ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
プレスリリース要約
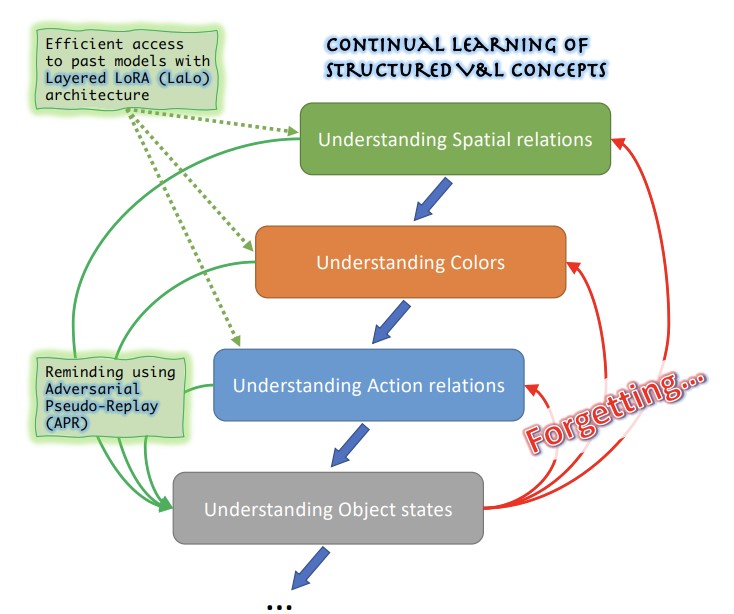
MIT-IBM Watson AI Lab、Georgia Tech、Rice University、IBM Research、Stanfordの研究者らは、大規模な視覚言語AIモデルに関する、実用的でありながら十分に研究されてこなかった問題に取り組みました。これらのシステムは、物体の色、サイズ、空間的な位置、状態といった微妙な関係的・記述的概念の理解に苦労する傾向があり、技術者が新しいデータでモデルをファインチューニングしてそうした弱点の一つを修正しようとすると、以前に修正した弱点への対処方法を忘れてしまう傾向があります。これは破滅的忘却(catastrophic forgetting)として知られる現象です。各問題の特定と修正に用いるデータがしばしばプライベートで、学習ラウンドをまたいで保持したり再利用したりできないという事実が、この状況をさらに困難にしています。これに対処するため、研究チームはConStruct-VLを作成しました。これは、過去のタスクデータにアクセスせず、またテスト時にどの種類の概念が評価されているかについて一切のヒントなしに、こうした構造化された視覚言語概念の継続学習を評価するために特別に設計された初のベンチマークです。彼らはまた、互いを補完する2つの技術的貢献を開発しました。1つは階層型LoRA(LaLo)アーキテクチャで、新しいタスクごとに凍結したベースモデルの上に軽量な低ランクアダプタモジュールを積み重ね、重みを再読み込みすることなく学習中に過去のどのタスクのモデルにも効率的にアクセスできるようにします。もう1つは敵対的擬似リプレイ(APR)手法で、それらの過去モデルを用いて巧妙な負例の学習サンプルを生成します。たとえば、テキスト記述を微妙に書き換えて、ペアになっている画像と矛盾する色の語を含めるといった具合です。これらは現在のモデルに以前学習した内容を思い出させるために用いられます。Visual GenomeおよびVisual Attributes in the Wildデータセットから取り出した複数のタスク系列にわたってBLIP視覚言語モデルでテストしたところ、この組み合わせ手法は、最良の競合データフリー継続学習手法と比べて平均忘却を約5分の1に削減し、最終精度を最大6.8パーセントポイント向上させました。しかも使用したのはモデル全体のパラメータの約2.8パーセントだけでした。これらの結果は、プライバシーに配慮した現実世界の運用において、以前の改善を損なうことなくAIモデルを継続的にパッチ修正していく実行可能な道筋を示唆している点で重要です。
要旨
近年、大規模に事前学習されたVision-and-Language(VL)基盤モデルは、多くのゼロショット下流タスクで目覚ましい能力を示し、わずかな短いテキストプロンプトだけで定義された物体を認識する点でも競争力のある結果を達成しています。しかし、VLモデルは、物体の属性、状態、物体間の関係を認識する能力など、構造化VL概念(SVLC)の推論においては依然として脆弱であることも示されています。これは推論の誤りにつながり、発生したその場でVLモデルに欠けているSVLCのスキルを教えることで修正する必要があります。多くの場合、これは問題が発見された場所のプライベートなデータを用いて行わなければならず、必然的にデータフリーの継続的(タスクIDなし)VL学習設定につながります。本研究では、初の継続的データフリー構造化VL概念学習(ConStruct-VL)ベンチマークを導入し、それが既存の多くのデータフリー継続学習(CL)手法にとって困難であることを示します。そこで我々は、過去のタスクモデルから過去タスクの敵対的なリマインダーを生成する新たなアプローチである敵対的擬似リプレイ(Adversarial Pseudo-Replay、APR)からなるデータフリー手法を提案します。この手法を効率的に用いるため、学習時に過去の全モデルへメモリコストなしでアクセスできる、継続的かつパラメータ効率の高い階層型LoRA(Layered-LoRA、LaLo)ニューラルアーキテクチャも提案します。このアプローチは、すべてのデータフリー手法を最大で約7%上回り、(データプライバシーを保持しなければならないアプリケーションでは利用できない)経験リプレイの一部の水準にも匹敵することを示します。我々のコードはhttps://github.com/jamessealesmith/ConStruct-VL で公開されています。
詳細
引用
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}