ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
Краткое изложение пресс-релиза
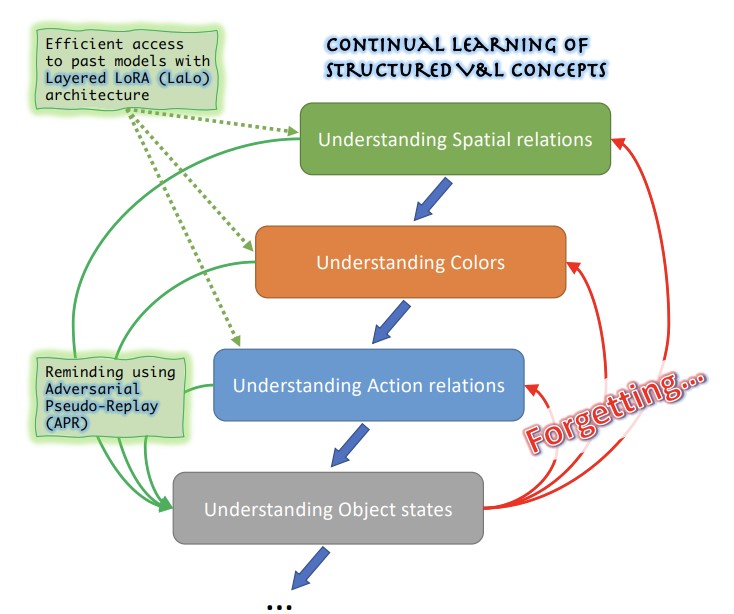
Исследователи из MIT-IBM Watson AI Lab, Georgia Tech, Rice University, IBM Research и Stanford взялись за практическую, но малоизученную проблему больших моделей зрения и языка: эти системы обычно испытывают трудности с пониманием нюансированных реляционных и описательных концептов — таких как цвета, размеры, пространственные положения и состояния объектов — и когда инженеры пытаются исправить одну такую слабость путём дообучения модели на новых данных, модель склонна забывать, как обрабатывать ранее исправленные слабости, явление, известное как катастрофическое забывание. Ситуация осложняется тем, что данные, используемые для выявления и устранения каждой проблемы, часто являются частными и не могут быть сохранены или повторно использованы между раундами обучения. Чтобы решить эту проблему, команда создала ConStruct-VL — первый бенчмарк, специально разработанный для оценки непрерывного обучения этим структурированным концептам зрения и языка без доступа к данным предыдущих задач и без какой-либо подсказки во время тестирования о том, какой тип концепта оценивается. Они также разработали два взаимодополняющих технических вклада: архитектуру Layered-LoRA (LaLo), которая накладывает лёгкие низкоранговые адаптерные модули поверх замороженной базовой модели для каждой новой задачи, позволяя системе эффективно обращаться к модели любой предыдущей задачи во время обучения без перезагрузки весов; и метод Adversarial Pseudo-Replay (APR), который использует эти прошлые модели для генерации хитрых отрицательных обучающих примеров — например, тонко изменяя текстовое описание, чтобы включить слово-цвет, несогласованное с парным изображением — которые затем используются, чтобы напомнить текущей модели то, что она ранее выучила. Протестированный на модели зрения и языка BLIP на нескольких последовательностях задач, взятых из наборов данных Visual Genome и Visual Attributes in the Wild, объединённый подход снизил среднее забывание примерно в пять раз и улучшил итоговую точность вплоть до 6.8 процентных пункта по сравнению с лучшими конкурирующими методами непрерывного обучения без данных, при этом используя лишь около 2.8 процента параметров полной модели — результаты, которые важны, потому что указывают на жизнеспособный путь для непрерывного исправления моделей ИИ в чувствительных к конфиденциальности реальных развёртываниях без ухудшения более ранних улучшений.
аннотация
В последнее время крупномасштабные предобученные фундаментальные модели зрения и языка (Vision-and-Language, VL) продемонстрировали замечательные способности во многих целевых задачах в режиме zero-shot, достигая конкурентоспособных результатов в распознавании объектов, заданных всего лишь короткими текстовыми подсказками. Однако также было показано, что VL-модели всё ещё хрупки в рассуждениях о структурированных VL-концептах (Structured VL Concept, SVLC), таких как способность распознавать атрибуты объектов, состояния и межобъектные отношения. Это приводит к ошибкам рассуждения, которые необходимо исправлять по мере их возникновения, обучая VL-модели недостающим навыкам SVLC; часто это приходится делать с использованием частных данных, где была обнаружена проблема, что естественным образом приводит к сценарию непрерывного (continual) обучения VL без данных (без идентификатора задачи). В этой работе мы представляем первый бенчмарк непрерывного обучения структурированным VL-концептам без данных (Continual Data-Free Structured VL Concepts Learning, ConStruct-VL) и показываем, что он сложен для многих существующих стратегий непрерывного обучения (CL) без данных. Поэтому мы предлагаем метод без данных, состоящий из нового подхода Adversarial Pseudo-Replay (APR), который генерирует состязательные напоминания о прошлых задачах из моделей прошлых задач. Чтобы использовать этот метод эффективно, мы также предлагаем непрерывную параметрически-эффективную нейронную архитектуру Layered-LoRA (LaLo), обеспечивающую доступ без затрат памяти ко всем прошлым моделям во время обучения. Мы показываем, что этот подход превосходит все методы без данных вплоть до ~7%, при этом даже соответствуя некоторым уровням experience-replay (недопустимого для приложений, где должна сохраняться конфиденциальность данных). Наш код публично доступен по адресу https://github.com/jamessealesmith/ConStruct-VL
подробности
цитирование
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}