SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Resumo do comunicado de imprensa
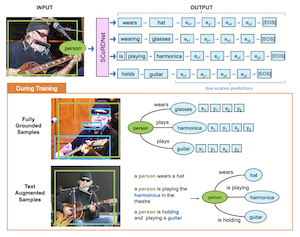
Pesquisadores da Rice University e da Adobe Research desenvolveram um sistema chamado SCoRD — abreviação de Subject-Conditional Relation Detection (Detecção de Relações Condicionada ao Sujeito) — que, dado um objeto específico em uma foto, identifica automaticamente tudo com que esse objeto está interagindo, quais são essas interações e onde os outros objetos estão localizados na imagem. Em vez de tentar mapear todas as relações possíveis entre todos os objetos de uma cena, o que rapidamente se torna impraticável, o sistema concentra-se em um único sujeito escolhido e cataloga exaustivamente apenas suas conexões relevantes. A equipe construiu seu modelo, o SCoRDNet, como um decodificador de sequência autorregressivo que produz pares relação-objeto juntamente com coordenadas de caixa delimitadora como um fluxo de tokens, e projetou um benchmark baseado no conjunto de dados Open Images especificamente elaborado para que os dados de treinamento e teste tenham estatísticas de relação incompatíveis — tornando mais difícil para um modelo simplesmente memorizar padrões comuns. Uma descoberta importante é que o desempenho do sistema em tipos de relação raros ou nunca antes vistos melhorou substancialmente quando o treinamento foi complementado com triplas de relação ruidosas extraídas automaticamente de legendas de imagens, mesmo quando essas legendas não vinham com nenhuma anotação de caixa delimitadora. Em relações que o modelo de base nunca havia encontrado durante o treinamento, a versão aumentada por texto alcançou um recall de 33,8% para pares relação-objeto e 26,75% para suas localizações de caixa, em comparação com quase zero da base sem auxílio. O trabalho é importante porque oferece um caminho mais escalável rumo à detecção de relações de vocabulário aberto: em vez de exigir caros conjuntos de dados totalmente anotados para cada interação possível, a abordagem sugere que grandes coleções de imagens com legendas já existentes na internet poderiam expandir dramaticamente o que tais sistemas conseguem reconhecer e localizar.
resumo
Propomos a Detecção de Relações Condicionada ao Sujeito (SCoRD), na qual, condicionado a um sujeito de entrada, o objetivo é prever todas as suas relações com outros objetos em uma cena, juntamente com suas localizações. Com base no conjunto de dados Open Images, propomos um desafiador benchmark OIv6-SCoRD de modo que as divisões de treinamento e teste tenham uma mudança de distribuição em termos das estatísticas de ocorrência de triplas $\langle$sujeito, relação, objeto$\rangle$. Para resolver esse problema, propomos um modelo autorregressivo que, dado um sujeito, prevê suas relações, objetos e localizações de objetos representando essa saída como uma sequência de tokens. Primeiro, mostramos que os métodos anteriores de previsão de grafos de cena não conseguem produzir uma enumeração tão exaustiva de pares relação-objeto quando condicionados a um sujeito nesse benchmark. Particularmente, obtemos um recall@3 de 83,8% para nossas previsões de relação-objeto em comparação com os 49,75% obtidos por um detector de grafos de cena recente. Em seguida, mostramos uma generalização aprimorada tanto nas previsões de relação-objeto quanto de caixa de objeto ao aproveitar durante o treinamento pares relação-objeto obtidos automaticamente a partir de legendas textuais e para os quais não há anotações de caixa de objeto disponíveis. Particularmente, para triplas $\langle$sujeito, relação, objeto$\rangle$ para as quais não há localizações de objetos disponíveis durante o treinamento, conseguimos obter um recall@3 de 33,80% para pares relação-objeto e 26,75% para suas localizações de caixa.
detalhes
citação
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o SCoRD? O SCoRD é uma tarefa de detecção de relações condicionada ao sujeito na qual um modelo recebe um sujeito escolhido em uma imagem e prevê as relações desse sujeito, os objetos relacionados e as localizações dos objetos.
- Como o SCoRD difere da geração completa de grafos de cena? Em vez de prever todas as relações entre todos os objetos, o SCoRD concentra-se em descrever exaustivamente as relações de um único sujeito consultado, o que muitas vezes é mais prático para aplicações downstream.
- O que é o SCoRDNet? O SCoRDNet é um modelo de visão e linguagem autorregressivo que representa as previsões de relação-objeto e as coordenadas de caixa delimitadora como uma sequência de tokens.
- Por que usar dados aumentados por texto? Triplas relação-objeto derivadas de legendas fornecem supervisão escalável para relações raras ou não vistas, mesmo quando as legendas não incluem anotações de caixa de objeto.
- O que o benchmark OIv6-SCoRD testa? O benchmark cria mudanças de distribuição entre treino e teste em triplas sujeito-relação-objeto, tornando-o um teste robusto de generalização para além das estatísticas de relação memorizadas.
Principais contribuições
- O artigo define a Detecção de Relações Condicionada ao Sujeito como uma alternativa focada à geração completa de grafos de cena para descrever as relações de um objeto especificado.
- Ele introduz o OIv6-SCoRD, um benchmark projetado para submeter a detecção de relações a testes de estresse sob mudanças de distribuição nas estatísticas de relação-objeto.
- O SCoRDNet formula a previsão de relação, objeto e localização como um problema unificado de decodificação de tokens, permitindo que a supervisão ancorada e não ancorada seja tratada em um único modelo.
- O artigo mostra que o treinamento aumentado por texto a partir de legendas melhora substancialmente a generalização para pares relação-objeto sub-representados e não vistos.
- O SCoRDNet supera as adaptações condicionadas ao sujeito de métodos de grafos de cena na previsão de relação-objeto e demonstra que legendas não ancoradas podem melhorar tanto a previsão de relação quanto a localização de objetos.
Limitações e ressalvas
- O SCoRD pressupõe que um sujeito e sua caixa sejam fornecidos como entrada, o que mantém a tarefa focada e a torna bem adequada para aplicações em que um usuário ou um detector a montante identifica o objeto de interesse.
- As triplas de relação derivadas de legendas são ruidosas e muitas vezes carecem de caixas de objeto, mas o artigo transforma esse sinal fraco em uma vantagem ao mostrar que ele ainda melhora a generalização quando combinado com dados ancorados.
- O método é avaliado em um benchmark derivado do Open Images e de fontes de legendas como COCO e Conceptual Captions, deixando coleções de imagens de mundo aberto mais amplas como testes futuros naturais.
- O SCoRDNet prevê caixas por meio de decodificação de sequência, em vez de refinamento de caixa especializado, o que deixa espaço para combinações futuras com módulos de localização mais fortes.
- A tarefa concentra-se em relações centradas no sujeito, em vez de grafos de cena completos, oferecendo uma formulação prática e escalável e complementando sistemas mais amplos de geração de grafos.
Como interpretar este resultado
Este artigo é melhor compreendido como um passo robusto rumo à compreensão escalável de relações visuais: o SCoRD reformula a detecção de relações em torno de um sujeito consultado, e o SCoRDNet mostra que a supervisão barata por legendas pode expandir de maneira significativa quais pares relação-objeto um modelo consegue reconhecer e localizar.