ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
Resumen de prensa
Investigadores de la Universidad Rice y Google DeepMind han desarrollado un sistema de aprendizaje visual autosupervisado llamado ViC-MAE que entrena a un único modelo de IA para comprender tanto imágenes fijas como video sin requerir datos etiquetados. El desafío central que abordaron es que los modelos existentes tienden a ser buenos en una modalidad o en la otra, pero no en ambas — y en particular, los modelos entrenados con video históricamente han tenido dificultades cuando se les pide un buen desempeño en tareas de imágenes. Su enfoque combina dos técnicas existentes: los masked autoencoders, que entrenan a un modelo para reconstruir parches ocultos al azar de una imagen, y el aprendizaje contrastivo, que entrena a un modelo para reconocer que dos vistas diferentes de la misma escena deberían producir representaciones similares. El giro novedoso es que, en lugar de convertir artificialmente las imágenes en videos falsos repitiendo fotogramas — una solución común —, ViC-MAE trata los fotogramas muestreados con un segundo de diferencia aproximadamente dentro de un video real como "vistas aumentadas" naturales de la misma escena, alimentando esas variaciones temporales en el objetivo de aprendizaje contrastivo mientras aún reconstruye fotogramas individuales con la pérdida de enmascaramiento. El equipo también descubrió que agrupar (pooling) las características locales de los parches en una representación global, en lugar de depender de un único token de clasificación, ayudó a evitar que el modelo colapsara durante el entrenamiento. Probado en benchmarks estándar, la versión ViT-Large de ViC-MAE alcanzó una precisión top-1 del 87,1% en ImageNet y del 75,9% en el desafiante benchmark de video Something-Something-v2, superando al método autosupervisado comparable OmniMAE por aproximadamente 2,4 puntos porcentuales en ImageNet y venciéndolo también en las tareas de video — un resultado que sugiere que los datos de video, usados con criterio, pueden fortalecer de forma significativa la comprensión de imágenes sin sacrificar el rendimiento en video.
resumen
Proponemos ViC-MAE, un modelo que combina tanto Masked AutoEncoders (MAE) como aprendizaje contrastivo. ViC-MAE se entrena usando una característica global obtenida al agrupar (pooling) las representaciones locales aprendidas bajo una pérdida de reconstrucción MAE y aprovechando esta representación bajo un objetivo contrastivo entre imágenes y fotogramas de video. Mostramos que las representaciones visuales aprendidas bajo ViC-MAE generalizan bien tanto a tareas de clasificación de video como de imágenes. En particular, ViC-MAE obtiene un rendimiento de transferencia de aprendizaje de video a imágenes en Imagenet-1k del estado del arte en comparación con el recientemente propuesto OmniMAE, al lograr una precisión top-1 del 86% (+1,3% de mejora absoluta) cuando se entrena con los mismos datos y del 87,1% (+2,4% de mejora absoluta) cuando se entrena con datos adicionales. Al mismo tiempo, ViC-MAE supera a la mayoría de los demás métodos en los benchmarks de video al obtener un 75,9% de precisión top-1 en el desafiante benchmark de video Something something-v2. Al entrenar con videos e imágenes de una combinación diversa de conjuntos de datos, nuestro método mantiene un rendimiento equilibrado de transferencia de aprendizaje entre los benchmarks de clasificación de video e imágenes, quedando solo como un cercano segundo lugar frente al mejor método supervisado.
detalles
cita
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué es ViC-MAE? ViC-MAE es un método de aprendizaje de representaciones visuales autosupervisado que combina el masked autoencoding con el aprendizaje contrastivo para que un único backbone pueda aprender características útiles tanto para imágenes como para videos.
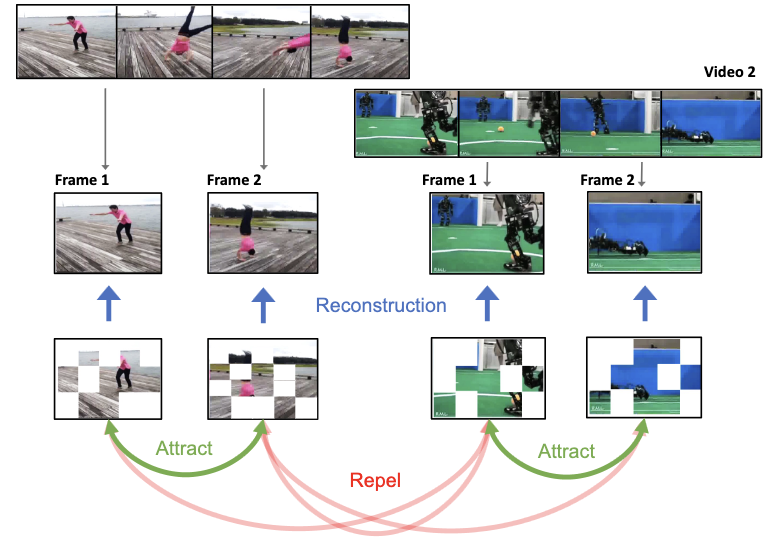
- ¿Cómo usa ViC-MAE el video de forma diferente a los métodos previos de preentrenamiento imagen-video? En lugar de convertir las imágenes en videos de fotogramas repetidos, ViC-MAE trata los fotogramas cercanos de videos reales como aumentaciones temporales naturales y alinea sus representaciones agrupadas (pooled).
- ¿Por qué combinar el modelado de imágenes enmascaradas y el aprendizaje contrastivo? El objetivo de reconstrucción fomenta características locales de parches fuertes, mientras que el objetivo contrastivo fomenta la invarianza global entre imágenes aumentadas y fotogramas de video desplazados temporalmente.
- ¿Qué papel juega el pooling en el método? ViC-MAE agrupa (pooling) las características locales de ViT en una representación global antes de la rama contrastiva, lo cual, según muestra el artículo, es importante para un entrenamiento estable y evita depender únicamente de un token de clasificación.
- ¿Qué evidencia muestra que ViC-MAE aprende representaciones equilibradas de imagen y video? El artículo reporta una fuerte transferencia a ImageNet, Kinetics-400, Places365, Something-Something-v2, varios conjuntos de datos de clasificación de imágenes posteriores, y detección y segmentación en COCO.
Contribuciones principales
- El artículo introduce un marco autosupervisado unificado que se entrena tanto a partir de imágenes como de videos usando una combinación de reconstrucción enmascarada y alineación contrastiva.
- ViC-MAE muestra que los fotogramas de video pueden servir como aumentaciones temporales eficaces para el aprendizaje de representaciones a nivel de imagen, mejorando la transferencia de video a imagen sin renunciar al rendimiento en video.
- El método identifica el pooling global sobre características locales de MAE como una decisión de diseño práctica para un entrenamiento estable de masked autoencoder contrastivo.
- Con un backbone ViT-Large, ViC-MAE alcanza un 87,1% de precisión top-1 en ImageNet y un 75,9% de precisión top-1 en Something-Something-v2, superando a líneas base autosupervisadas comparables como OmniMAE en los escenarios reportados.
- El artículo proporciona una amplia validación empírica en clasificación de imágenes, reconocimiento de acciones en video, detección de objetos y segmentación, lo que hace que la contribución sea útil más allá de un único benchmark.
Limitaciones y advertencias
- Los resultados más fuertes usan grandes backbones ViT y preentrenamiento con múltiples conjuntos de datos, lo cual es típico del aprendizaje moderno de representaciones visuales estilo modelo fundacional y ayuda a mostrar el comportamiento de escalado del método.
- ViC-MAE se evalúa principalmente mediante benchmarks de transferencia y ajuste fino en lugar de en todas las posibles tareas de video o imagen posteriores, dejando dominios adicionales como evaluaciones de seguimiento prometedoras.
- El enfoque depende de un cuidadoso equilibrio entre los objetivos de reconstrucción y contrastivo, pero el artículo incluye ablaciones sobre pooling, separación de fotogramas, aumentaciones y mezcla de datos que dejan claras las decisiones de diseño.
- El método mejora la autosupervisión unificada de imagen-video, mientras que los modelos supervisados específicos de tarea aún pueden ser competitivos en algunos benchmarks individuales; esto enmarca a ViC-MAE como un fuerte aprendiz de representaciones generales en lugar de un especialista limitado.
- El artículo se centra en el preentrenamiento únicamente visual, por lo que las extensiones a texto, audio o una alineación multimodal más amplia siguen siendo oportunidades naturales que se construyen sobre el mismo marco.
Cómo interpretar este resultado
Este artículo se lee mejor como un avance sólido y práctico en el aprendizaje autosupervisado de representaciones de imagen y video: ViC-MAE demuestra que los datos de video pueden mejorar las representaciones de imágenes preservando un excelente rendimiento en video, y lo hace con una combinación limpia de masked autoencoding, aprendizaje contrastivo temporal y características locales agrupadas (pooled).