SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Zusammenfassung der Pressemitteilung
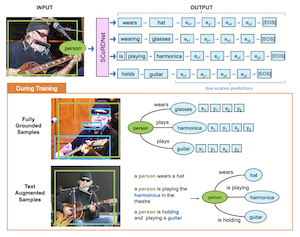
Forschende der Rice University und von Adobe Research haben ein System namens SCoRD – kurz für Subject-Conditional Relation Detection – entwickelt, das zu einem bestimmten Objekt in einem Foto automatisch alles identifiziert, womit dieses Objekt interagiert, worin diese Interaktionen bestehen und wo sich die anderen Objekte im Bild befinden. Anstatt zu versuchen, jede mögliche Beziehung zwischen allen Objekten einer Szene abzubilden, was schnell unpraktikabel wird, konzentriert sich das System auf ein einzelnes gewähltes Subjekt und katalogisiert ausschließlich dessen relevante Verbindungen erschöpfend. Das Team baute sein Modell, SCoRDNet, als autoregressiven Sequenzdekodierer, der Relation-Objekt-Paare zusammen mit Bounding-Box-Koordinaten als Tokenstrom ausgibt, und entwarf einen auf dem Open-Images-Datensatz basierenden Benchmark, der eigens so gestaltet ist, dass Trainings- und Testdaten nicht übereinstimmende Beziehungsstatistiken aufweisen – was es einem Modell erschwert, häufige Muster einfach auswendig zu lernen. Eine zentrale Erkenntnis ist, dass sich die Leistung des Systems bei seltenen oder zuvor ungesehenen Beziehungstypen erheblich verbesserte, wenn das Training durch verrauschte Beziehungstripel ergänzt wurde, die automatisch aus Bildbeschreibungen extrahiert wurden, selbst wenn diese Beschreibungen überhaupt keine Bounding-Box-Annotationen enthielten. Bei Beziehungen, denen das Basismodell während des Trainings nie begegnet war, erreichte die textangereicherte Variante einen Recall von 33,8 % für Relation-Objekt-Paare und von 26,75 % für deren Box-Positionen, verglichen mit nahezu null bei der nicht unterstützten Baseline. Die Arbeit ist bedeutsam, weil sie einen besser skalierbaren Weg zur Beziehungserkennung mit offenem Vokabular bietet: Anstatt für jede mögliche Interaktion teure, vollständig annotierte Datensätze zu benötigen, legt der Ansatz nahe, dass große, bereits im Internet vorhandene Sammlungen von Bildern mit Bildunterschriften das, was solche Systeme erkennen und lokalisieren können, dramatisch erweitern könnten.
Zusammenfassung
Wir schlagen Subject-Conditional Relation Detection SCoRD vor, bei der – bedingt auf ein Eingabesubjekt – das Ziel darin besteht, alle seine Relationen zu anderen Objekten in einer Szene zusammen mit deren Positionen vorherzusagen. Auf Grundlage des Open-Images-Datensatzes schlagen wir einen anspruchsvollen OIv6-SCoRD-Benchmark vor, bei dem die Trainings- und Testaufteilungen eine Verteilungsverschiebung hinsichtlich der Häufigkeitsstatistik der $\langle$Subjekt, Relation, Objekt$\rangle$-Tripel aufweisen. Um dieses Problem zu lösen, schlagen wir ein autoregressives Modell vor, das zu einem gegebenen Subjekt dessen Relationen, Objekte und Objektpositionen vorhersagt, indem diese Ausgabe als eine Folge von Tokens dargestellt wird. Zunächst zeigen wir, dass frühere Methoden zur Szenengraph-Vorhersage auf diesem Benchmark, bedingt auf ein Subjekt, keine ebenso erschöpfende Aufzählung von Relation-Objekt-Paaren erzeugen. Insbesondere erreichen wir für unsere Relation-Objekt-Vorhersagen einen Recall@3 von 83,8 % im Vergleich zu den 49,75 %, die ein aktueller Szenengraph-Detektor erzielt. Anschließend zeigen wir eine verbesserte Generalisierung sowohl bei Relation-Objekt- als auch bei Objekt-Box-Vorhersagen, indem wir während des Trainings Relation-Objekt-Paare nutzen, die automatisch aus Textbeschreibungen gewonnen werden und für die keine Objekt-Box-Annotationen verfügbar sind. Insbesondere können wir für $\langle$Subjekt, Relation, Objekt$\rangle$-Tripel, für die während des Trainings keine Objektpositionen verfügbar sind, einen Recall@3 von 33,80 % für Relation-Objekt-Paare und von 26,75 % für deren Box-Positionen erzielen.
Details
Zitation
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist SCoRD? SCoRD ist eine subjektbedingte Beziehungserkennungsaufgabe, bei der ein Modell ein gewähltes Subjekt in einem Bild erhält und die Relationen dieses Subjekts, die zugehörigen Objekte und die Objektpositionen vorhersagt.
- Wie unterscheidet sich SCoRD von der vollständigen Szenengraph-Generierung? Anstatt jede Relation zwischen allen Objekten vorherzusagen, konzentriert sich SCoRD darauf, die Relationen eines einzigen abgefragten Subjekts erschöpfend zu beschreiben, was für nachgelagerte Anwendungen oft praktischer ist.
- Was ist SCoRDNet? SCoRDNet ist ein autoregressives Vision-Language-Modell, das Relation-Objekt-Vorhersagen und Bounding-Box-Koordinaten als eine Folge von Tokens darstellt.
- Warum textangereicherte Daten verwenden? Aus Bildunterschriften abgeleitete Relation-Objekt-Tripel liefern skalierbare Supervision für seltene oder ungesehene Relationen, selbst wenn die Bildunterschriften keine Objekt-Box-Annotationen enthalten.
- Was prüft der OIv6-SCoRD-Benchmark? Der Benchmark erzeugt Verteilungsverschiebungen zwischen Training und Test bei Subjekt-Relation-Objekt-Tripeln und ist damit ein anspruchsvoller Test für die Generalisierung über auswendig gelernte Relationsstatistiken hinaus.
Wichtigste Beiträge
- Das Paper definiert Subject-Conditional Relation Detection als eine fokussierte Alternative zur vollständigen Szenengraph-Generierung, um die Beziehungen eines bestimmten Objekts zu beschreiben.
- Es führt OIv6-SCoRD ein, einen Benchmark, der darauf ausgelegt ist, die Beziehungserkennung unter Verteilungsverschiebungen in der Relation-Objekt-Statistik einem Belastungstest zu unterziehen.
- SCoRDNet fasst die Vorhersage von Relation, Objekt und Lokalisierung als ein vereinheitlichtes Token-Dekodierungsproblem auf, sodass geerdete und nicht geerdete Supervision in einem einzigen Modell verarbeitet werden können.
- Das Paper zeigt, dass textangereichertes Training aus Bildunterschriften die Generalisierung auf unterrepräsentierte und ungesehene Relation-Objekt-Paare erheblich verbessert.
- SCoRDNet übertrifft subjektbedingte Anpassungen von Szenengraph-Methoden bei der Relation-Objekt-Vorhersage und zeigt, dass nicht geerdete Bildunterschriften sowohl die Relationsvorhersage als auch die Objektlokalisierung verbessern können.
Grenzen und Vorbehalte
- SCoRD setzt voraus, dass ein Subjekt und dessen Box als Eingabe bereitgestellt werden, was die Aufgabe fokussiert hält und sie gut für Anwendungen geeignet macht, in denen ein Nutzer oder ein vorgeschalteter Detektor das interessierende Objekt identifiziert.
- Aus Bildunterschriften abgeleitete Relationstripel sind verrauscht und enthalten oft keine Objekt-Boxen, doch das Paper macht aus diesem schwachen Signal eine Stärke, indem es zeigt, dass es die Generalisierung dennoch verbessert, wenn es mit geerdeten Daten kombiniert wird.
- Die Methode wird auf einem Benchmark ausgewertet, der aus Open Images und Bildunterschriftsquellen wie COCO und Conceptual Captions abgeleitet ist, sodass umfassendere Bildsammlungen aus der offenen Welt als naheliegende nächste Tests offenbleiben.
- SCoRDNet sagt Boxen durch Sequenzdekodierung und nicht durch spezialisierte Box-Verfeinerung vorher, was Raum für künftige Kombinationen mit stärkeren Lokalisierungsmodulen lässt.
- Die Aufgabe konzentriert sich auf subjektzentrierte Relationen statt auf vollständige Szenengraphen, was eine praktische und skalierbare Formulierung ergibt und zugleich umfassendere Systeme zur Graphgenerierung ergänzt.
Wie dieses Ergebnis zu lesen ist
Dieses Paper liest sich am besten als ein starker Schritt hin zu einem skalierbaren Verständnis visueller Beziehungen: SCoRD formuliert die Beziehungserkennung rund um ein abgefragtes Subjekt neu, und SCoRDNet zeigt, dass kostengünstige Supervision aus Bildunterschriften das Spektrum der Relation-Objekt-Paare, die ein Modell erkennen und lokalisieren kann, spürbar erweitern kann.