ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
Краткое изложение пресс-релиза
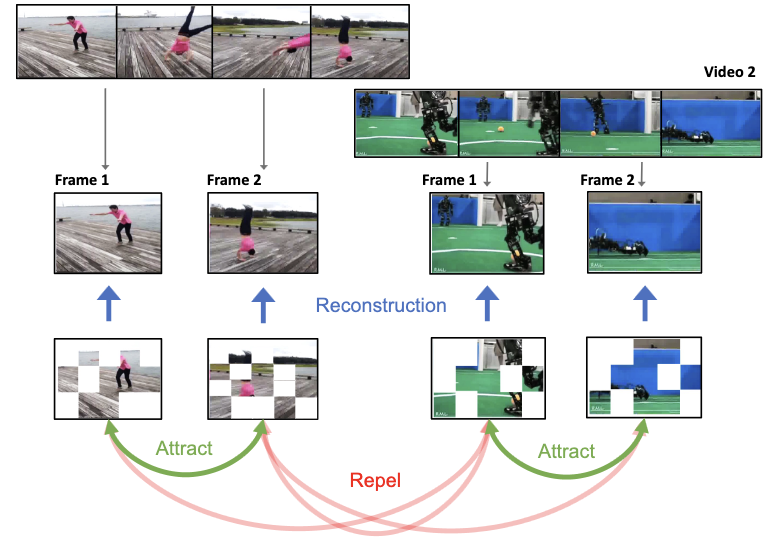
Исследователи из Rice University и Google DeepMind разработали систему самообучения для визуальных представлений под названием ViC-MAE, которая обучает единую модель ИИ понимать как неподвижные изображения, так и видео, не требуя размеченных данных. Основная проблема, которую они решали, заключается в том, что существующие модели обычно хороши в одной модальности или другой, но не в обеих — и в частности, модели, обученные на видео, исторически испытывали трудности, когда от них требовалось хорошо работать на задачах с изображениями. Их подход объединяет две существующие техники: masked autoencoders, которые обучают модель реконструировать случайно скрытые участки изображения, и Contrastive Learning, который обучает модель распознавать, что два разных вида одной и той же сцены должны давать похожие представления. Новый поворот состоит в том, что вместо искусственного преобразования изображений в фальшивые видео путём повторения кадров — распространённый обходной приём — ViC-MAE рассматривает кадры, взятые с интервалом примерно в секунду внутри реального видео, как естественные "аугментированные виды" одной и той же сцены, подавая эти временные вариации в контрастивную целевую функцию, при этом всё ещё реконструируя отдельные кадры с помощью потери маскирования. Команда также обнаружила, что пулинг локальных признаков участков в глобальное представление, а не опора на единственный классификационный токен, помог предотвратить коллапс модели во время обучения. При тестировании на стандартных бенчмарках версия ViC-MAE на основе ViT-Large достигла 87.1% top-1 точности на ImageNet и 75.9% на сложном видео-бенчмарке Something-Something-v2, превзойдя сопоставимый метод самообучения OmniMAE примерно на 2.4 процентных пункта на ImageNet, а также обойдя его на видео-задачах — результат, который указывает на то, что видеоданные, используемые продуманно, могут существенно усилить понимание изображений без ущерба для производительности на видео.
аннотация
Мы предлагаем ViC-MAE — модель, которая объединяет Masked AutoEncoders (MAE) и Contrastive Learning. ViC-MAE обучается с использованием глобального признака, получаемого путём пулинга локальных представлений, выученных под потерей реконструкции MAE, и применения этого представления под контрастивной целевой функцией по изображениям и кадрам видео. Мы показываем, что визуальные представления, выученные с помощью ViC-MAE, хорошо обобщаются как на задачи классификации видео, так и изображений. В частности, ViC-MAE достигает результатов Transfer Learning на современном уровне при переносе с видео на изображения на Imagenet-1k по сравнению с недавно предложенной OmniMAE, достигая top-1 точности 86% (+1.3% абсолютного улучшения) при обучении на тех же данных и 87.1% (+2.4% абсолютного улучшения) при обучении на дополнительных данных. В то же время ViC-MAE превосходит большинство других методов на видео-бенчмарках, достигая 75.9% top-1 точности на сложном видео-бенчмарке Something something-v2. При обучении на видео и изображениях из разнообразной комбинации наборов данных наш метод сохраняет сбалансированную производительность Transfer Learning между бенчмарками классификации видео и изображений, уступая лишь немного лучшему методу с учителем.
подробности
цитирование
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Что такое ViC-MAE? ViC-MAE — это метод самообучения визуальных представлений (Self-Supervised Learning), который объединяет masked autoencoding с Contrastive Learning, чтобы один бэкбон мог выучить полезные признаки как для изображений, так и для видео.
- Как ViC-MAE использует видео иначе, чем предыдущие методы предобучения на изображениях и видео? Вместо преобразования изображений в видео с повторяющимися кадрами ViC-MAE рассматривает соседние кадры из реальных видео как естественные временные аугментации и выравнивает их пулинговые представления.
- Зачем объединять masked image modeling и Contrastive Learning? Целевая функция реконструкции поощряет сильные локальные признаки участков, тогда как контрастивная целевая функция поощряет глобальную инвариантность между аугментированными изображениями и временно сдвинутыми кадрами видео.
- Какую роль играет пулинг в методе? ViC-MAE пулит локальные признаки ViT в глобальное представление перед контрастивной ветвью, что, как показывает статья, важно для стабильного обучения и позволяет не полагаться только на классификационный токен.
- Какие данные показывают, что ViC-MAE выучивает сбалансированные представления изображений и видео? В статье сообщается о сильном переносе на ImageNet, Kinetics-400, Places365, Something-Something-v2, несколько целевых наборов данных классификации изображений, а также на детекцию и сегментацию COCO.
Основные вклады
- В статье представлен единый фреймворк самообучения (Self-Supervised Learning), который обучается как на изображениях, так и на видео, используя комбинацию masked-реконструкции и контрастивного выравнивания.
- ViC-MAE показывает, что кадры видео могут служить эффективными временными аугментациями для обучения представлений на уровне изображений, улучшая перенос с видео на изображения без потери производительности на видео.
- Метод определяет глобальный пулинг по локальным признакам MAE как практичное архитектурное решение для стабильного обучения контрастивного masked autoencoder.
- С бэкбоном ViT-Large ViC-MAE достигает 87.1% top-1 точности на ImageNet и 75.9% top-1 точности на Something-Something-v2, превосходя сопоставимые базовые модели самообучения, такие как OmniMAE, в указанных настройках.
- Статья предоставляет обширную эмпирическую валидацию по классификации изображений, распознаванию действий на видео, детекции объектов и сегментации, что делает вклад полезным не только для одного бенчмарка.
Ограничения и предостережения
- Наиболее сильные результаты используют большие бэкбоны ViT и предобучение на нескольких наборах данных, что типично для современного обучения визуальных представлений в стиле фундаментальных моделей и помогает показать масштабируемость метода.
- ViC-MAE оценивается главным образом через бенчмарки переноса и дообучения, а не через каждую возможную целевую задачу для видео или изображений, оставляя дополнительные домены в качестве перспективных последующих оценок.
- Подход зависит от тщательного баланса между целевыми функциями реконструкции и контрастивного обучения, но статья включает абляции по пулингу, разделению кадров, аугментациям и составу данных, которые проясняют архитектурные решения.
- Метод улучшает единое самообучение по изображениям и видео, тогда как специализированные модели с учителем по-прежнему могут быть конкурентоспособны на некоторых отдельных бенчмарках; это позиционирует ViC-MAE как сильную модель общих представлений, а не узкого специалиста.
- Статья сосредоточена на чисто визуальном предобучении, поэтому расширения на текст, аудио или более широкое мультимодальное выравнивание остаются естественными возможностями, развивающими тот же фреймворк.
Как интерпретировать этот результат
Эту статью лучше всего воспринимать как сильное и практичное продвижение в самообучении представлений по изображениям и видео: ViC-MAE демонстрирует, что видеоданные могут улучшать представления изображений, сохраняя при этом отличную производительность на видео, и делает это с помощью чистой комбинации masked autoencoding, временного Contrastive Learning и пулинговых локальных признаков.