ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
Zusammenfassung der Pressemitteilung
Forschende an der Rice University und bei Google DeepMind haben ein selbstüberwachtes visuelles Lernsystem namens ViC-MAE entwickelt, das ein einzelnes KI-Modell darin trainiert, sowohl Standbilder als auch Video zu verstehen, ohne beschriftete Daten zu erfordern. Die Kernherausforderung, der sie sich annahmen, besteht darin, dass bestehende Modelle dazu neigen, in der einen oder der anderen Modalität gut zu sein, aber nicht in beiden — und insbesondere haben auf Video trainierte Modelle historisch Schwierigkeiten gehabt, bei Bildaufgaben gut abzuschneiden. Ihr Ansatz kombiniert zwei bestehende Techniken: Masked Autoencoders, die ein Modell trainieren, zufällig verborgene Bereiche eines Bildes zu rekonstruieren, und kontrastives Lernen, das ein Modell trainiert, zu erkennen, dass zwei verschiedene Ansichten derselben Szene ähnliche Repräsentationen erzeugen sollten. Der neuartige Kniff besteht darin, dass ViC-MAE, anstatt Bilder künstlich durch das Wiederholen von Frames in Pseudo-Videos zu verwandeln — eine gängige Behelfslösung — Frames, die innerhalb eines realen Videos etwa eine Sekunde auseinander abgetastet werden, als natürliche "augmentierte Ansichten" derselben Szene behandelt und diese zeitlichen Variationen in das kontrastive Lernziel einspeist, während es einzelne Frames weiterhin mit dem Maskierungsverlust rekonstruiert. Das Team stellte außerdem fest, dass das Pooling lokaler Patch-Merkmale zu einer globalen Repräsentation, statt sich auf ein einzelnes Klassifikations-Token zu verlassen, half, ein Kollabieren des Modells während des Trainings zu verhindern. Getestet auf Standard-Benchmarks, erreichte die ViT-Large-Version von ViC-MAE 87,1 % Top-1-Genauigkeit auf ImageNet und 75,9 % auf dem anspruchsvollen Something-Something-v2-Video-Benchmark und übertraf damit die vergleichbare selbstüberwachte Methode OmniMAE um etwa 2,4 Prozentpunkte auf ImageNet, während sie sie auch bei Video-Aufgaben schlug — ein Ergebnis, das nahelegt, dass Videodaten, durchdacht eingesetzt, das Bildverständnis spürbar stärken können, ohne die Video-Leistung zu opfern.
Zusammenfassung
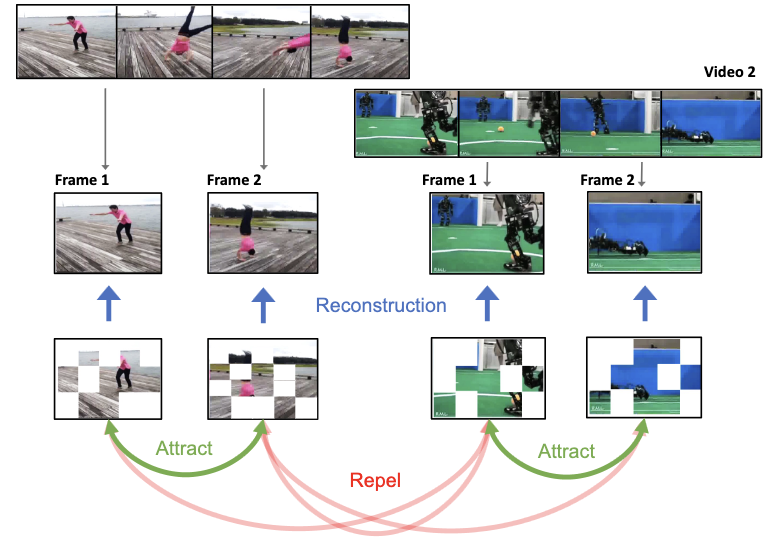
Wir schlagen ViC-MAE vor, ein Modell, das sowohl Masked AutoEncoders (MAE) als auch kontrastives Lernen kombiniert. ViC-MAE wird mithilfe eines globalen Merkmals trainiert, das durch Pooling der unter einem MAE-Rekonstruktionsverlust gelernten lokalen Repräsentationen gewonnen wird, und nutzt diese Repräsentation unter einem kontrastiven Ziel über Bilder und Videoframes hinweg. Wir zeigen, dass die unter ViC-MAE gelernten visuellen Repräsentationen sowohl auf Video- als auch auf Bildklassifikationsaufgaben gut verallgemeinern. Insbesondere erzielt ViC-MAE eine Transfer-Learning-Leistung auf dem Stand der Technik von Video zu Bildern auf Imagenet-1k im Vergleich zum kürzlich vorgeschlagenen OmniMAE, indem es eine Top-1-Genauigkeit von 86 % (+1,3 % absolute Verbesserung) erreicht, wenn es auf denselben Daten trainiert wird, und 87,1 % (+2,4 % absolute Verbesserung), wenn es auf zusätzlichen Daten trainiert wird. Gleichzeitig übertrifft ViC-MAE die meisten anderen Methoden auf Video-Benchmarks, indem es 75,9 % Top-1-Genauigkeit auf dem anspruchsvollen Something-Something-v2-Video-Benchmark erreicht. Beim Training auf Videos und Bildern aus einer vielfältigen Kombination von Datensätzen behält unsere Methode eine ausgewogene Transfer-Learning-Leistung zwischen Video- und Bildklassifikations-Benchmarks bei und liegt nur knapp hinter der besten überwachten Methode.
Details
Zitation
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist ViC-MAE? ViC-MAE ist eine Methode zum selbstüberwachten Lernen visueller Repräsentationen, die Masked Autoencoding mit kontrastivem Lernen kombiniert, sodass ein einziges Backbone nützliche Merkmale sowohl für Bilder als auch für Videos lernen kann.
- Wie nutzt ViC-MAE Video anders als frühere Methoden zum Bild-Video-Pretraining? Anstatt Bilder in Videos mit wiederholten Frames umzuwandeln, behandelt ViC-MAE benachbarte Frames aus realen Videos als natürliche zeitliche Augmentierungen und richtet ihre gepoolten Repräsentationen aufeinander aus.
- Warum Masked Image Modeling und kontrastives Lernen kombinieren? Das Rekonstruktionsziel fördert starke lokale Patch-Merkmale, während das kontrastive Ziel eine globale Invarianz über augmentierte Bilder und zeitlich verschobene Videoframes hinweg fördert.
- Welche Rolle spielt das Pooling in der Methode? ViC-MAE poolt lokale ViT-Merkmale zu einer globalen Repräsentation vor dem kontrastiven Zweig, was die Arbeit als wichtig für ein stabiles Training aufzeigt und vermeidet, sich allein auf ein Klassifikations-Token zu verlassen.
- Welche Belege zeigen, dass ViC-MAE ausgewogene Bild- und Video-Repräsentationen lernt? Die Arbeit berichtet über einen starken Transfer auf ImageNet, Kinetics-400, Places365, Something-Something-v2, mehrere nachgelagerte Bildklassifikations-Datensätze sowie COCO-Detektion und -Segmentierung.
Wichtigste Beiträge
- Die Arbeit führt ein einheitliches selbstüberwachtes Framework ein, das sowohl aus Bildern als auch aus Videos mithilfe einer Kombination aus maskierter Rekonstruktion und kontrastiver Ausrichtung trainiert.
- ViC-MAE zeigt, dass Videoframes als effektive zeitliche Augmentierungen für das Lernen von Repräsentationen auf Bildebene dienen können und so den Video-zu-Bild-Transfer verbessern, ohne die Video-Leistung aufzugeben.
- Die Methode identifiziert globales Pooling über lokale MAE-Merkmale als praktische Designentscheidung für ein stabiles Training kontrastiver maskierter Autoencoder.
- Mit einem ViT-Large-Backbone erreicht ViC-MAE 87,1 % Top-1-Genauigkeit auf ImageNet und 75,9 % Top-1-Genauigkeit auf Something-Something-v2 und übertrifft damit vergleichbare selbstüberwachte Baselines wie OmniMAE in den berichteten Einstellungen.
- Die Arbeit liefert eine breite empirische Validierung über Bildklassifikation, Video-Aktionserkennung, Objektdetektion und Segmentierung hinweg, was den Beitrag über einen einzelnen Benchmark hinaus nützlich macht.
Grenzen und Vorbehalte
- Die stärksten Ergebnisse verwenden große ViT-Backbones und Pretraining über mehrere Datensätze, was für modernes, Foundation-artiges Lernen visueller Repräsentationen typisch ist und hilft, das Skalierungsverhalten der Methode aufzuzeigen.
- ViC-MAE wird in erster Linie durch Transfer- und Feinabstimmungs-Benchmarks bewertet und nicht durch jede mögliche nachgelagerte Video- oder Bildaufgabe, was zusätzliche Bereiche als vielversprechende Folgebewertungen offenlässt.
- Der Ansatz hängt von einer sorgfältigen Balance zwischen Rekonstruktions- und kontrastiven Zielen ab, aber die Arbeit enthält Ablationen zu Pooling, Frame-Abstand, Augmentierungen und Datenmischung, die die Designentscheidungen verdeutlichen.
- Die Methode verbessert das einheitliche selbstüberwachte Bild-Video-Lernen, während aufgabenspezifische überwachte Modelle bei einigen einzelnen Benchmarks weiterhin konkurrenzfähig sein können; dies stellt ViC-MAE als einen starken allgemeinen Repräsentationslerner dar und nicht als einen engen Spezialisten.
- Die Arbeit konzentriert sich auf rein visuelles Pretraining, sodass Erweiterungen auf Text, Audio oder eine breitere multimodale Ausrichtung natürliche Möglichkeiten bleiben, die auf demselben Framework aufbauen.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit lässt sich am besten als ein starker und praktischer Fortschritt beim selbstüberwachten Lernen von Bild-Video-Repräsentationen lesen: ViC-MAE zeigt, dass Videodaten Bildrepräsentationen verbessern können, während eine ausgezeichnete Video-Leistung erhalten bleibt, und tut dies mit einer sauberen Kombination aus Masked Autoencoding, zeitlichem kontrastivem Lernen und gepoolten lokalen Merkmalen.