ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
Resumen de prensa
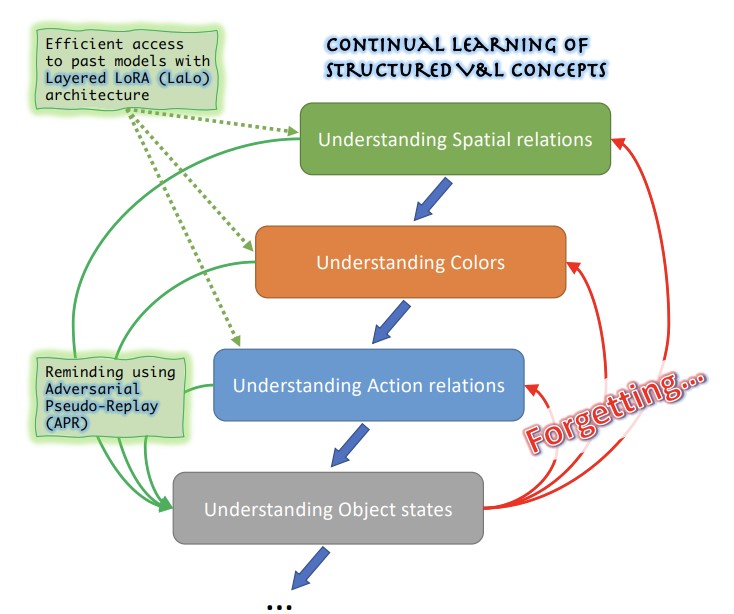
Investigadores del MIT-IBM Watson AI Lab, Georgia Tech, la Universidad Rice, IBM Research y Stanford han abordado un problema práctico pero poco explorado de los grandes modelos de IA de visión y lenguaje: estos sistemas tienden a tener dificultades para comprender conceptos relacionales y descriptivos matizados —como los colores, tamaños, posiciones espaciales y estados de los objetos—, y cuando los ingenieros intentan corregir una de estas debilidades ajustando el modelo con nuevos datos, el modelo tiende a olvidar cómo manejar las debilidades corregidas previamente, un fenómeno conocido como olvido catastrófico. La situación se complica por el hecho de que los datos utilizados para identificar y corregir cada problema suelen ser privados y no pueden conservarse ni reutilizarse entre rondas de entrenamiento. Para abordar esto, el equipo creó ConStruct-VL, el primer benchmark diseñado específicamente para evaluar el aprendizaje continuo de estos conceptos visuales-lingüísticos estructurados sin acceso a los datos de tareas anteriores y sin ninguna pista en el momento de la prueba sobre qué tipo de concepto se está evaluando. También desarrollaron dos contribuciones técnicas complementarias: una arquitectura Layered-LoRA (LaLo) que apila módulos adaptadores ligeros y de bajo rango sobre un modelo base congelado para cada nueva tarea, lo que permite que el sistema acceda eficientemente al modelo de cualquier tarea previa durante el entrenamiento sin recargar pesos; y un método de Adversarial Pseudo-Replay (APR) que utiliza esos modelos pasados para generar ejemplos de entrenamiento negativos engañosos —por ejemplo, alterando sutilmente una descripción de texto para incluir una palabra de color incoherente con la imagen emparejada—, que luego se usan para recordarle al modelo actual lo que aprendió previamente. Probado en el modelo de visión y lenguaje BLIP a través de múltiples secuencias de tareas extraídas de los conjuntos de datos Visual Genome y Visual Attributes in the Wild, el enfoque combinado redujo el olvido promedio aproximadamente cinco veces y mejoró la precisión final hasta en 6.8 puntos porcentuales en comparación con los mejores métodos competidores de aprendizaje continuo sin datos, usando solo alrededor del 2.8 por ciento de los parámetros del modelo completo —resultados que importan porque sugieren una vía viable para parchear continuamente modelos de IA en despliegues del mundo real sensibles a la privacidad sin degradar las mejoras anteriores.
resumen
Recientemente, los modelos fundacionales de Visión y Lenguaje (VL) preentrenados a gran escala han demostrado capacidades notables en muchas tareas posteriores de cero disparos (zero-shot), logrando resultados competitivos para reconocer objetos definidos por tan solo breves indicaciones de texto. Sin embargo, también se ha demostrado que los modelos VL siguen siendo frágiles en el razonamiento de Conceptos VL Estructurados (SVLC), como la capacidad de reconocer atributos de objetos, estados y relaciones entre objetos. Esto conduce a errores de razonamiento, que deben corregirse a medida que ocurren enseñando a los modelos VL las habilidades SVLC que les faltan; a menudo esto debe hacerse utilizando datos privados donde se encontró el problema, lo que naturalmente conduce a un entorno de aprendizaje VL continuo (sin task-id) y sin datos. En este trabajo, introducimos el primer benchmark de Aprendizaje Continuo de Conceptos VL Estructurados sin Datos (ConStruct-VL) y mostramos que es desafiante para muchas estrategias de CL sin datos existentes. Por lo tanto, proponemos un método sin datos compuesto por un nuevo enfoque de Adversarial Pseudo-Replay (APR) que genera recordatorios adversariales de tareas pasadas a partir de modelos de tareas pasadas. Para usar este método de manera eficiente, también proponemos una arquitectura neuronal continua y eficiente en parámetros, Layered-LoRA (LaLo), que permite el acceso sin costo de memoria a todos los modelos pasados en tiempo de entrenamiento. Mostramos que este enfoque supera a todos los métodos sin datos hasta en un ~7%, igualando incluso algunos niveles de repetición de experiencia (prohibitivos para aplicaciones donde debe preservarse la privacidad de los datos). Nuestro código está disponible públicamente en https://github.com/jamessealesmith/ConStruct-VL
detalles
cita
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}