidas.
- A estratégia de treinamento multiorçamento cria uma sequência latente ordenada por importância, permitindo que um único conjunto de pesos dê suporte a muitos orçamentos de inferência sem retreinamento.
- Os experimentos mostram melhorias consistentes na geração de imagens nos backbones DiT, U-ViT e HDiT, resultados favoráveis de geração de vídeo no Kinetics-700 e compatibilidade com métodos de aceleração sem treinamento, como o TeaCache.
- O ELIT viabiliza orientação barata e autoguiamento ao usar versões de menor orçamento do mesmo modelo como referências fracas, reduzindo o custo de orientação ao mesmo tempo em que melhora a qualidade das amostras.
Limitações e ressalvas
- O ELIT adiciona camadas Read e Write além do escalonamento de tokens latentes, de modo que é uma pequena alteração arquitetural, em vez de um método de aceleração puramente livre de treinamento; o projeto plug-and-play e os amplos resultados em diversos backbones justificam bem essa complexidade adicional.
- O experimento com o Qwen-Image faz o ajuste fino de um grande modelo existente com dados reais e sintéticos disponíveis, em vez de reproduzir o pipeline de treinamento proprietário completo do modelo original, mas ainda fornece evidências valiosas de que o ELIT escala para sistemas MM-DiT de 20B de parâmetros.
- As configurações de menor orçamento do Qwen-Image trocam parte da qualidade de benchmark por velocidade, o que é esperado para um modelo elástico e útil porque os usuários podem escolher o orçamento que se ajusta às suas necessidades de latência e qualidade.
- A maioria das ablações detalhadas é feita em cenários de ImageNet condicional por classe e de Kinetics, deixando os detalhes de implantação de texto para imagem e as preferências de qualidade voltadas ao usuário como direções naturais de avaliação futura.
- O método melhora a alocação de computação dentro de geradores do tipo DiT, em vez de substituir todas as outras técnicas de eficiência, e a compatibilidade com o TeaCache e com estratégias de orientação sugere que ele pode ser combinado de forma produtiva com aceleradores complementares.
Como interpretar este resultado
Este artigo é mais bem compreendido como uma forte contribuição de sistemas e modelagem para transformadores de difusão: o ELIT dá a um único modelo controle prático sobre orçamentos de computação, melhora a qualidade de geração em vários backbones e escala a ideia para grandes geradores de imagens modernos, ao mesmo tempo em que mantém compactas as alterações centrais de arquitetura.