One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers
Résumé du communiqué de presse
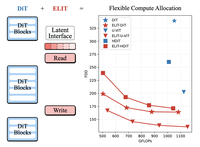
Des chercheurs de Rice University et de Snap Inc. ont mis au point une technique appelée ELIT, pour Elastic Latent Interface Transformer, qui donne aux modèles de génération d'images et de vidéos la capacité d'arbitrer à la volée entre la vitesse de calcul et la qualité de sortie — sans réentraîner le modèle pour chaque point de fonctionnement souhaité. Le problème central qu'ils ont abordé est que les modèles standards de transformeurs de diffusion consomment la même quantité de calcul sur chaque parcelle d'une image, qu'elle contienne des détails complexes ou un ciel vide, et qu'ils sont verrouillés sur un coût de calcul fixe lié à la résolution de l'image. Pour y remédier, l'équipe a inséré un petit ensemble de « jetons latents » apprenables entre les étapes de traitement précoces et tardives du modèle, reliés par deux légères couches d'attention croisée qu'ils nomment Read et Write. Pendant l'entraînement, le modèle abandonne aléatoirement certains de ces jetons latents, ce qui le force à concentrer l'information la plus importante dans les jetons qu'il conserve le plus souvent, produisant une représentation naturellement ordonnée. Au moment de l'inférence, un utilisateur peut simplement choisir le nombre de jetons latents à utiliser, ajustant directement le calcul à la hausse ou à la baisse. Testé sur plusieurs architectures populaires, dont DiT, U-ViT, HDiT et le modèle Qwen-Image de 20 milliards de paramètres, ELIT a systématiquement amélioré les métriques de qualité d'image — réduisant les scores FID jusqu'à 53 % sur les bancs d'essai ImageNet en 512 pixels — tout en permettant aux utilisateurs de réduire le calcul d'environ 35 % à 65 % avec seulement une modeste perte de qualité. L'approche débloque également une forme moins coûteuse de guidage sans classifieur en utilisant la version à faible nombre de jetons du même modèle comme référence « faible » intégrée, réduisant les coûts de guidage d'environ un tiers.
résumé
Les transformeurs de diffusion (DiT) atteignent une grande qualité générative mais verrouillent les FLOPs à la résolution de l'image, limitant les compromis raisonnés entre latence et qualité, et répartissent le calcul de manière uniforme entre les jetons spatiaux d'entrée, gaspillant des ressources sur des régions sans importance. Nous présentons l'Elastic Latent Interface Transformer (ELIT), un mécanisme prêt à l'emploi et compatible DiT qui découple la taille de l'image d'entrée du calcul. Notre approche insère une interface latente, une séquence de jetons de longueur variable apprenable sur laquelle des blocs de transformeur standards peuvent opérer. De légères couches d'attention croisée Read et Write font transiter l'information entre les jetons spatiaux et les latents et priorisent les régions d'entrée importantes. En s'entraînant avec un abandon aléatoire des latents de queue, ELIT apprend à produire des représentations ordonnées par importance, les premiers latents captant la structure globale tandis que les derniers contiennent l'information permettant d'affiner les détails. À l'inférence, le nombre de latents peut être ajusté dynamiquement pour correspondre aux contraintes de calcul. ELIT est délibérément minimal, ajoutant deux couches d'attention croisée tout en laissant inchangés l'objectif de rectified flow et la pile DiT. Sur l'ensemble des jeux de données et des architectures (DiT, U-ViT, HDiT, MM-DiT), ELIT procure des gains constants. Sur ImageNet-1K 512px, ELIT procure un gain moyen de $35,3\%$ et de $39,6\%$ pour les scores FID et FDD. Page du projet : https://snap-research.github.io/elit/
détails
citation
@inproceedings{hajiali2026one,
title = {One Model, Many Budgets: Elastic Latent Interfaces for Diffusion Transformers},
author = {Haji-Ali, Moayed and Menapace, Willi and Skorokhodov, Ivan and Park, Dogyun and Kag, Anil and Vasilkovsky, Michael and Tulyakov, Sergey and Ordonez, Vicente and Siarohin, Aliaksandr},
year = {2026},
booktitle = {IEEE Conference on Computer Vision and Pattern Recognition. CVPR 2026},
url = {https://arxiv.org/abs/2603.12245},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Qu'est-ce qu'ELIT et quel problème aborde-t-il ? ELIT est un mécanisme d'interface latente prêt à l'emploi pour les transformeurs de diffusion qui découple le calcul de la résolution de l'image et permet à un seul modèle génératif de fonctionner selon plusieurs budgets de qualité et de latence.
- Comment ELIT modifie-t-il un transformeur de diffusion ? Il insère un ensemble de jetons latents de longueur variable entre une tête et une queue spatiales courtes, en utilisant de légères couches d'attention croisée Read et Write pour faire transiter l'information entre les jetons d'image et l'interface latente.
- Comment ELIT fournit-il des budgets d'inférence flexibles ? Pendant l'entraînement, les jetons latents de queue sont abandonnés aléatoirement afin que les jetons antérieurs apprennent l'information la plus importante, et à l'inférence les utilisateurs choisissent le nombre de jetons latents à conserver pour contrôler les FLOPs.
- Quels gains empiriques ELIT rapporte-t-il ? Sur ImageNet-1K 512px, ELIT améliore substantiellement le FID et le FDD sur les squelettes DiT, U-ViT et HDiT, y compris jusqu'à 53 pour cent d'amélioration du FID pour la configuration DiT rapportée dans l'article.
- ELIT passe-t-il à l'échelle des grands modèles de génération ? Oui, l'article applique ELIT à Qwen-Image, un modèle MM-DiT de 20 G de paramètres, et montre un compromis calcul-qualité fluide avec une accélération allant jusqu'à environ 2,7 fois tout en maintenant de solides scores DPG-Bench.
Principales contributions
- L'article introduit une interface latente Read/Write minimale qui laisse inchangés l'objectif de rectified flow et la pile DiT principale, ce qui rend ELIT facile à greffer sur les familles existantes de transformeurs de diffusion.
- ELIT démontre un calcul adaptatif en utilisant la couche Read pour attirer les régions spatiales informatives dans l'interface latente plutôt que de dépenser un calcul égal sur les régions faciles ou remplies de remplissage.
- La stratégie d'entraînement multi-budget crée une séquence latente ordonnée par importance, permettant à un seul jeu de poids de prendre en charge de nombreux budgets d'inférence sans réentraînement.
- Les expériences montrent des améliorations constantes de la génération d'images sur DiT, U-ViT et HDiT, des résultats de génération vidéo favorables sur Kinetics-700, et une compatibilité avec des méthodes d'accélération sans entraînement telles que TeaCache.
- ELIT permet un guidage et un autoguidage peu coûteux en utilisant des versions à plus faible budget du même modèle comme références faibles, réduisant le coût du guidage tout en améliorant la qualité des échantillons.
Limites et mises en garde
- ELIT ajoute des couches Read et Write ainsi qu'un ordonnancement des jetons latents, de sorte qu'il s'agit d'une petite modification architecturale plutôt que d'une méthode d'accélération purement sans entraînement ; la conception prête à l'emploi et les résultats sur un large éventail de squelettes justifient bien cette complexité supplémentaire.
- L'expérience Qwen-Image ajuste un grand modèle existant à l'aide de données réelles et synthétiques disponibles plutôt que de reproduire l'intégralité du pipeline d'entraînement propriétaire du modèle d'origine, mais elle fournit tout de même des preuves précieuses qu'ELIT passe à l'échelle des systèmes MM-DiT de 20 G de paramètres.
- Les configurations Qwen-Image à plus faible budget échangent une partie de la qualité de référence contre de la vitesse, ce qui est attendu pour un modèle élastique et utile car les utilisateurs peuvent choisir le budget correspondant à leurs besoins de latence et de qualité.
- La plupart des ablations détaillées portent sur des configurations ImageNet à conditionnement de classe et Kinetics, laissant les détails de déploiement texte-image et les préférences de qualité côté utilisateur comme directions d'évaluation futures naturelles.
- La méthode améliore l'allocation du calcul à l'intérieur des générateurs de type DiT plutôt que de remplacer toutes les autres techniques d'efficacité, et la compatibilité avec TeaCache et les stratégies de guidage suggère qu'elle peut être combinée de manière productive avec des accélérateurs complémentaires.
Comment interpréter ce résultat
Cet article se lit au mieux comme une solide contribution en matière de systèmes et de modélisation pour les transformeurs de diffusion : ELIT donne à un seul modèle un contrôle pratique sur les budgets de calcul, améliore la qualité de génération sur plusieurs squelettes et étend l'idée aux grands générateurs d'images modernes tout en gardant compactes les modifications de l'architecture de base.