ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
Tóm tắt thông cáo báo chí
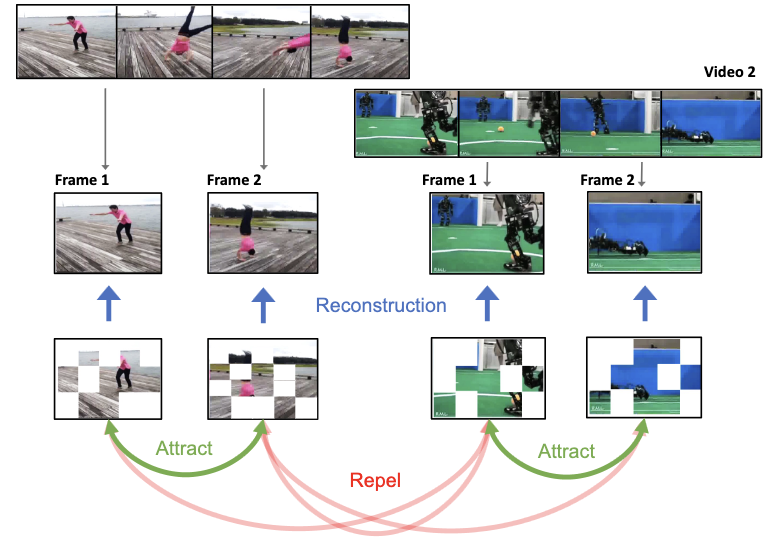
Các nhà nghiên cứu tại Rice University và Google DeepMind đã phát triển một hệ thống học thị giác tự giám sát tên là ViC-MAE, huấn luyện một mô hình AI đơn lẻ để hiểu cả ảnh tĩnh và video mà không cần dữ liệu được gán nhãn. Thách thức cốt lõi mà họ giải quyết là các mô hình hiện có thường giỏi ở một phương thức này hoặc phương thức kia, nhưng không cả hai — và đặc biệt, các mô hình được huấn luyện trên video trước đây vốn gặp khó khăn khi được yêu cầu thực hiện tốt các tác vụ về ảnh. Cách tiếp cận của họ kết hợp hai kỹ thuật hiện có: masked autoencoders, vốn huấn luyện một mô hình tái tạo các mảng (patch) bị ẩn ngẫu nhiên của một ảnh, và Contrastive Learning, vốn huấn luyện một mô hình nhận ra rằng hai góc nhìn khác nhau của cùng một cảnh nên tạo ra các biểu diễn tương tự nhau. Điểm mới mẻ là thay vì biến đổi nhân tạo ảnh thành các video giả bằng cách lặp lại khung hình — một giải pháp thay thế phổ biến — ViC-MAE xử lý các khung hình được lấy mẫu cách nhau khoảng một giây trong một video thực tế như những "góc nhìn được tăng cường" tự nhiên của cùng một cảnh, đưa các biến thể thời gian đó vào mục tiêu Contrastive Learning trong khi vẫn tái tạo từng khung hình riêng lẻ bằng hàm mất mát che mặt nạ. Nhóm nghiên cứu cũng nhận thấy rằng việc gộp các đặc trưng mảng cục bộ thành một biểu diễn toàn cục, thay vì dựa vào một token phân loại đơn lẻ, giúp ngăn mô hình sụp đổ trong quá trình huấn luyện. Khi thử nghiệm trên các benchmark tiêu chuẩn, phiên bản ViT-Large của ViC-MAE đạt độ chính xác top-1 87,1% trên ImageNet và 75,9% trên benchmark video Something-Something-v2 đầy thách thức, vượt trội hơn phương pháp tự giám sát tương đương OmniMAE khoảng 2,4 điểm phần trăm trên ImageNet trong khi cũng đánh bại nó ở các tác vụ video — một kết quả cho thấy dữ liệu video, nếu được sử dụng một cách thấu đáo, có thể củng cố đáng kể việc hiểu ảnh mà không hy sinh hiệu năng video.
tóm tắt
Chúng tôi đề xuất ViC-MAE, một mô hình kết hợp cả Masked AutoEncoders (MAE) và Contrastive Learning. ViC-MAE được huấn luyện bằng một đặc trưng toàn cục thu được qua việc gộp (pooling) các biểu diễn cục bộ học được dưới một hàm mất mát tái tạo MAE và tận dụng biểu diễn này dưới một mục tiêu tương phản trên các ảnh và các khung hình video. Chúng tôi chứng minh rằng các biểu diễn thị giác học được dưới ViC-MAE tổng quát hóa tốt cho cả tác vụ phân loại video và ảnh. Đặc biệt, ViC-MAE đạt hiệu năng Transfer Learning tốt nhất hiện nay từ video sang ảnh trên Imagenet-1k so với OmniMAE được đề xuất gần đây, bằng cách đạt độ chính xác top-1 86% (+1,3% cải thiện tuyệt đối) khi được huấn luyện trên cùng dữ liệu và 87,1% (+2,4% cải thiện tuyệt đối) khi huấn luyện trên dữ liệu bổ sung. Đồng thời, ViC-MAE vượt trội hơn hầu hết các phương pháp khác trên các benchmark video bằng cách đạt độ chính xác top-1 75,9% trên benchmark video Something something-v2 đầy thách thức. Khi huấn luyện trên video và ảnh từ một tổ hợp đa dạng các bộ dữ liệu, phương pháp của chúng tôi duy trì hiệu năng Transfer Learning cân bằng giữa các benchmark phân loại video và ảnh, chỉ về nhì sát nút sau phương pháp có giám sát tốt nhất.
chi tiết
trích dẫn
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
câu hỏi, đóng góp chính và hạn chế của bài báo này được tạo tự động
Câu hỏi mà bài báo này giúp trả lời
- ViC-MAE là gì? ViC-MAE là một phương pháp học biểu diễn thị giác tự giám sát kết hợp masked autoencoding với Contrastive Learning để một backbone duy nhất có thể học các đặc trưng hữu ích cho cả ảnh và video.
- ViC-MAE sử dụng video khác với các phương pháp tiền huấn luyện ảnh-video trước đây như thế nào? Thay vì biến đổi ảnh thành các video khung hình lặp lại, ViC-MAE xử lý các khung hình lân cận từ video thực tế như các phép tăng cường thời gian tự nhiên và căn chỉnh các biểu diễn đã được gộp của chúng.
- Tại sao kết hợp masked image modeling và Contrastive Learning? Mục tiêu tái tạo khuyến khích các đặc trưng mảng cục bộ mạnh, trong khi mục tiêu tương phản khuyến khích tính bất biến toàn cục trên các ảnh được tăng cường và các khung hình video bị dịch chuyển theo thời gian.
- Việc gộp (pooling) đóng vai trò gì trong phương pháp? ViC-MAE gộp các đặc trưng ViT cục bộ thành một biểu diễn toàn cục trước nhánh tương phản, điều mà bài báo cho thấy là quan trọng cho việc huấn luyện ổn định và tránh chỉ dựa vào một token phân loại.
- Bằng chứng nào cho thấy ViC-MAE học được các biểu diễn ảnh và video cân bằng? Bài báo ghi nhận khả năng chuyển giao mạnh mẽ sang ImageNet, Kinetics-400, Places365, Something-Something-v2, một số bộ dữ liệu phân loại ảnh hạ nguồn, cùng với phát hiện và phân đoạn trên COCO.
Đóng góp chính
- Bài báo giới thiệu một framework tự giám sát hợp nhất, huấn luyện từ cả ảnh và video bằng cách kết hợp tái tạo che mặt nạ và căn chỉnh tương phản.
- ViC-MAE cho thấy rằng các khung hình video có thể đóng vai trò là các phép tăng cường thời gian hiệu quả cho việc học biểu diễn ở cấp độ ảnh, cải thiện khả năng chuyển giao video-sang-ảnh mà không từ bỏ hiệu năng video.
- Phương pháp xác định việc gộp toàn cục trên các đặc trưng MAE cục bộ là một lựa chọn thiết kế thực tế cho việc huấn luyện contrastive masked autoencoder ổn định.
- Với một backbone ViT-Large, ViC-MAE đạt độ chính xác top-1 87,1% trên ImageNet và 75,9% top-1 trên Something-Something-v2, vượt trội hơn các baseline tự giám sát tương đương như OmniMAE trong các cấu hình được báo cáo.
- Bài báo cung cấp sự kiểm chứng thực nghiệm rộng rãi trên phân loại ảnh, nhận dạng hành động video, phát hiện đối tượng và phân đoạn, khiến đóng góp này hữu ích vượt ra ngoài một benchmark đơn lẻ.
Hạn chế và lưu ý
- Các kết quả mạnh nhất sử dụng các backbone ViT lớn và tiền huấn luyện đa bộ dữ liệu, điều này là điển hình cho việc học biểu diễn thị giác kiểu nền tảng hiện đại và giúp thể hiện hành vi mở rộng quy mô của phương pháp.
- ViC-MAE chủ yếu được đánh giá thông qua các benchmark chuyển giao và tinh chỉnh thay vì mọi tác vụ video hoặc ảnh hạ nguồn có thể có, để lại các miền bổ sung như những đánh giá tiếp nối đầy hứa hẹn.
- Cách tiếp cận phụ thuộc vào một sự cân bằng cẩn thận giữa các mục tiêu tái tạo và tương phản, nhưng bài báo bao gồm các phân tích loại bỏ (ablation) về việc gộp, khoảng cách khung hình, các phép tăng cường và tổ hợp dữ liệu, giúp làm rõ các lựa chọn thiết kế.
- Phương pháp cải thiện việc tự giám sát ảnh-video hợp nhất, trong khi các mô hình có giám sát theo tác vụ cụ thể vẫn có thể cạnh tranh trên một số benchmark riêng lẻ; điều này định khung ViC-MAE như một bộ học biểu diễn tổng quát mạnh mẽ thay vì một chuyên gia hẹp.
- Bài báo tập trung vào tiền huấn luyện chỉ-thị-giác, vì vậy các phần mở rộng sang văn bản, âm thanh, hoặc căn chỉnh đa phương thức rộng hơn vẫn là những cơ hội tự nhiên xây dựng trên cùng framework này.
Cách diễn giải kết quả này
Bài báo này nên được đọc như một bước tiến mạnh mẽ và thực tiễn trong việc học biểu diễn ảnh-video tự giám sát: ViC-MAE chứng minh rằng dữ liệu video có thể cải thiện các biểu diễn ảnh trong khi vẫn giữ được hiệu năng video xuất sắc, và nó làm được điều đó với một sự kết hợp gọn gàng giữa masked autoencoding, Contrastive Learning theo thời gian, và các đặc trưng cục bộ đã được gộp.