SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Краткое изложение пресс-релиза
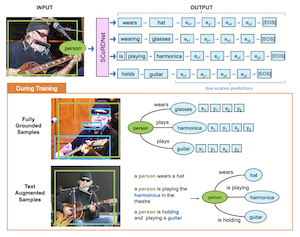
Исследователи из Rice University и Adobe Research разработали систему под названием SCoRD — сокращение от Subject-Conditional Relation Detection — которая по заданному конкретному объекту на фотографии автоматически определяет всё, с чем этот объект взаимодействует, что представляют собой эти взаимодействия и где расположены другие объекты на изображении. Вместо того чтобы пытаться отобразить все возможные отношения между всеми объектами в сцене, что быстро становится непрактичным, система фокусируется на одном выбранном субъекте и исчерпывающе каталогизирует только его релевантные связи. Команда построила свою модель SCoRDNet как авторегрессионный декодер последовательностей, который выводит пары отношение-объект вместе с координатами ограничивающих рамок в виде потока токенов, и они разработали бенчмарк на основе набора данных Open Images, специально сконструированный так, чтобы обучающие и тестовые данные имели несовпадающую статистику отношений — что усложняет модели простое запоминание распространённых паттернов. Ключевой вывод состоит в том, что производительность системы на редких или ранее невиданных типах отношений существенно улучшилась, когда обучение дополнялось зашумлёнными триплетами отношений, автоматически извлечёнными из подписей к изображениям, даже когда эти подписи вообще не сопровождались аннотациями ограничивающих рамок. На отношениях, которые базовая модель никогда не встречала при обучении, версия с текстовым дополнением достигла recall 33,8% для пар отношение-объект и 26,75% для их расположений рамок по сравнению с почти нулевым показателем для базовой модели без поддержки. Работа важна, поскольку она предлагает более масштабируемый путь к детекции отношений с открытым словарём: вместо того чтобы требовать дорогостоящих полностью аннотированных наборов данных для каждого возможного взаимодействия, подход показывает, что большие коллекции изображений с подписями, уже имеющиеся в интернете, могут радикально расширить то, что такие системы способны распознавать и локализовать.
аннотация
Мы предлагаем Subject-Conditional Relation Detection SCoRD, где при условии входного субъекта цель состоит в том, чтобы предсказать все его отношения с другими объектами в сцене вместе с их расположениями. На основе набора данных Open Images мы предлагаем сложный бенчмарк OIv6-SCoRD, такой что обучающая и тестовая выборки имеют сдвиг распределения с точки зрения статистики встречаемости триплетов $\langle$субъект, отношение, объект$\rangle$. Для решения этой проблемы мы предлагаем авторегрессионную модель, которая по заданному субъекту предсказывает его отношения, объекты и расположения объектов, представляя этот вывод как последовательность токенов. Сначала мы показываем, что предыдущие методы предсказания графа сцены не способны произвести столь же исчерпывающее перечисление пар отношение-объект при условии субъекта на этом бенчмарке. В частности, мы получаем recall@3 83,8% для наших предсказаний отношение-объект по сравнению с 49,75%, полученными недавним детектором графа сцены. Затем мы показываем улучшенную обобщающую способность как для предсказаний отношение-объект, так и для предсказаний рамок объектов, задействуя при обучении пары отношение-объект, полученные автоматически из текстовых подписей и для которых недоступны аннотации рамок объектов. В частности, для триплетов $\langle$субъект, отношение, объект$\rangle$, для которых при обучении недоступны расположения объектов, мы способны получить recall@3 33,80% для пар отношение-объект и 26,75% для их расположений рамок.
подробности
цитирование
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Что такое SCoRD? SCoRD — это задача субъектно-условной детекции отношений, где модель получает выбранный субъект на изображении и предсказывает отношения этого субъекта, связанные объекты и расположения объектов.
- Чем SCoRD отличается от полной генерации графа сцены? Вместо предсказания каждого отношения между каждым объектом SCoRD фокусируется на исчерпывающем описании отношений одного запрошенного субъекта, что часто более практично для целевых приложений.
- Что такое SCoRDNet? SCoRDNet — это авторегрессионная модель зрения и языка, которая представляет предсказания отношение-объект и координаты ограничивающих рамок в виде последовательности токенов.
- Зачем использовать данные с текстовым дополнением? Извлечённые из подписей триплеты отношение-объект обеспечивают масштабируемое обучение для редких или невиданных отношений, даже когда подписи не включают аннотации рамок объектов.
- Что проверяет бенчмарк OIv6-SCoRD? Бенчмарк создаёт сдвиги распределения между обучением и тестом в триплетах субъект-отношение-объект, делая его серьёзной проверкой обобщающей способности за пределами запомненной статистики отношений.
Основные вклады
- В статье определяется Subject-Conditional Relation Detection как сфокусированная альтернатива полной генерации графа сцены для описания отношений заданного объекта.
- Вводится OIv6-SCoRD — бенчмарк, разработанный для стресс-тестирования детекции отношений при сдвигах распределения в статистике отношение-объект.
- SCoRDNet представляет предсказание отношения, объекта и локализации как единую задачу декодирования токенов, позволяя обрабатывать локализованное и нелокализованное обучение в одной модели.
- Статья показывает, что обучение с текстовым дополнением из подписей существенно улучшает обобщение на недопредставленные и невиданные пары отношение-объект.
- SCoRDNet превосходит субъектно-условные адаптации методов графа сцены в предсказании отношение-объект и демонстрирует, что нелокализованные подписи могут улучшать как предсказание отношений, так и локализацию объектов.
Ограничения и предостережения
- SCoRD предполагает, что субъект и его рамка предоставляются на вход, что сохраняет задачу сфокусированной и делает её хорошо подходящей для приложений, где пользователь или вышестоящий детектор идентифицирует интересующий объект.
- Извлечённые из подписей триплеты отношений зашумлены и часто лишены рамок объектов, но статья превращает этот слабый сигнал в преимущество, показывая, что он всё равно улучшает обобщение в сочетании с локализованными данными.
- Метод оценивается на бенчмарке, производном от Open Images, и источниках подписей, таких как COCO и Conceptual Captions, оставляя более широкие коллекции изображений открытого мира как естественные следующие тесты.
- SCoRDNet предсказывает рамки через декодирование последовательностей, а не через специализированное уточнение рамок, что оставляет место для будущих сочетаний с более сильными модулями локализации.
- Задача фокусируется на субъектно-центрированных отношениях, а не на полных графах сцены, давая практичную и масштабируемую формулировку, дополняющую при этом более широкие системы генерации графов.
Как интерпретировать этот результат
Эту статью лучше всего рассматривать как сильный шаг к масштабируемому пониманию визуальных отношений: SCoRD переформулирует детекцию отношений вокруг запрошенного субъекта, а SCoRDNet показывает, что недорогое обучение на подписях может значимо расширить то, какие пары отношение-объект модель способна распознавать и локализовать.