新闻稿摘要
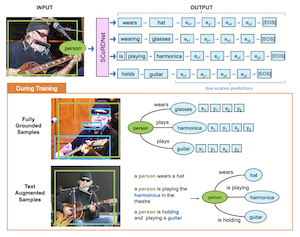
来自莱斯大学和 Adobe Research 的研究人员开发了一个名为 SCoRD(Subject-Conditional Relation Detection 的简称)的系统,给定照片中的某个特定对象,它能自动识别该对象正在与之交互的一切、这些交互是什么,以及其他对象在图像中的位置。该系统不试图映射场景中每个对象之间所有可能的关系(这很快就会变得不切实际),而是专注于单个选定的主体,并详尽地编录其相关的连接。团队将他们的模型 SCoRDNet 构建为一个自回归序列解码器,将关系-对象对连同边界框坐标作为一串 token 输出,并设计了一个基于 Open Images 数据集的基准,特别构造使训练和测试数据具有不匹配的关系统计——从而使模型更难仅仅记忆常见模式。一个关键发现是,当训练辅以从图像描述中自动提取的带噪声关系三元组时(即便这些描述完全没有边界框标注),系统在罕见或此前未见过的关系类型上的性能显著提升。在基础模型训练期间从未遇到过的关系上,文本增强版本为关系-对象对取得了 33.8% 的召回率,并为其框位置取得了 26.75%,而未经增强的基线接近于零。这项工作的意义在于,它提供了一条通向开放词汇关系检测的更可扩展路径:与其为每种可能的交互都需要昂贵的完全标注数据集,该方法表明,互联网上已有的大量带描述图像,可以极大地扩展此类系统能够识别和定位的内容。
摘要
我们提出主体条件关系检测(Subject-Conditional Relation Detection,SCoRD),其目标是在给定输入主体的条件下,预测该主体与场景中其他对象的所有关系及其位置。基于 Open Images 数据集,我们提出了一个具有挑战性的 OIv6-SCoRD 基准,使得训练和测试拆分在 $\langle$主体, 关系, 对象$\rangle$ 三元组的出现统计上存在分布偏移。为解决该问题,我们提出了一种自回归模型,给定一个主体,它通过将输出转化为一系列 token 来预测其关系、对象和对象位置。首先,我们表明,在该基准上以主体为条件时,以往的场景图预测方法无法生成同样详尽的关系-对象对枚举。特别地,我们的关系-对象预测取得了 83.8% 的 recall@3,而近期的一个场景图检测器仅为 49.75%。然后,我们表明,通过在训练期间利用从文本描述中自动获取的、没有对象框标注的关系-对象对,能够在关系-对象和对象框预测上获得更好的泛化。特别是,对于训练期间没有对象位置的 $\langle$主体, 关系, 对象$\rangle$ 三元组,我们能够为关系-对象对取得 33.80% 的 recall@3,并为其框位置取得 26.75%。
详情
引用
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
自动生成的本文相关问题、主要贡献与局限
本文有助于回答的问题
- 什么是 SCoRD?SCoRD 是一项主体条件关系检测任务,模型接收图像中一个选定的主体,并预测该主体的关系、相关对象以及对象位置。
- SCoRD 与完整的场景图生成有何不同?SCoRD 并不预测每个对象之间的每种关系,而是专注于详尽地描述一个被查询主体的关系,这对于下游应用往往更为实用。
- 什么是 SCoRDNet?SCoRDNet 是一个自回归视觉-语言模型,它将关系-对象预测和边界框坐标表示为一串 token。
- 为什么使用文本增强数据?从描述中派生的关系-对象三元组为罕见或未见过的关系提供了可扩展的监督,即便这些描述不包含对象框标注。
- OIv6-SCoRD 基准测试什么?该基准在主体-关系-对象三元组中制造了训练-测试分布偏移,使其成为对超越记忆关系统计的泛化能力的有力测试。
主要贡献
- 论文将主体条件关系检测定义为完整场景图生成的一种聚焦替代方案,用于描述特定对象的关系。
- 它引入了 OIv6-SCoRD,一个旨在压力测试关系检测在关系-对象统计分布偏移下表现的基准。
- SCoRDNet 将关系、对象和定位预测转化为统一的 token 解码问题,使得有定位和无定位的监督能够在一个模型中处理。
- 论文表明,来自描述的文本增强训练能够显著改善对代表性不足和未见过的关系-对象对的泛化。
- SCoRDNet 在关系-对象预测上优于场景图方法的主体条件改编版本,并证明无定位的描述能够同时改善关系预测和对象定位。
局限与注意事项
- SCoRD 假设主体及其框作为输入提供,这使任务保持聚焦,并使其非常适合用户或上游检测器识别感兴趣对象的应用场景。
- 从描述派生的关系三元组带有噪声且往往缺乏对象框,但论文将这一弱信号转化为优势,表明在与有定位数据结合时它仍能改善泛化。
- 该方法在源自 Open Images 以及 COCO 和 Conceptual Captions 等描述来源的基准上进行评估,将更广泛的开放世界图像集合留作自然的下一步测试。
- SCoRDNet 通过序列解码而非专门的框精炼来预测框,这为未来与更强定位模块的结合留下了空间。
- 该任务专注于以主体为中心的关系,而非完整的场景图,这提供了一种实用且可扩展的表述,同时与更广泛的图生成系统形成互补。
如何理解这一结果
这篇论文最好被理解为通向可扩展视觉关系理解的有力一步:SCoRD 围绕被查询的主体重新定义了关系检测,而 SCoRDNet 表明廉价的描述监督能够切实扩展模型能够识别和定位的关系-对象对。