보도 자료 요약
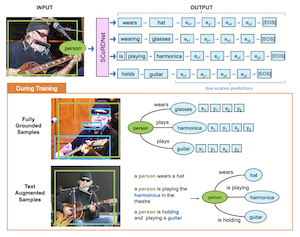
라이스 대학교와 Adobe Research의 연구자들은 SCoRD(Subject-Conditional Relation Detection의 약자)라는 시스템을 개발했다. 이 시스템은 사진 속 특정 객체가 주어지면, 그 객체가 상호작용하고 있는 모든 것, 그러한 상호작용이 무엇인지, 그리고 다른 객체들이 이미지의 어디에 위치하는지를 자동으로 식별한다. 장면 속 모든 객체 간의 가능한 모든 관계를 매핑하려 하면 금세 비현실적이 되는데, 이 시스템은 그 대신 선택된 하나의 주체에 초점을 맞추어 그것의 관련 연결만을 망라적으로 목록화한다. 연구팀은 자신들의 모델 SCoRDNet을, 관계-객체 쌍을 경계 상자 좌표와 함께 토큰의 스트림으로 출력하는 자기회귀 시퀀스 디코더로 구축했으며, Open Images 데이터셋을 기반으로 학습 및 테스트 데이터가 일치하지 않는 관계 통계를 갖도록 특별히 설계된 벤치마크를 만들어 모델이 단순히 흔한 패턴을 암기하기 더 어렵게 했다. 핵심 발견은 학습이 객체 박스 주석이 전혀 없는 이미지 캡션에서 자동으로 추출된 잡음 섞인 관계 삼중항으로 보강되었을 때, 드물거나 이전에 보지 못한 관계 유형에 대한 시스템의 성능이 상당히 향상되었다는 점이다. 기본 모델이 학습 중에 한 번도 접하지 못한 관계에 대해, 텍스트로 보강된 버전은 관계-객체 쌍에 대해 33.8%, 그 박스 위치에 대해 26.75%의 recall을 달성한 반면, 도움받지 않은 기준선은 거의 0에 가까웠다. 이 연구는 open-vocabulary 관계 탐지로 가는 더 확장 가능한 길을 제시하기 때문에 중요하다. 가능한 모든 상호작용에 대해 비싼 완전 주석 데이터셋을 요구하는 대신, 이 접근법은 이미 인터넷에 있는 캡션이 달린 이미지의 대규모 모음이 이러한 시스템이 인식하고 위치를 파악할 수 있는 것을 극적으로 확장할 수 있음을 시사한다.
초록
우리는 입력 주체(subject)에 조건화하여, 장면 속 다른 객체들과의 모든 관계 및 그 위치를 예측하는 것을 목표로 하는 Subject-Conditional Relation Detection(SCoRD)을 제안한다. Open Images 데이터셋을 기반으로, 우리는 학습 및 테스트 분할이 $\langle$주체, 관계, 객체$\rangle$ 삼중항의 발생 통계 측면에서 분포 변화를 갖도록 도전적인 OIv6-SCoRD 벤치마크를 제안한다. 이 문제를 해결하기 위해, 우리는 주체가 주어지면 그 관계, 객체, 객체 위치를 토큰의 시퀀스로 출력하여 예측하는 자기회귀(auto-regressive) 모델을 제안한다. 먼저, 우리는 이전의 scene-graph 예측 방법들이 이 벤치마크에서 주체에 조건화되었을 때 관계-객체 쌍을 충분히 망라적으로 열거하지 못함을 보인다. 특히, 우리는 관계-객체 예측에 대해 최근의 scene graph 탐지기가 얻은 49.75%와 비교하여 recall@3 83.8%를 얻는다. 다음으로, 우리는 학습 중에 텍스트 캡션으로부터 자동으로 얻어지며 객체 박스 주석이 없는 관계-객체 쌍을 활용함으로써 관계-객체 및 객체-박스 예측 모두에서 향상된 일반화를 보인다. 특히, 학습 중에 객체 위치를 사용할 수 없는 $\langle$주체, 관계, 객체$\rangle$ 삼중항에 대해, 우리는 관계-객체 쌍에 대해 recall@3 33.80%, 그리고 그 박스 위치에 대해 26.75%를 얻을 수 있다.
세부 정보
인용
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
- SCoRD란 무엇인가? SCoRD는 모델이 이미지 속 선택된 주체를 받아 그 주체의 관계, 관련 객체, 그리고 객체 위치를 예측하는 주체 조건적 관계 탐지 작업이다.
- SCoRD는 전체 scene graph 생성과 어떻게 다른가? 모든 객체 간의 모든 관계를 예측하는 대신, SCoRD는 질의된 하나의 주체의 관계를 망라적으로 기술하는 데 초점을 맞추며, 이는 다운스트림 응용에 종종 더 실용적이다.
- SCoRDNet이란 무엇인가? SCoRDNet은 관계-객체 예측과 경계 상자 좌표를 토큰의 시퀀스로 표현하는 자기회귀 vision-language 모델이다.
- 텍스트로 보강된 데이터를 사용하는 이유는 무엇인가? 캡션에서 유도된 관계-객체 삼중항은 캡션이 객체 박스 주석을 포함하지 않더라도 드물거나 보지 못한 관계에 대해 확장 가능한 지도(supervision)를 제공한다.
- OIv6-SCoRD 벤치마크는 무엇을 테스트하는가? 이 벤치마크는 주체-관계-객체 삼중항에서 학습-테스트 분포 변화를 만들어, 암기된 관계 통계를 넘어선 일반화를 강하게 시험한다.
주요 기여
- 본 논문은 Subject-Conditional Relation Detection을 지정된 객체의 관계를 기술하기 위한, 전체 scene graph 생성에 대한 초점화된 대안으로 정의한다.
- 본 논문은 관계-객체 통계의 분포 변화 하에서 관계 탐지를 스트레스 테스트하도록 설계된 벤치마크인 OIv6-SCoRD를 도입한다.
- SCoRDNet은 관계, 객체, 위치 추정 예측을 통합된 토큰 디코딩 문제로 변환하여, grounding된 지도와 grounding되지 않은 지도를 하나의 모델에서 처리할 수 있게 한다.
- 본 논문은 캡션으로부터의 텍스트 보강 학습이 과소 대표되거나 보지 못한 관계-객체 쌍에 대한 일반화를 상당히 향상시킴을 보인다.
- SCoRDNet은 관계-객체 예측에서 scene graph 방법의 주체 조건적 적응을 능가하며, grounding되지 않은 캡션이 관계 예측과 객체 위치 추정을 모두 향상시킬 수 있음을 입증한다.
한계 및 유의 사항
- SCoRD는 주체와 그 박스가 입력으로 제공된다고 가정하는데, 이는 작업을 초점화된 상태로 유지하고 사용자나 상위 탐지기가 관심 객체를 식별하는 응용에 적합하게 만든다.
- 캡션에서 유도된 관계 삼중항은 잡음이 많고 종종 객체 박스가 없지만, 본 논문은 이 약한 신호가 grounding된 데이터와 결합될 때 여전히 일반화를 향상시킴을 보임으로써 이를 강점으로 전환한다.
- 이 방법은 Open Images와 COCO 및 Conceptual Captions 같은 캡션 출처에서 유도된 벤치마크에서 평가되어, 더 넓은 open-world 이미지 모음을 자연스러운 다음 시험으로 남겨둔다.
- SCoRDNet은 특화된 박스 정제 대신 시퀀스 디코딩을 통해 박스를 예측하는데, 이는 더 강한 위치 추정 모듈과의 향후 결합 여지를 남긴다.
- 이 작업은 완전한 scene graph가 아니라 주체 중심 관계에 초점을 맞추어, 더 넓은 그래프 생성 시스템을 보완하면서 실용적이고 확장 가능한 정식화를 제공한다.
이 결과를 읽는 방법
본 논문은 확장 가능한 시각적 관계 이해를 향한 강력한 진전으로 읽는 것이 가장 좋다: SCoRD는 관계 탐지를 질의된 주체를 중심으로 재구성하고, SCoRDNet은 저렴한 캡션 지도가 모델이 인식하고 위치를 파악할 수 있는 관계-객체 쌍을 의미 있게 확장할 수 있음을 보여준다.