One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
Tóm tắt thông cáo báo chí
Các nhà nghiên cứu từ Rice University và Snap Inc. đã phát triển một kỹ thuật mang tên ELIT, viết tắt của Elastic Latent Interface Transformer, mang lại cho các mô hình sinh ảnh và video khả năng đánh đổi tốc độ tính toán với chất lượng đầu ra ngay tức thời — mà không cần huấn luyện lại mô hình cho từng điểm vận hành mong muốn. Vấn đề cốt lõi mà họ giải quyết là các mô hình diffusion transformer tiêu chuẩn tiêu tốn cùng một lượng tính toán cho mọi mảng (patch) của ảnh bất kể mảng đó chứa chi tiết phức tạp hay chỉ là bầu trời trống trải, và chúng bị ràng buộc với một chi phí tính toán cố định gắn với độ phân giải ảnh. Để khắc phục điều này, nhóm nghiên cứu chèn một tập nhỏ các "token latent" có thể học được vào giữa các giai đoạn xử lý sớm và muộn của mô hình, được kết nối bằng hai lớp cross-attention nhẹ mà họ gọi là Read và Write. Trong quá trình huấn luyện, mô hình loại bỏ ngẫu nhiên một số token latent đó, buộc nó phải đóng gói thông tin quan trọng nhất vào những token mà nó giữ lại thường xuyên nhất, tạo ra một biểu diễn được sắp xếp một cách tự nhiên. Khi suy luận, người dùng có thể đơn giản chọn số lượng token latent cần sử dụng, trực tiếp tăng hoặc giảm lượng tính toán. Được kiểm thử trên nhiều kiến trúc phổ biến bao gồm DiT, U-ViT, HDiT, và mô hình Qwen-Image 20 tỷ tham số, ELIT cải thiện nhất quán các chỉ số chất lượng ảnh — giảm điểm FID tới 53% trên các benchmark ImageNet 512 pixel — đồng thời cho phép người dùng cắt giảm lượng tính toán khoảng 35% đến 65% chỉ với mức giảm chất lượng khiêm tốn. Cách tiếp cận này cũng mở ra một dạng classifier-free guidance rẻ hơn bằng cách dùng phiên bản ít token của chính mô hình đó làm tham chiếu "yếu" tích hợp sẵn, giảm chi phí guidance khoảng một phần ba.
tóm tắt
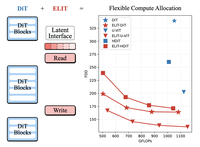
Diffusion transformers (DiTs) đạt chất lượng sinh ảnh cao nhưng lại ràng buộc FLOPs với độ phân giải ảnh, hạn chế các đánh đổi độ trễ-chất lượng có nguyên tắc, và phân bổ tính toán đồng đều trên các token không gian đầu vào, gây lãng phí tài nguyên cho những vùng không quan trọng. Chúng tôi giới thiệu Elastic Latent Interface Transformer (ELIT), một cơ chế gắn-thêm-trực-tiếp, tương thích với DiT, giúp tách kích thước ảnh đầu vào khỏi lượng tính toán. Cách tiếp cận của chúng tôi chèn vào một latent interface, một chuỗi token độ dài thay đổi có thể học được, mà trên đó các khối transformer tiêu chuẩn có thể vận hành. Các lớp cross-attention Read và Write nhẹ di chuyển thông tin giữa các token không gian và các latent đồng thời ưu tiên những vùng đầu vào quan trọng. Bằng cách huấn luyện với việc loại bỏ ngẫu nhiên các latent ở cuối chuỗi, ELIT học cách tạo ra các biểu diễn được sắp xếp theo mức độ quan trọng, trong đó các latent xuất hiện sớm hơn nắm bắt cấu trúc toàn cục còn các latent sau chứa thông tin để tinh chỉnh chi tiết. Khi suy luận, số lượng latent có thể được điều chỉnh linh hoạt để phù hợp với ràng buộc tính toán. ELIT được thiết kế tối giản một cách có chủ đích, chỉ thêm hai lớp cross-attention trong khi vẫn giữ nguyên mục tiêu rectified flow và ngăn xếp DiT. Trên nhiều tập dữ liệu và kiến trúc (DiT, U-ViT, HDiT, MM-DiT), ELIT mang lại những cải thiện nhất quán. Trên ImageNet-1K 512px, ELIT mang lại mức cải thiện trung bình $35.3\%$ và $39.6\%$ về điểm FID và FDD. Trang dự án: https://snap-research.github.io/elit/
chi tiết
trích dẫn
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- ELIT là gì và nó giải quyết vấn đề nào? ELIT là một cơ chế latent-interface gắn-thêm-trực-tiếp cho diffusion transformers, giúp tách lượng tính toán khỏi độ phân giải ảnh và cho phép một mô hình sinh ảnh duy nhất vận hành trên nhiều ngân sách chất lượng và độ trễ khác nhau.
- ELIT thay đổi một diffusion transformer như thế nào? Nó chèn vào một tập token latent độ dài thay đổi giữa một phần đầu (head) và phần đuôi (tail) không gian ngắn, sử dụng các lớp cross-attention Read và Write nhẹ để di chuyển thông tin giữa các token ảnh và latent interface.
- ELIT cung cấp ngân sách suy luận linh hoạt như thế nào? Trong quá trình huấn luyện, các token latent ở cuối chuỗi bị loại bỏ ngẫu nhiên để các token sớm hơn học được thông tin quan trọng nhất, và khi suy luận người dùng chọn số token latent cần giữ lại để kiểm soát FLOPs.
- ELIT báo cáo những cải thiện thực nghiệm nào? Trên ImageNet-1K 512px, ELIT cải thiện FID và FDD đáng kể trên các backbone DiT, U-ViT và HDiT, bao gồm mức cải thiện FID lên tới 53 phần trăm cho cấu hình DiT được báo cáo trong bài.
- ELIT có mở rộng được cho các mô hình sinh ảnh lớn không? Có, bài báo áp dụng ELIT cho Qwen-Image, một mô hình MM-DiT 20B, và cho thấy một đánh đổi tính toán-chất lượng mượt mà với mức tăng tốc tới khoảng 2.7x trong khi vẫn duy trì điểm DPG-Bench mạnh.
Đóng góp chính
- Bài báo giới thiệu một latent interface Read/Write tối giản, giữ nguyên mục tiêu rectified-flow và ngăn xếp DiT chính, giúp ELIT dễ dàng ghép vào các họ diffusion transformer hiện có.
- ELIT minh chứng khả năng tính toán thích ứng bằng cách dùng lớp Read để kéo các vùng không gian giàu thông tin vào latent interface thay vì tiêu tốn lượng tính toán đồng đều cho những vùng dễ hoặc được đệm.
- Chiến lược huấn luyện đa-ngân-sách tạo ra một chuỗi latent được sắp xếp theo mức độ quan trọng, cho phép một tập trọng số duy nhất hỗ trợ nhiều ngân sách suy luận mà không cần huấn luyện lại.
- Các thí nghiệm cho thấy cải thiện sinh ảnh nhất quán trên DiT, U-ViT, và HDiT, kết quả sinh video thuận lợi trên Kinetics-700, và khả năng tương thích với các phương pháp tăng tốc không cần huấn luyện như TeaCache.
- ELIT cho phép guidance và autoguidance rẻ tiền bằng cách dùng các phiên bản ngân sách thấp hơn của cùng một mô hình làm tham chiếu yếu, giảm chi phí guidance đồng thời cải thiện chất lượng mẫu.
Hạn chế và lưu ý
- ELIT thêm các lớp Read và Write cùng với việc lập lịch token latent, nên nó là một thay đổi kiến trúc nhỏ thay vì một phương pháp tăng tốc thuần túy không cần huấn luyện; thiết kế gắn-thêm-trực-tiếp và kết quả trên nhiều backbone rộng rãi cho thấy mức phức tạp tăng thêm đó hoàn toàn hợp lý.
- Thí nghiệm Qwen-Image tinh chỉnh một mô hình lớn có sẵn với dữ liệu thực và tổng hợp khả dụng thay vì tái tạo toàn bộ quy trình huấn luyện độc quyền của mô hình gốc, nhưng nó vẫn cung cấp bằng chứng giá trị rằng ELIT mở rộng được cho các hệ thống MM-DiT 20B tham số.
- Các cấu hình Qwen-Image ngân sách thấp nhất đánh đổi một phần chất lượng benchmark để lấy tốc độ, điều này là dự kiến đối với một mô hình đàn hồi và hữu ích bởi người dùng có thể chọn ngân sách phù hợp với nhu cầu độ trễ và chất lượng của họ.
- Hầu hết các phân tích loại bỏ chi tiết được thực hiện trên các cấu hình ImageNet và Kinetics có điều kiện theo lớp, để lại các chi tiết triển khai text-to-image và sở thích chất lượng từ phía người dùng làm những hướng đánh giá tự nhiên trong tương lai.
- Phương pháp cải thiện việc phân bổ tính toán bên trong các bộ sinh kiểu DiT thay vì thay thế tất cả các kỹ thuật hiệu quả khác, và khả năng tương thích với TeaCache cùng các chiến lược guidance cho thấy nó có thể được kết hợp một cách hiệu quả với các bộ tăng tốc bổ trợ.
Cách diễn giải kết quả này
Bài báo này nên được đọc như một đóng góp mạnh về hệ thống và mô hình hóa cho diffusion transformers: ELIT mang lại cho một mô hình khả năng kiểm soát thực tế các ngân sách tính toán, cải thiện chất lượng sinh ảnh trên nhiều backbone, và mở rộng ý tưởng này tới các bộ sinh ảnh lớn hiện đại trong khi vẫn giữ những thay đổi kiến trúc cốt lõi gọn nhẹ.