ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.
Tóm tắt thông cáo báo chí
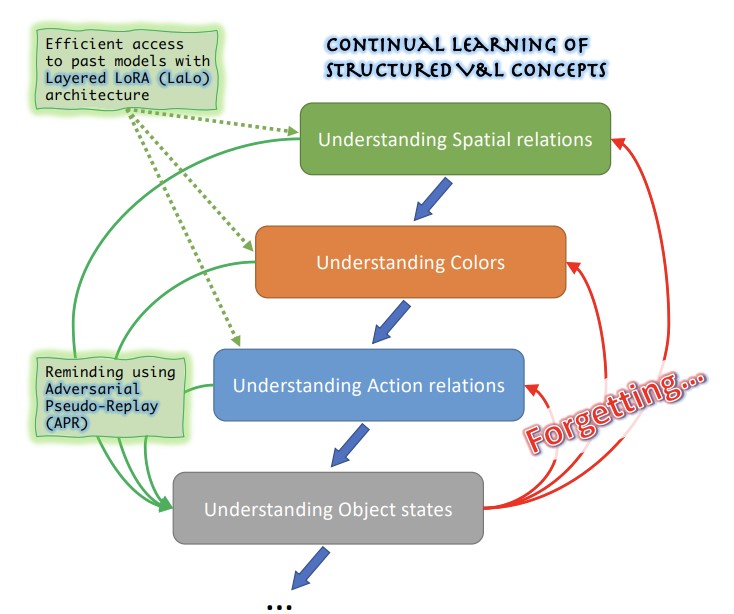
Các nhà nghiên cứu từ MIT-IBM Watson AI Lab, Georgia Tech, Rice University, IBM Research, và Stanford đã giải quyết một vấn đề thực tiễn nhưng ít được khám phá với các mô hình AI thị giác-và-ngôn ngữ lớn: các hệ thống này có xu hướng gặp khó khăn trong việc hiểu các khái niệm quan hệ và mô tả tinh tế — chẳng hạn như màu sắc, kích thước, vị trí không gian, và trạng thái của đối tượng — và khi các kỹ sư cố gắng khắc phục một điểm yếu như vậy bằng cách tinh chỉnh mô hình trên dữ liệu mới, mô hình lại có xu hướng quên cách xử lý các điểm yếu đã được sửa chữa trước đó, một hiện tượng được gọi là quên thảm họa. Tình huống còn khó khăn hơn bởi thực tế rằng dữ liệu được sử dụng để xác định và khắc phục mỗi vấn đề thường là riêng tư và không thể được giữ lại hoặc tái sử dụng qua các vòng huấn luyện. Để giải quyết điều này, nhóm đã tạo ra ConStruct-VL, benchmark đầu tiên được thiết kế đặc biệt để đánh giá việc học liên tục các khái niệm thị giác-ngôn ngữ có cấu trúc này mà không truy cập vào dữ liệu tác vụ trước đó và không có bất kỳ gợi ý nào tại thời điểm kiểm thử về loại khái niệm nào đang được đánh giá. Họ cũng phát triển hai đóng góp kỹ thuật bổ trợ: một kiến trúc Layered-LoRA (LaLo) xếp chồng các mô-đun bộ thích ứng hạng thấp, nhẹ lên trên một mô hình cơ sở bị đóng băng cho mỗi tác vụ mới, cho phép hệ thống truy cập hiệu quả vào mô hình của bất kỳ tác vụ trước đó nào trong quá trình huấn luyện mà không cần nạp lại trọng số; và một phương pháp Adversarial Pseudo-Replay (APR) sử dụng các mô hình trước đó đó để sinh ra các ví dụ huấn luyện tiêu cực hóc búa — ví dụ, thay đổi một cách tinh vi một mô tả văn bản để bao gồm một từ chỉ màu sắc không nhất quán với ảnh được ghép cặp — sau đó được sử dụng để nhắc nhở mô hình hiện tại về những gì nó đã học trước đó. Được kiểm thử trên mô hình thị giác-ngôn ngữ BLIP qua nhiều chuỗi tác vụ rút ra từ các bộ dữ liệu Visual Genome và Visual Attributes in the Wild, cách tiếp cận kết hợp đã giảm mức quên trung bình khoảng năm lần và cải thiện độ chính xác cuối cùng tới 6.8 điểm phần trăm so với các phương pháp học liên tục không cần dữ liệu cạnh tranh tốt nhất, trong khi chỉ sử dụng khoảng 2.8 phần trăm tham số của mô hình đầy đủ — những kết quả có ý nghĩa vì chúng gợi ý một con đường khả thi để liên tục vá các mô hình AI trong các triển khai thực tế nhạy cảm về quyền riêng tư mà không làm suy giảm những cải tiến trước đó.
tóm tắt
Gần đây, các mô hình nền tảng Vision-and-Language (VL) được tiền huấn luyện quy mô lớn đã chứng minh những khả năng đáng chú ý trong nhiều tác vụ hạ nguồn zero-shot, đạt được các kết quả cạnh tranh trong việc nhận diện các đối tượng được định nghĩa chỉ bằng những lời nhắc văn bản ngắn. Tuy nhiên, người ta cũng đã chỉ ra rằng các mô hình VL vẫn còn mong manh trong việc suy luận về Khái niệm VL có Cấu trúc (Structured VL Concept - SVLC), chẳng hạn như khả năng nhận diện các thuộc tính, trạng thái của đối tượng, và các quan hệ giữa các đối tượng. Điều này dẫn đến các lỗi suy luận, cần được sửa chữa khi chúng xảy ra bằng cách dạy cho các mô hình VL những kỹ năng SVLC còn thiếu; thường thì việc này phải được thực hiện bằng cách sử dụng dữ liệu riêng tư nơi vấn đề được phát hiện, điều này tự nhiên dẫn đến một thiết lập học VL liên tục không cần dữ liệu (không có mã định danh tác vụ). Trong công trình này, chúng tôi giới thiệu benchmark Học Khái niệm VL có Cấu trúc Liên tục Không cần Dữ liệu (Continual Data-Free Structured VL Concepts Learning - ConStruct-VL) đầu tiên và cho thấy nó là thách thức đối với nhiều chiến lược học liên tục (CL) không cần dữ liệu hiện có. Do đó, chúng tôi đề xuất một phương pháp không cần dữ liệu bao gồm một cách tiếp cận mới về Adversarial Pseudo-Replay (APR), phương pháp này sinh ra các lời nhắc đối kháng về các tác vụ trước đây từ các mô hình tác vụ trước đây. Để sử dụng phương pháp này một cách hiệu quả, chúng tôi cũng đề xuất một kiến trúc nơ-ron Layered-LoRA (LaLo) hiệu quả về tham số và liên tục, cho phép truy cập không tốn bộ nhớ vào tất cả các mô hình trước đây tại thời điểm huấn luyện. Chúng tôi cho thấy cách tiếp cận này vượt trội hơn tất cả các phương pháp không cần dữ liệu tới khoảng ~7% trong khi thậm chí còn sánh ngang một số mức của experience-replay (vốn không khả thi cho các ứng dụng nơi tính riêng tư của dữ liệu phải được bảo toàn). Mã của chúng tôi được công bố công khai tại https://github.com/jamessealesmith/ConStruct-VL
chi tiết
trích dẫn
@inproceedings{smith2023construct,
title = {ConStruct-VL: Data-Free Continual Structured VL Concepts Learning.},
author = {Smith, James Seale and Cascante-Bonilla, Paola and Arbelle, Assaf and Kim, Donghyun and Panda, Rameswar and Cox, David and Yang, Diyi and Kira, Zsolt and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {Conf. on Computer Vision and Pattern Recognition CVPR 2023},
url = {https://arxiv.org/abs/2211.09790},
}