ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
Sintesi del comunicato stampa
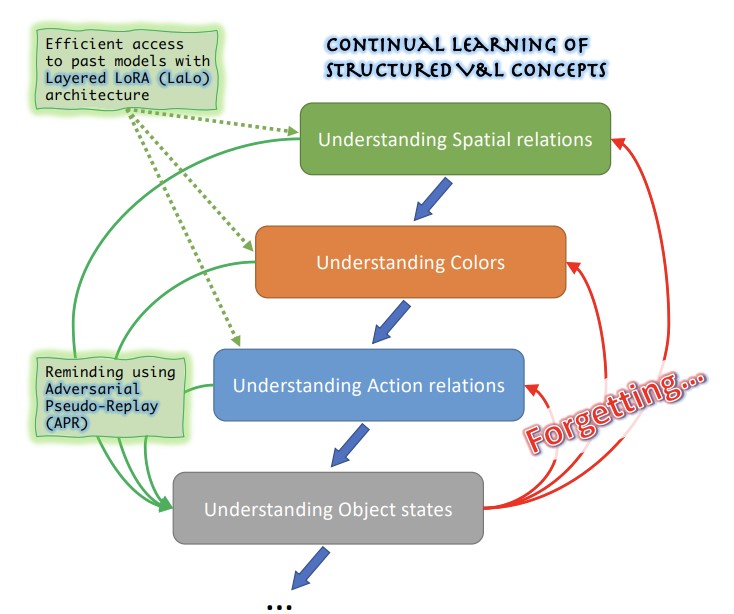
Ricercatori del MIT-IBM Watson AI Lab, Georgia Tech, Rice University, IBM Research e Stanford hanno affrontato un problema pratico ma poco esplorato dei grandi modelli di intelligenza artificiale vision-and-language: questi sistemi tendono a faticare nel comprendere concetti relazionali e descrittivi sfumati — come colori, dimensioni, posizioni spaziali e stati degli oggetti — e quando gli ingegneri cercano di correggere una di queste debolezze mettendo a punto il modello su nuovi dati, il modello tende a dimenticare come gestire le debolezze già corrette in precedenza, un fenomeno noto come oblio catastrofico. La situazione è resa più difficile dal fatto che i dati usati per individuare e correggere ciascun problema sono spesso privati e non possono essere conservati o riutilizzati nei cicli di addestramento successivi. Per affrontare la questione, il team ha creato ConStruct-VL, il primo benchmark specificamente progettato per valutare l'apprendimento continuo di questi concetti strutturati visivo-linguistici senza accesso ai dati dei compiti precedenti e senza alcun suggerimento, in fase di test, su quale tipo di concetto venga valutato. Hanno inoltre sviluppato due contributi tecnici complementari: un'architettura Layered-LoRA (LaLo) che impila moduli adattatori leggeri e a basso rango sopra un modello base congelato per ciascun nuovo compito, permettendo al sistema di accedere in modo efficiente al modello di qualsiasi compito precedente durante l'addestramento senza ricaricare i pesi; e un metodo di Adversarial Pseudo-Replay (APR) che usa quei modelli passati per generare esempi di addestramento negativi insidiosi — ad esempio alterando in modo sottile una descrizione testuale per includere una parola che indica un colore incoerente con l'immagine abbinata — successivamente usati per ricordare al modello attuale ciò che aveva appreso in precedenza. Testato sul modello vision-language BLIP attraverso molteplici sequenze di compiti tratte dai dataset Visual Genome e Visual Attributes in the Wild, l'approccio combinato ha ridotto l'oblio medio di circa cinque volte e ha migliorato l'accuratezza finale fino a 6,8 punti percentuali rispetto ai migliori metodi concorrenti di apprendimento continuo data-free, utilizzando solo circa il 2,8 percento dei parametri del modello completo — risultati rilevanti perché suggeriscono una strada percorribile per applicare correzioni in modo continuo ai modelli di IA in implementazioni reali sensibili alla privacy senza degradare i miglioramenti ottenuti in precedenza.
abstract
Di recente, i modelli fondazionali Vision-and-Language (VL) pre-addestrati su larga scala hanno dimostrato capacità notevoli in molti compiti downstream zero-shot, ottenendo risultati competitivi nel riconoscimento di oggetti definiti anche solo da brevi prompt testuali. Tuttavia, è stato anche dimostrato che i modelli VL restano fragili nel ragionamento sui Structured VL Concept (SVLC), come la capacità di riconoscere attributi, stati e relazioni tra oggetti. Ciò porta a errori di ragionamento, che devono essere corretti man mano che si presentano insegnando ai modelli VL le competenze SVLC mancanti; spesso questo deve essere fatto utilizzando dati privati nei quali il problema è stato individuato, il che conduce naturalmente a uno scenario di apprendimento VL continuo data-free (senza task-id). In questo lavoro introduciamo il primo benchmark di Continual Data-Free Structured VL Concepts Learning (ConStruct-VL) e mostriamo che esso risulta impegnativo per molte strategie di apprendimento continuo data-free esistenti. Proponiamo quindi un metodo data-free composto da un nuovo approccio di Adversarial Pseudo-Replay (APR) che genera promemoria avversari dei compiti passati a partire dai modelli dei compiti passati. Per utilizzare questo metodo in modo efficiente, proponiamo anche un'architettura neurale continua ed efficiente nei parametri, Layered-LoRA (LaLo), che consente l'accesso a costo di memoria nullo a tutti i modelli passati durante l'addestramento. Mostriamo che questo approccio supera tutti i metodi data-free fino a circa ~7%, eguagliando persino alcuni livelli di experience-replay (proibitivi per applicazioni in cui la privacy dei dati deve essere preservata). Il nostro codice è pubblicamente disponibile all'indirizzo https://github.com/jamessealesmith/ConStruct-VL
dettagli
citazione
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}