Grounding Language Models for Visual Entity Recognition
Resumo do comunicado de imprensa
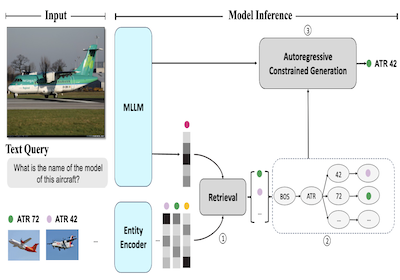
Pesquisadores da Rice University e da Microsoft desenvolveram um sistema chamado AutoVER que melhora drasticamente a capacidade de um computador de identificar entidades específicas do mundo real em imagens — pense em distinguir um modelo específico de avião de outro quase idêntico — ancorando os palpites de um modelo de linguagem de IA a uma base de conhecimento concreta, em vez de deixá-lo gerar qualquer resposta que pareça plausível. O problema central é que os sistemas de IA multimodais existentes, que processam tanto imagens quanto texto, tendem a alucinar ou a produzir respostas com o nível errado de especificidade quando lhes são feitas perguntas de reconhecimento de granularidade fina, como identificar se uma aeronave retratada é um ATR 42 ou um British Aerospace 146. O AutoVER aborda isso combinando duas técnicas: ele treina o modelo para recuperar entidades candidatas visual e semanticamente semelhantes de um banco de dados com mais de seis milhões de entradas da Wikipédia usando uma abordagem de aprendizado contrastivo, e então, durante a geração da resposta, restringe a saída do modelo apenas a esses candidatos recuperados construindo uma árvore de prefixos que bloqueia quaisquer sequências de tokens que levariam a respostas inválidas. O sistema foi testado no benchmark Oven-Wiki, um conjunto de dados em larga escala especificamente projetado para esse tipo de desafio de reconhecimento de entidades visuais, no qual elevou a acurácia em entidades que o modelo havia visto durante o treinamento de cerca de 32,7 por cento para 61,5 por cento, ao mesmo tempo em que também superou modelos muito maiores, como o PaLI-17B do Google, em exemplos envolvendo entidades não vistas e perguntas que exigem raciocínio visual. O trabalho é importante porque o reconhecimento confiável de entidades a partir de imagens tem aplicações práticas em áreas que vão de mecanismos de busca a ferramentas de acessibilidade, e a abordagem demonstra que acoplar fortemente a recuperação à geração restrita é um caminho mais confiável do que simplesmente aumentar a escala de um modelo e torcer para que ele acerte respostas suficientemente específicas.
resumo
Apresentamos o AutoVER, um modelo Autorregressivo para Reconhecimento de Entidades Visuais. Nosso modelo estende um Modelo de Linguagem de Grande Escala Multimodal autorregressivo empregando geração restrita aumentada por recuperação. Ele mitiga o baixo desempenho em entidades fora do domínio, ao mesmo tempo em que se destaca em consultas que exigem raciocínio visualmente situado. Nosso método aprende a distinguir entidades semelhantes dentro de um vasto espaço de rótulos treinando contrastivamente em pares de negativos difíceis em paralelo com um objetivo de sequência para sequência sem um recuperador externo. Durante a inferência, uma lista de respostas candidatas recuperadas guia explicitamente a geração de linguagem removendo caminhos de decodificação inválidos. O método proposto alcança melhorias significativas em diferentes divisões de conjuntos de dados no recém-proposto benchmark Oven-Wiki. A acurácia na divisão de Entidades vistas sobe de 32,7% para 61,5%. Ele também demonstra desempenho superior nas divisões de entidades não vistas e de consultas por uma margem substancial de dois dígitos.
detalhes
citação
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
perguntas, principais contribuições e limitações deste artigo geradas automaticamente
Perguntas que este artigo ajuda a responder
- O que é o AutoVER? O AutoVER é um modelo de linguagem multimodal autorregressivo para reconhecimento de entidades visuais, no qual as respostas devem estar ancoradas a entidades específicas em uma grande base de conhecimento.
- Que problema o artigo aborda? Ele enfrenta o reconhecimento de entidades baseado em imagens de granularidade fina, no qual os modelos devem distinguir entidades visualmente semelhantes e evitar alucinar respostas fora do espaço válido de entidades.
- Como a geração restrita aumentada por recuperação funciona aqui? O AutoVER recupera entidades prováveis, constrói uma árvore de prefixos dinâmica a partir desses candidatos e restringe a decodificação para que a geração siga apenas caminhos de tokens de nomes de entidades válidos.
- Por que usar aprendizado contrastivo e negativos difíceis? O modelo aprende a recuperação de consulta para entidade com negativos difíceis semelhantes visualmente e em termos de conhecimento, ajudando-o a separar entidades que compartilham aparência ou estrutura de categoria.
- Onde o AutoVER é avaliado? O artigo avalia no Oven-Wiki e também testa a transferência zero-shot em um subconjunto do A-OKVQA ancorado em entidades.
Principais contribuições
- O artigo introduz o AutoVER, um framework autorregressivo aumentado por recuperação para ancorar as saídas de modelos de linguagem multimodais a entidades visuais em escala da Wikipédia.
- Ele integra o treinamento contrastivo de consulta para entidade diretamente no modelo de linguagem multimodal, evitando a dependência de um recuperador externo separado.
- O mecanismo de decodificação restrita garante que as respostas geradas estejam ancoradas em entidades candidatas recuperadas, reduzindo diretamente gerações inválidas ou não ancoradas.
- A mineração de negativos difíceis a partir da similaridade visual e da hierarquia da base de conhecimento melhora a discriminação de granularidade fina entre entidades visualmente semelhantes.
- O AutoVER melhora substancialmente o desempenho no Oven-Wiki, incluindo o aumento da acurácia de Entidades vistas de 32,7% para 61,5% na comparação relatada e a superação de bases PaLI maiores nas divisões de entidades não vistas e de consultas.
Limitações e ressalvas
- O AutoVER depende da cobertura e da qualidade da base de conhecimento de entidades, o que é apropriado para o reconhecimento de entidades visuais e torna o alvo de ancoragem explícito.
- O método recupera um conjunto de candidatos antes da decodificação restrita, de modo que entidades muito raras ou visualmente ambíguas permanecem desafiadoras quando a recuperação as ignora; o artigo aborda isso diretamente com características visuais do lado da entidade e treinamento com negativos difíceis.
- Treinar em escala da Wikipédia requer dados e computação substanciais, mas o resultado é um framework prático para transformar grandes bases de conhecimento em alvos de reconhecimento visual utilizáveis.
- O artigo ainda mostra uma lacuna em relação ao desempenho humano combinado com busca no conjunto de avaliação humana, o que é um benchmark útil para o progresso futuro, e não uma fraqueza da abordagem central.
- O AutoVER é especializado em respostas ancoradas em entidades, complementando sistemas de VQA de domínio aberto mais amplos quando a saída desejada deve ser uma entidade nomeada precisa.
Como interpretar este resultado
Este artigo é melhor compreendido como uma forte contribuição para o reconhecimento multimodal ancorado: o AutoVER mostra que a recuperação, o aprendizado contrastivo de entidades e a geração restrita podem tornar as respostas de modelos de linguagem muito mais precisas e confiáveis para o reconhecimento de entidades visuais em escala da Wikipédia.