ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
Sintesi del comunicato stampa
I ricercatori della Rice University e di Google DeepMind hanno sviluppato un sistema di apprendimento visivo auto-supervisionato chiamato ViC-MAE che addestra un singolo modello di IA a comprendere sia le immagini fisse sia i video senza richiedere dati etichettati. La sfida principale che hanno affrontato è che i modelli esistenti tendono a essere bravi in una modalità o nell'altra, ma non in entrambe, e in particolare i modelli addestrati su video hanno storicamente avuto difficoltà quando è stato loro chiesto di ottenere buone prestazioni su task di immagini. Il loro approccio combina due tecniche esistenti: i masked autoencoder, che addestrano un modello a ricostruire patch nascoste casualmente di un'immagine, e il contrastive learning, che addestra un modello a riconoscere che due viste diverse della stessa scena dovrebbero produrre rappresentazioni simili. L'innovazione consiste nel fatto che, invece di convertire artificialmente le immagini in finti video ripetendo i frame, una soluzione comunemente adottata, ViC-MAE tratta i frame campionati a circa un secondo di distanza all'interno di un video reale come naturali "viste aumentate" della stessa scena, immettendo queste variazioni temporali nell'obiettivo di contrastive learning pur ricostruendo i singoli frame con la loss di masking. Il team ha inoltre scoperto che il pooling delle feature locali delle patch in una rappresentazione globale, anziché affidarsi a un singolo classification token, ha contribuito a evitare il collasso del modello durante l'addestramento. Testata su benchmark standard, la versione ViT-Large di ViC-MAE ha raggiunto un'accuratezza top-1 dell'87.1% su ImageNet e del 75.9% sull'impegnativo benchmark video Something-Something-v2, superando il metodo auto-supervisionato comparabile OmniMAE di circa 2.4 punti percentuali su ImageNet e battendolo anche nei task video, un risultato che suggerisce che i dati video, usati in modo accorto, possono rafforzare in modo significativo la comprensione delle immagini senza sacrificare le prestazioni sui video.
abstract
Proponiamo ViC-MAE, un modello che combina sia i Masked AutoEncoders (MAE) sia il contrastive learning. ViC-MAE viene addestrato utilizzando una feature globale ottenuta mediante pooling delle rappresentazioni locali apprese con una loss di ricostruzione MAE e sfruttando questa rappresentazione con un obiettivo contrastive su immagini e frame video. Mostriamo che le rappresentazioni visive apprese con ViC-MAE generalizzano bene sia ai task di classificazione video sia a quelli di immagini. In particolare, ViC-MAE ottiene prestazioni di transfer learning allo stato dell'arte da video a immagini su Imagenet-1k rispetto al recentemente proposto OmniMAE, raggiungendo un'accuratezza top-1 dell'86% (+1.3% di miglioramento assoluto) quando addestrato sugli stessi dati e dell'87.1% (+2.4% di miglioramento assoluto) quando addestrato su dati aggiuntivi. Allo stesso tempo ViC-MAE supera la maggior parte degli altri metodi sui benchmark video ottenendo un'accuratezza top-1 del 75.9% sull'impegnativo benchmark video Something something-v2. Quando addestrato su video e immagini provenienti da una combinazione diversificata di dataset, il nostro metodo mantiene prestazioni di transfer learning bilanciate tra i benchmark di classificazione video e di immagini, posizionandosi solo come secondo di stretta misura rispetto al miglior metodo supervisionato.
dettagli
citazione
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Che cos'è ViC-MAE? ViC-MAE è un metodo di apprendimento auto-supervisionato di rappresentazioni visive che combina il masked autoencoding con il contrastive learning in modo che un unico backbone possa apprendere feature utili sia per le immagini sia per i video.
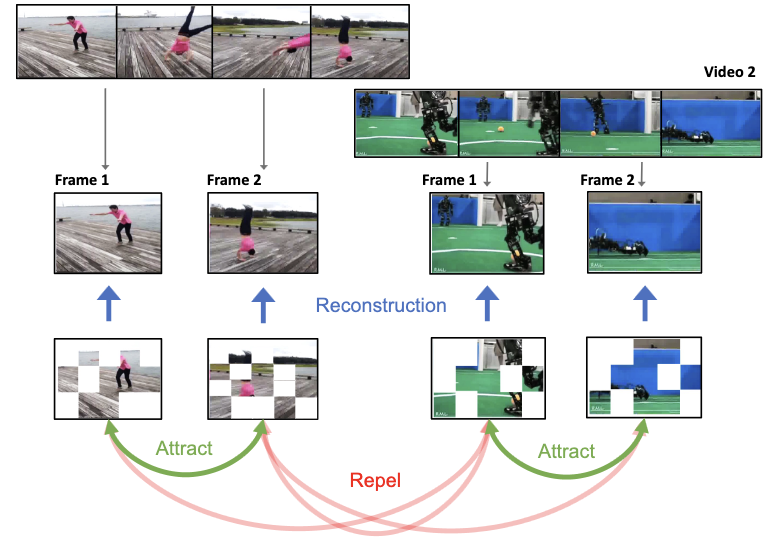
- In che modo ViC-MAE utilizza il video in modo diverso rispetto ai precedenti metodi di pretraining immagine-video? Invece di convertire le immagini in video a frame ripetuti, ViC-MAE tratta i frame vicini provenienti da video reali come naturali augmentation temporali e allinea le loro rappresentazioni ottenute mediante pooling.
- Perché combinare il masked image modeling e il contrastive learning? L'obiettivo di ricostruzione incoraggia feature locali delle patch robuste, mentre l'obiettivo contrastive incoraggia l'invarianza globale tra immagini aumentate e frame video spostati temporalmente.
- Quale ruolo svolge il pooling nel metodo? ViC-MAE esegue il pooling delle feature locali ViT in una rappresentazione globale prima del ramo contrastive, cosa che il paper dimostra essere importante per un addestramento stabile ed evita di affidarsi solo a un classification token.
- Quali prove dimostrano che ViC-MAE apprende rappresentazioni bilanciate di immagini e video? Il paper riporta un forte transfer verso ImageNet, Kinetics-400, Places365, Something-Something-v2, diversi dataset di classificazione di immagini a valle, e detection e segmentation su COCO.
Principali contributi
- Il paper introduce un framework auto-supervisionato unificato che si addestra sia da immagini sia da video utilizzando una combinazione di ricostruzione mascherata e allineamento contrastive.
- ViC-MAE mostra che i frame video possono fungere da efficaci augmentation temporali per l'apprendimento di rappresentazioni a livello di immagine, migliorando il transfer da video a immagini senza rinunciare alle prestazioni sui video.
- Il metodo individua il pooling globale sulle feature locali MAE come scelta progettuale pratica per un addestramento stabile del contrastive masked autoencoder.
- Con un backbone ViT-Large, ViC-MAE raggiunge un'accuratezza top-1 dell'87.1% su ImageNet e del 75.9% su Something-Something-v2, superando baseline auto-supervisionate comparabili come OmniMAE nelle configurazioni riportate.
- Il paper fornisce un'ampia validazione empirica su classificazione di immagini, riconoscimento di azioni video, object detection e segmentation, rendendo il contributo utile al di là di un singolo benchmark.
Limiti e avvertenze
- I risultati migliori utilizzano backbone ViT di grandi dimensioni e pretraining su più dataset, cosa tipica del moderno apprendimento di rappresentazioni visive in stile foundation e utile a mostrare il comportamento di scaling del metodo.
- ViC-MAE viene valutato principalmente attraverso benchmark di transfer e fine-tuning anziché su ogni possibile task video o di immagini a valle, lasciando ulteriori domini come promettenti valutazioni successive.
- L'approccio dipende da un attento equilibrio tra gli obiettivi di ricostruzione e contrastive, ma il paper include ablation su pooling, separazione dei frame, augmentation e mix di dati che chiariscono le scelte progettuali.
- Il metodo migliora l'auto-supervisione unificata immagine-video, mentre i modelli supervisionati specifici per un task possono ancora essere competitivi su alcuni singoli benchmark; ciò inquadra ViC-MAE come un solido apprenditore generale di rappresentazioni piuttosto che come uno specialista ristretto.
- Il paper si concentra sul pretraining puramente visivo, quindi le estensioni a testo, audio o a un allineamento multimodale più ampio rimangono opportunità naturali a partire dallo stesso framework.
Come interpretare questo risultato
Questo paper si legge al meglio come un avanzamento solido e pratico nell'apprendimento auto-supervisionato di rappresentazioni immagine-video: ViC-MAE dimostra che i dati video possono migliorare le rappresentazioni delle immagini preservando al contempo eccellenti prestazioni sui video, e lo fa con una pulita combinazione di masked autoencoding, contrastive learning temporale e feature locali aggregate mediante pooling.