ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
Zusammenfassung der Pressemitteilung
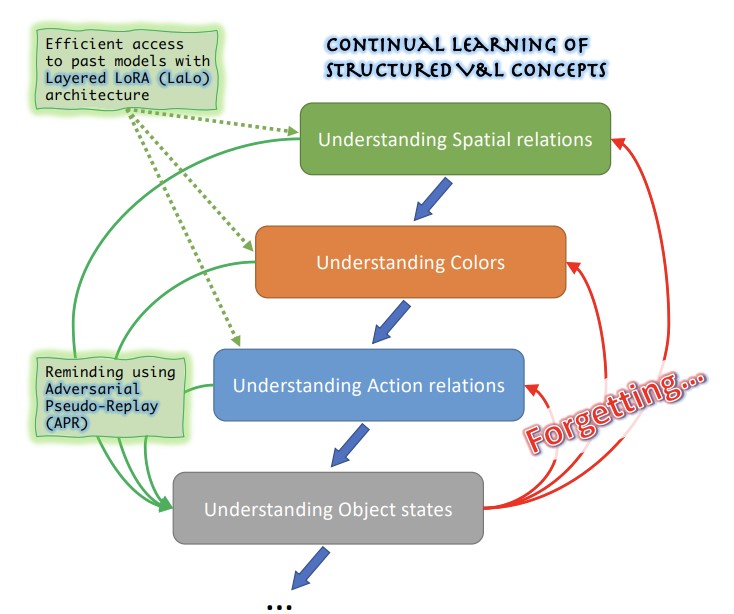
Forschende des MIT-IBM Watson AI Lab, von Georgia Tech, der Rice University, von IBM Research und Stanford haben sich einem praktischen, aber wenig erforschten Problem großer Vision-and-Language-KI-Modelle gewidmet: Diese Systeme tun sich tendenziell schwer damit, nuancierte relationale und beschreibende Konzepte zu verstehen – etwa Objektfarben, -größen, räumliche Positionen und Zustände –, und wenn Ingenieure versuchen, eine solche Schwäche durch Feintuning des Modells auf neuen Daten zu beheben, neigt das Modell dazu, zu vergessen, wie es zuvor korrigierte Schwächen behandeln sollte, ein Phänomen, das als katastrophales Vergessen bekannt ist. Die Lage wird dadurch erschwert, dass die Daten, mit denen jedes Problem identifiziert und behoben wird, oft privat sind und über Trainingsrunden hinweg nicht aufbewahrt oder wiederverwendet werden können. Um dem zu begegnen, schuf das Team ConStruct-VL, den ersten Benchmark, der eigens dafür konzipiert ist, das kontinuierliche Lernen dieser strukturierten Vision-Language-Konzepte ohne Zugriff auf frühere Aufgabendaten und ohne jeglichen Hinweis zur Testzeit darauf, welche Art von Konzept ausgewertet wird, zu evaluieren. Sie entwickelten außerdem zwei einander ergänzende technische Beiträge: eine Layered-LoRA-Architektur (LaLo), die für jede neue Aufgabe leichtgewichtige Adapter-Module mit niedrigem Rang auf ein eingefrorenes Basismodell stapelt und es dem System so ermöglicht, während des Trainings effizient auf das Modell jeder vorherigen Aufgabe zuzugreifen, ohne die Gewichte neu zu laden; und eine Methode des Adversarial Pseudo-Replay (APR), die jene vergangenen Modelle nutzt, um knifflige negative Trainingsbeispiele zu erzeugen – etwa indem eine Textbeschreibung subtil so verändert wird, dass sie ein Farbwort enthält, das nicht zum gepaarten Bild passt –, die dann verwendet werden, um das aktuelle Modell an das zuvor Gelernte zu erinnern. Getestet auf dem Vision-Language-Modell BLIP über mehrere Aufgabensequenzen hinweg, die aus den Datensätzen Visual Genome und Visual Attributes in the Wild stammen, reduzierte der kombinierte Ansatz das durchschnittliche Vergessen um etwa das Fünffache und verbesserte die finale Genauigkeit um bis zu 6,8 Prozentpunkte im Vergleich zu den besten konkurrierenden datenfreien Methoden des kontinuierlichen Lernens, wobei nur etwa 2,8 Prozent der Parameter des vollständigen Modells verwendet wurden – Ergebnisse, die deshalb bedeutsam sind, weil sie einen gangbaren Weg aufzeigen, KI-Modelle in datenschutzsensiblen realen Einsätzen kontinuierlich zu verbessern, ohne frühere Verbesserungen zu beeinträchtigen.
Zusammenfassung
In jüngster Zeit haben großmaßstäblich vortrainierte Vision-and-Language-Foundation-Modelle (VL) bemerkenswerte Fähigkeiten in vielen Zero-Shot-Aufgaben für nachgelagerte Anwendungen gezeigt und konkurrenzfähige Ergebnisse beim Erkennen von Objekten erzielt, die durch nur kurze Textprompts definiert sind. Es hat sich jedoch auch gezeigt, dass VL-Modelle beim Schlussfolgern über strukturierte VL-Konzepte (Structured VL Concept, SVLC) nach wie vor anfällig sind, etwa bei der Fähigkeit, Objektattribute, -zustände und Beziehungen zwischen Objekten zu erkennen. Dies führt zu Schlussfolgerungsfehlern, die korrigiert werden müssen, sobald sie auftreten, indem den VL-Modellen die fehlenden SVLC-Fähigkeiten beigebracht werden; oft muss dies anhand privater Daten geschehen, in denen das Problem festgestellt wurde, was natürlicherweise zu einer datenfreien kontinuierlichen VL-Lernumgebung (ohne Task-ID) führt. In dieser Arbeit führen wir den ersten Benchmark für kontinuierliches, datenfreies Lernen strukturierter VL-Konzepte (Continual Data-Free Structured VL Concepts Learning, ConStruct-VL) ein und zeigen, dass er für viele bestehende datenfreie CL-Strategien herausfordernd ist. Wir schlagen daher eine datenfreie Methode vor, die aus einem neuen Ansatz des Adversarial Pseudo-Replay (APR) besteht, der adversariale Erinnerungen an vergangene Aufgaben aus den Modellen vergangener Aufgaben erzeugt. Um diese Methode effizient zu nutzen, schlagen wir außerdem eine kontinuierliche, parametereffiziente Layered-LoRA-Architektur (LaLo) vor, die einen speicherkostenfreien Zugriff auf alle vergangenen Modelle zur Trainingszeit ermöglicht. Wir zeigen, dass dieser Ansatz alle datenfreien Methoden um bis zu ~7 % übertrifft und dabei sogar mit einigen Niveaus von Experience Replay gleichzieht (was für Anwendungen, in denen der Datenschutz gewahrt bleiben muss, nicht infrage kommt). Unser Code ist öffentlich verfügbar unter https://github.com/jamessealesmith/ConStruct-VL
Details
Zitation
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}