Grounding Language Models for Visual Entity Recognition
Resumen de prensa
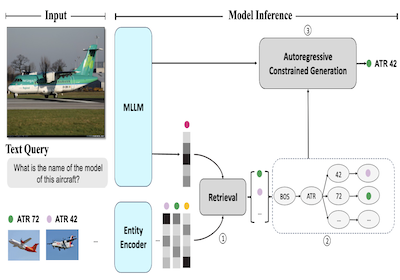
Investigadores de la Universidad Rice y Microsoft han desarrollado un sistema llamado AutoVER que mejora drásticamente la capacidad de una computadora para identificar entidades específicas del mundo real en imágenes —pensemos en distinguir un modelo concreto de avión de otro casi idéntico— anclando las conjeturas de un modelo de lenguaje de IA a una base de conocimiento concreta en lugar de dejar que genere cualquier respuesta que parezca plausible. El problema central es que los sistemas de IA multimodales existentes, que procesan tanto imágenes como texto, tienden a alucinar o producir respuestas con un nivel de especificidad equivocado cuando se les hacen preguntas de reconocimiento de grano fino, como identificar si una aeronave fotografiada es un ATR 42 frente a un British Aerospace 146. AutoVER aborda esto combinando dos técnicas: entrena al modelo para recuperar entidades candidatas visual y semánticamente similares de una base de datos de más de seis millones de entradas de Wikipedia usando un enfoque de aprendizaje contrastivo, y luego, durante la generación de la respuesta, restringe la salida del modelo solo a esas candidatas recuperadas construyendo un árbol de prefijos que bloquea cualquier secuencia de tokens que conduzca a respuestas no válidas. El sistema se probó en el benchmark Oven-Wiki, un conjunto de datos a gran escala diseñado específicamente para este tipo de reto de reconocimiento de entidades visuales, donde elevó la precisión en entidades que el modelo había visto durante el entrenamiento de alrededor del 32,7 por ciento al 61,5 por ciento, a la vez que superaba a modelos mucho más grandes como PaLI-17B de Google en ejemplos que implicaban entidades no vistas y preguntas que requerían razonamiento visual. El trabajo es importante porque el reconocimiento fiable de entidades a partir de imágenes tiene aplicaciones prácticas en áreas que van desde los motores de búsqueda hasta las herramientas de accesibilidad, y el enfoque demuestra que acoplar estrechamente la recuperación con la generación restringida es un camino más fiable que simplemente escalar un modelo y confiar en que acierte respuestas lo bastante específicas.
resumen
Presentamos AutoVER, un modelo autorregresivo para el reconocimiento de entidades visuales (Autoregressive model for Visual Entity Recognition). Nuestro modelo amplía un modelo de lenguaje grande multimodal y autorregresivo empleando generación restringida aumentada con recuperación. Mitiga el bajo rendimiento en entidades fuera de dominio a la vez que destaca en consultas que requieren razonamiento situado visualmente. Nuestro método aprende a distinguir entidades similares dentro de un vasto espacio de etiquetas entrenando de forma contrastiva sobre pares negativos difíciles en paralelo con un objetivo de secuencia a secuencia, sin un recuperador externo. Durante la inferencia, una lista de respuestas candidatas recuperadas guía explícitamente la generación de lenguaje eliminando rutas de decodificación no válidas. El método propuesto logra mejoras significativas en distintas particiones del conjunto de datos en el benchmark Oven-Wiki, recientemente propuesto. La precisión en la partición de entidades vistas (Entity seen) sube del 32,7 % al 61,5 %. También demuestra un rendimiento superior en las particiones de entidades no vistas y de consultas por un margen sustancial de dos dígitos.
detalles
cita
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué es AutoVER? AutoVER es un modelo de lenguaje multimodal autorregresivo para el reconocimiento de entidades visuales, donde las respuestas deben anclarse a entidades específicas dentro de una gran base de conocimiento.
- ¿Qué problema aborda el artículo? Aborda el reconocimiento de entidades de grano fino basado en imágenes, donde los modelos deben distinguir entidades visualmente similares y evitar alucinar respuestas fuera del espacio de entidades válido.
- ¿Cómo funciona aquí la generación restringida aumentada con recuperación? AutoVER recupera entidades probables, construye un árbol de prefijos dinámico a partir de esas candidatas y restringe la decodificación de modo que la generación siga únicamente rutas de tokens válidas de nombres de entidades.
- ¿Por qué usar aprendizaje contrastivo y negativos difíciles? El modelo aprende la recuperación de consulta a entidad con negativos difíciles similares visualmente y en conocimiento, lo que le ayuda a separar entidades que comparten apariencia o estructura de categoría.
- ¿Dónde se evalúa AutoVER? El artículo evalúa en Oven-Wiki y también prueba la transferencia sin entrenamiento previo (zero-shot) en un subconjunto de A-OKVQA anclado a entidades.
Contribuciones principales
- El artículo introduce AutoVER, un marco autorregresivo aumentado con recuperación para anclar las salidas de un modelo de lenguaje multimodal a entidades visuales a escala de Wikipedia.
- Integra el entrenamiento contrastivo de consulta a entidad directamente en el modelo de lenguaje multimodal, evitando la dependencia de un recuperador externo separado.
- El mecanismo de decodificación restringida garantiza que las respuestas generadas estén ancladas en las entidades candidatas recuperadas, reduciendo directamente las generaciones no válidas o sin anclaje.
- La minería de negativos difíciles a partir de la similitud visual y la jerarquía de la base de conocimiento mejora la discriminación de grano fino entre entidades visualmente similares.
- AutoVER mejora sustancialmente el rendimiento en Oven-Wiki, incluido el aumento de la precisión en entidades vistas (Entity seen) del 32,7 % al 61,5 % en la comparación reportada, y supera a líneas base PaLI más grandes en las particiones de entidades no vistas y de consultas.
Limitaciones y advertencias
- AutoVER depende de la cobertura y la calidad de la base de conocimiento de entidades, lo cual es apropiado para el reconocimiento de entidades visuales y hace explícito el objetivo de anclaje.
- El método recupera un conjunto de candidatas antes de la decodificación restringida, por lo que las entidades muy raras o visualmente ambiguas siguen siendo un reto cuando la recuperación las pasa por alto; el artículo aborda esto directamente con características visuales del lado de la entidad y entrenamiento con negativos difíciles.
- El entrenamiento a escala de Wikipedia requiere datos y cómputo sustanciales, pero el resultado es un marco práctico para convertir grandes bases de conocimiento en objetivos de reconocimiento visual utilizables.
- El artículo aún muestra una brecha respecto al rendimiento de humanos con búsqueda en el conjunto de evaluación humana, lo que constituye un benchmark útil para el progreso futuro más que una debilidad del enfoque central.
- AutoVER está especializado en respuestas ancladas a entidades, complementando a los sistemas de VQA abiertos más generales cuando la salida deseada debe ser una entidad nombrada precisa.
Cómo interpretar este resultado
Este artículo se lee mejor como una sólida contribución al reconocimiento multimodal anclado: AutoVER muestra que la recuperación, el aprendizaje contrastivo de entidades y la generación restringida pueden hacer que las respuestas de un modelo de lenguaje sean mucho más precisas y fiables para el reconocimiento de entidades visuales a escala de Wikipedia.