SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data
Sintesi del comunicato stampa
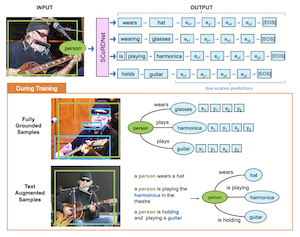
I ricercatori della Rice University e di Adobe Research hanno sviluppato un sistema chiamato SCoRD — abbreviazione di Subject-Conditional Relation Detection — che, dato un oggetto specifico in una foto, identifica automaticamente tutto ciò con cui quell'oggetto interagisce, quali sono tali interazioni e dove si trovano gli altri oggetti nell'immagine. Invece di tentare di mappare ogni possibile relazione tra ogni oggetto di una scena, cosa che diventa rapidamente impraticabile, il sistema si concentra su un singolo soggetto scelto e cataloga in modo esaustivo solo le sue connessioni rilevanti. Il team ha costruito il proprio modello, SCoRDNet, come un decoder di sequenze auto-regressivo che produce in output coppie relazione-oggetto insieme alle coordinate dei bounding box sotto forma di flusso di token, e ha progettato un benchmark basato sul dataset Open Images appositamente concepito in modo che i dati di training e di testing abbiano statistiche delle relazioni disallineate — rendendo più difficile per un modello memorizzare semplicemente i pattern comuni. Una scoperta chiave è che le prestazioni del sistema sui tipi di relazione rari o mai visti in precedenza sono migliorate sostanzialmente quando l'addestramento è stato integrato con triplette di relazioni rumorose estratte automaticamente dalle didascalie delle immagini, anche quando tali didascalie non erano affatto corredate di annotazioni con bounding box. Sulle relazioni che il modello di base non aveva mai incontrato durante l'addestramento, la versione arricchita con testo ha raggiunto un recall del 33.8% per le coppie relazione-oggetto e del 26.75% per le posizioni dei loro box, rispetto a un valore quasi nullo per la baseline non assistita. Il lavoro è importante perché offre un percorso più scalabile verso la rilevazione di relazioni a vocabolario aperto: invece di richiedere costosi dataset completamente annotati per ogni possibile interazione, l'approccio suggerisce che le grandi raccolte di immagini con didascalie già presenti su internet potrebbero ampliare drasticamente ciò che tali sistemi sono in grado di riconoscere e localizzare.
abstract
Proponiamo la Subject-Conditional Relation Detection SCoRD, dove, condizionatamente a un soggetto di input, l'obiettivo è prevedere tutte le sue relazioni con gli altri oggetti di una scena insieme alle loro posizioni. Sulla base del dataset Open Images, proponiamo un impegnativo benchmark OIv6-SCoRD tale che gli split di training e di testing presentino uno shift di distribuzione in termini di statistiche di occorrenza delle triplette $\langle$soggetto, relazione, oggetto$\rangle$. Per risolvere questo problema, proponiamo un modello auto-regressivo che, dato un soggetto, ne prevede le relazioni, gli oggetti e le posizioni degli oggetti rappresentando questo output come una sequenza di token. In primo luogo, mostriamo che i precedenti metodi di predizione di scene graph non riescono a produrre un'enumerazione altrettanto esaustiva di coppie relazione-oggetto quando condizionati a un soggetto su questo benchmark. In particolare, otteniamo un recall@3 dell'83.8% per le nostre predizioni relazione-oggetto rispetto al 49.75% ottenuto da un recente rilevatore di scene graph. Successivamente, mostriamo una migliore generalizzazione sia nelle predizioni relazione-oggetto sia in quelle oggetto-box sfruttando durante l'addestramento coppie relazione-oggetto ottenute automaticamente da didascalie testuali e per le quali non sono disponibili annotazioni di object-box. In particolare, per le triplette $\langle$soggetto, relazione, oggetto$\rangle$ per le quali non sono disponibili posizioni degli oggetti durante l'addestramento, siamo in grado di ottenere un recall@3 del 33.80% per le coppie relazione-oggetto e del 26.75% per le posizioni dei loro box.
dettagli
citazione
@inproceedings{yang2024scord,
title = {SCoRD: Subject-Conditional Relation Detection with Text-Augmented Data},
author = {Yang, Ziyan and Kafle, Kushal and Lin, Zhe and Cohen, Scott and Ding, Zhihong and Ordonez, Vicente},
year = {2024},
booktitle = {Winter Conference on Applications of Computer Vision WACV 2024},
url = {https://arxiv.org/abs/2308.12910},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Che cos'è SCoRD? SCoRD è un task di subject-conditional relation detection in cui un modello riceve un soggetto scelto in un'immagine e prevede le relazioni di quel soggetto, gli oggetti correlati e le posizioni degli oggetti.
- In che modo SCoRD si differenzia dalla generazione completa di scene graph? Invece di prevedere ogni relazione tra ogni oggetto, SCoRD si concentra sul descrivere in modo esaustivo le relazioni di un singolo soggetto interrogato, cosa spesso più pratica per le applicazioni a valle.
- Che cos'è SCoRDNet? SCoRDNet è un modello vision-language autoregressivo che rappresenta le predizioni relazione-oggetto e le coordinate dei bounding box come una sequenza di token.
- Perché usare dati arricchiti con testo? Le triplette relazione-oggetto derivate dalle didascalie forniscono una supervisione scalabile per le relazioni rare o mai viste, anche quando le didascalie non includono annotazioni con bounding box.
- Cosa mette alla prova il benchmark OIv6-SCoRD? Il benchmark crea shift di distribuzione tra training e testing nelle triplette soggetto-relazione-oggetto, rendendolo un forte test di generalizzazione al di là delle statistiche di relazione memorizzate.
Principali contributi
- Il paper definisce la Subject-Conditional Relation Detection come un'alternativa mirata alla generazione completa di scene graph per descrivere le relazioni di un oggetto specificato.
- Introduce OIv6-SCoRD, un benchmark progettato per mettere sotto stress la rilevazione di relazioni in presenza di shift di distribuzione nelle statistiche relazione-oggetto.
- SCoRDNet imposta la predizione di relazione, oggetto e localizzazione come un problema unificato di decoding di token, consentendo di gestire in un unico modello la supervisione ancorata e quella non ancorata.
- Il paper mostra che l'addestramento arricchito con testo a partire dalle didascalie migliora sostanzialmente la generalizzazione verso coppie relazione-oggetto sottorappresentate e mai viste.
- SCoRDNet supera gli adattamenti subject-conditioned dei metodi di scene graph nella predizione relazione-oggetto e dimostra che le didascalie non ancorate possono migliorare sia la predizione delle relazioni sia la localizzazione degli oggetti.
Limiti e avvertenze
- SCoRD presuppone che un soggetto e il suo box siano forniti come input, il che mantiene il task focalizzato e lo rende ben adatto ad applicazioni in cui un utente o un rilevatore a monte identifica l'oggetto di interesse.
- Le triplette di relazioni derivate dalle didascalie sono rumorose e spesso prive di box degli oggetti, ma il paper trasforma questo segnale debole in un punto di forza mostrando che migliora comunque la generalizzazione quando combinato con dati ancorati.
- Il metodo viene valutato su un benchmark derivato da Open Images e da fonti di didascalie come COCO e Conceptual Captions, lasciando le più ampie raccolte di immagini open-world come naturali test successivi.
- SCoRDNet prevede i box attraverso il decoding di sequenze anziché tramite un raffinamento specializzato dei box, il che lascia spazio a future combinazioni con moduli di localizzazione più potenti.
- Il task si concentra sulle relazioni centrate sul soggetto anziché sui scene graph completi, offrendo una formulazione pratica e scalabile e complementando al contempo i più ampi sistemi di generazione di grafi.
Come interpretare questo risultato
Questo paper si legge al meglio come un solido passo verso una comprensione scalabile delle relazioni visive: SCoRD riformula la rilevazione di relazioni attorno a un soggetto interrogato, e SCoRDNet mostra che una supervisione economica basata sulle didascalie può ampliare in modo significativo le coppie relazione-oggetto che un modello è in grado di riconoscere e localizzare.