ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders
Résumé du communiqué de presse
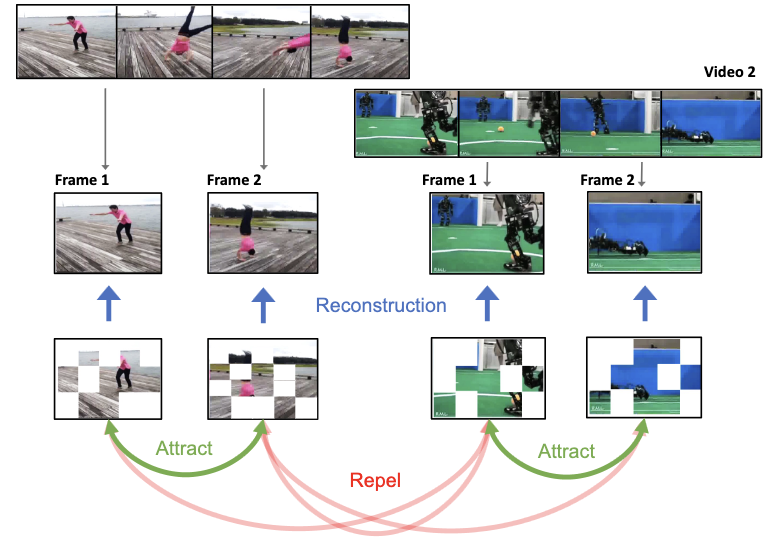
Des chercheurs de Rice University et de Google DeepMind ont mis au point un système d'apprentissage visuel auto-supervisé appelé ViC-MAE qui entraîne un seul modèle d'IA à comprendre à la fois les images fixes et la vidéo sans nécessiter de données étiquetées. Le défi central qu'ils ont relevé est que les modèles existants ont tendance à être bons dans une modalité ou l'autre, mais pas dans les deux — et en particulier, les modèles entraînés sur la vidéo ont historiquement eu du mal lorsqu'on leur demandait de bien performer sur des tâches d'images. Leur approche combine deux techniques existantes : les auto-encodeurs masqués, qui entraînent un modèle à reconstruire des fragments d'image masqués aléatoirement, et l'apprentissage contrastif, qui entraîne un modèle à reconnaître que deux vues différentes d'une même scène devraient produire des représentations similaires. La nouveauté est qu'au lieu de convertir artificiellement des images en fausses vidéos en répétant des trames — une solution de contournement courante — ViC-MAE traite les trames échantillonnées à environ une seconde d'intervalle au sein d'une vraie vidéo comme des « vues augmentées » naturelles de la même scène, en injectant ces variations temporelles dans l'objectif d'apprentissage contrastif tout en reconstruisant les trames individuelles avec la perte de masquage. L'équipe a également constaté que l'agrégation des caractéristiques locales de fragments en une représentation globale, plutôt que de s'appuyer sur un unique jeton de classification, aidait à empêcher le modèle de s'effondrer durant l'entraînement. Testée sur des bancs d'essai standard, la version ViT-Large de ViC-MAE a atteint une précision top-1 de 87,1% sur ImageNet et de 75,9% sur le difficile banc d'essai vidéo Something-Something-v2, surpassant la méthode auto-supervisée comparable OmniMAE d'environ 2,4 points de pourcentage sur ImageNet tout en la dépassant aussi sur les tâches vidéo — un résultat qui suggère que les données vidéo, utilisées judicieusement, peuvent renforcer de manière significative la compréhension des images sans sacrifier les performances vidéo.
résumé
Nous proposons ViC-MAE, un modèle qui combine à la fois les auto-encodeurs masqués (Masked AutoEncoders, MAE) et l'apprentissage contrastif. ViC-MAE est entraîné à l'aide d'une caractéristique globale obtenue en agrégeant les représentations locales apprises sous une perte de reconstruction MAE et en exploitant cette représentation sous un objectif contrastif à travers les images et les trames vidéo. Nous montrons que les représentations visuelles apprises sous ViC-MAE se généralisent bien aux tâches de classification de vidéos comme d'images. En particulier, ViC-MAE obtient des performances de transfert d'apprentissage de pointe de la vidéo vers les images sur Imagenet-1k par rapport à OmniMAE récemment proposé, en atteignant une précision top-1 de 86% (+1,3% d'amélioration absolue) lorsqu'il est entraîné sur les mêmes données et de 87,1% (+2,4% d'amélioration absolue) lorsqu'il est entraîné sur des données supplémentaires. Dans le même temps, ViC-MAE surpasse la plupart des autres méthodes sur les bancs d'essai vidéo en obtenant une précision top-1 de 75,9% sur le difficile banc d'essai vidéo Something something-v2. Lors d'un entraînement sur des vidéos et des images issues d'une combinaison diversifiée de jeux de données, notre méthode maintient une performance de transfert d'apprentissage équilibrée entre les bancs d'essai de classification de vidéos et d'images, n'arrivant qu'à une courte deuxième place derrière la meilleure méthode supervisée.
détails
citation
@inproceedings{hernandez2024vic,
title = {ViC-MAE: Self-Supervised Representation Learning from Images and Video with Contrastive Masked Autoencoders},
author = {Hernandez, Jefferson and Villegas, Ruben and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2303.12001},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Qu'est-ce que ViC-MAE ? ViC-MAE est une méthode d'apprentissage auto-supervisé de représentations visuelles qui combine l'auto-encodage masqué et l'apprentissage contrastif afin qu'une seule architecture puisse apprendre des caractéristiques utiles à la fois pour les images et les vidéos.
- En quoi ViC-MAE utilise-t-il la vidéo différemment des méthodes antérieures de pré-entraînement image-vidéo ? Au lieu de convertir les images en vidéos à trames répétées, ViC-MAE traite les trames voisines de vraies vidéos comme des augmentations temporelles naturelles et aligne leurs représentations agrégées.
- Pourquoi combiner la modélisation d'images masquées et l'apprentissage contrastif ? L'objectif de reconstruction favorise de fortes caractéristiques locales de fragments, tandis que l'objectif contrastif favorise l'invariance globale entre images augmentées et trames vidéo décalées temporellement.
- Quel rôle joue l'agrégation dans la méthode ? ViC-MAE agrège les caractéristiques locales du ViT en une représentation globale avant la branche contrastive, ce que l'article montre être important pour un entraînement stable et évite de s'appuyer uniquement sur un jeton de classification.
- Quelles preuves montrent que ViC-MAE apprend des représentations équilibrées d'images et de vidéos ? L'article rapporte un fort transfert vers ImageNet, Kinetics-400, Places365, Something-Something-v2, plusieurs jeux de données de classification d'images en aval, ainsi que la détection et la segmentation sur COCO.
Principales contributions
- L'article introduit un cadre auto-supervisé unifié qui s'entraîne à la fois à partir d'images et de vidéos en combinant reconstruction masquée et alignement contrastif.
- ViC-MAE montre que les trames vidéo peuvent servir d'augmentations temporelles efficaces pour l'apprentissage de représentations au niveau de l'image, améliorant le transfert vidéo-vers-image sans renoncer aux performances vidéo.
- La méthode identifie l'agrégation globale des caractéristiques locales de MAE comme un choix de conception pratique pour un entraînement stable d'auto-encodeur masqué contrastif.
- Avec une architecture ViT-Large, ViC-MAE atteint une précision top-1 de 87,1% sur ImageNet et de 75,9% sur Something-Something-v2, surpassant des méthodes auto-supervisées comparables telles qu'OmniMAE dans les configurations rapportées.
- L'article fournit une large validation empirique sur la classification d'images, la reconnaissance d'actions vidéo, la détection d'objets et la segmentation, rendant la contribution utile au-delà d'un seul banc d'essai.
Limites et mises en garde
- Les meilleurs résultats utilisent de grandes architectures ViT et un pré-entraînement multi-jeux de données, ce qui est typique de l'apprentissage moderne de représentations visuelles de type fondation et aide à montrer le comportement de la méthode en matière de passage à l'échelle.
- ViC-MAE est principalement évalué au moyen de bancs d'essai de transfert et d'affinage plutôt que sur toutes les tâches vidéo ou image possibles en aval, laissant d'autres domaines comme évaluations de suivi prometteuses.
- L'approche dépend d'un équilibre soigneux entre les objectifs de reconstruction et de contraste, mais l'article comprend des études d'ablation sur l'agrégation, la séparation des trames, les augmentations et le mélange des données qui clarifient les choix de conception.
- La méthode améliore l'auto-supervision unifiée image-vidéo, tandis que des modèles supervisés spécifiques à une tâche peuvent encore être compétitifs sur certains bancs d'essai individuels ; cela positionne ViC-MAE comme un solide apprenant de représentations généralistes plutôt que comme un spécialiste étroit.
- L'article se concentre sur le pré-entraînement uniquement visuel, de sorte que les extensions au texte, à l'audio ou à un alignement multimodal plus large restent des opportunités naturelles s'appuyant sur le même cadre.
Comment interpréter ce résultat
Cet article se lit au mieux comme une avancée solide et pratique dans l'apprentissage auto-supervisé de représentations image-vidéo : ViC-MAE démontre que les données vidéo peuvent améliorer les représentations d'images tout en préservant d'excellentes performances vidéo, et il le fait grâce à une combinaison soignée d'auto-encodage masqué, d'apprentissage contrastif temporel et de caractéristiques locales agrégées.