Grounding Language Models for Visual Entity Recognition
Résumé du communiqué de presse
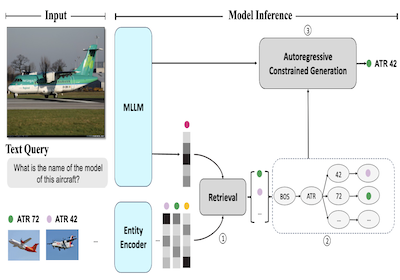
Des chercheurs de Rice University et de Microsoft ont mis au point un système appelé AutoVER qui améliore considérablement la capacité d'un ordinateur à identifier des entités spécifiques du monde réel dans des images — par exemple distinguer un modèle d'avion particulier d'un autre presque identique — en ancrant les suppositions d'un modèle de langage d'IA à une base de connaissances concrète plutôt que de le laisser générer n'importe quelle réponse qui semble plausible. Le problème central est que les systèmes d'IA multimodaux existants, qui traitent à la fois les images et le texte, ont tendance à halluciner ou à produire des réponses au mauvais niveau de précision lorsqu'on leur pose des questions de reconnaissance fine, comme déterminer si un avion en photo est un ATR 42 ou un British Aerospace 146. AutoVER s'attaque à cela en combinant deux techniques : il entraîne le modèle à récupérer des entités candidates visuellement et sémantiquement similaires à partir d'une base de données de plus de six millions d'entrées Wikipédia au moyen d'une approche d'apprentissage contrastif, puis, lors de la génération de la réponse, il restreint la sortie du modèle à ces seuls candidats récupérés en construisant un arbre de préfixes qui bloque toute séquence de jetons menant à des réponses invalides. Le système a été testé sur le banc d'essai Oven-Wiki, un jeu de données à grande échelle spécifiquement conçu pour ce type de défi de reconnaissance d'entités visuelles, où il a fait passer la précision sur les entités que le modèle avait vues à l'entraînement d'environ 32,7 pour cent à 61,5 pour cent, tout en surpassant des modèles bien plus grands comme le PaLI-17B de Google sur des exemples impliquant des entités inédites et des questions nécessitant un raisonnement visuel. Ce travail est important car la reconnaissance fiable d'entités à partir d'images a des applications pratiques dans des domaines allant des moteurs de recherche aux outils d'accessibilité, et l'approche démontre que coupler étroitement la récupération avec une génération contrainte est une voie plus fiable que de simplement agrandir un modèle en espérant qu'il fournisse des réponses suffisamment précises.
résumé
Nous présentons AutoVER, un modèle autorégressif pour la reconnaissance d'entités visuelles. Notre modèle étend un grand modèle de langage multimodal autorégressif en employant une génération contrainte augmentée par récupération. Il atténue les faibles performances sur les entités hors domaine tout en excellant dans les requêtes nécessitant un raisonnement ancré visuellement. Notre méthode apprend à distinguer des entités similaires au sein d'un vaste espace d'étiquettes en s'entraînant de manière contrastive sur des paires de négatifs difficiles, en parallèle d'un objectif séquence-à-séquence et sans dispositif de récupération externe. Lors de l'inférence, une liste de réponses candidates récupérées guide explicitement la génération de langage en supprimant les chemins de décodage invalides. La méthode proposée obtient des améliorations significatives sur différentes partitions de jeux de données dans le banc d'essai Oven-Wiki récemment proposé. La précision sur la partition des entités vues passe de 32,7% à 61,5%. Elle démontre également des performances supérieures sur les partitions inédites et de requêtes, avec une marge substantielle à deux chiffres.
détails
citation
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Qu'est-ce qu'AutoVER ? AutoVER est un modèle de langage multimodal autorégressif pour la reconnaissance d'entités visuelles, où les réponses doivent être ancrées à des entités spécifiques d'une vaste base de connaissances.
- Quel problème l'article aborde-t-il ? Il s'attaque à la reconnaissance fine d'entités à partir d'images, où les modèles doivent distinguer des entités visuellement similaires et éviter d'halluciner des réponses en dehors de l'espace d'entités valide.
- Comment fonctionne ici la génération contrainte augmentée par récupération ? AutoVER récupère les entités probables, construit un arbre de préfixes dynamique à partir de ces candidats, et contraint le décodage afin que la génération ne suive que les chemins de jetons de noms d'entités valides.
- Pourquoi utiliser l'apprentissage contrastif et les négatifs difficiles ? Le modèle apprend la récupération requête-vers-entité avec des négatifs difficiles similaires visuellement et au sein de la base de connaissances, ce qui l'aide à séparer les entités partageant une apparence ou une structure de catégorie.
- Où AutoVER est-il évalué ? L'article l'évalue sur Oven-Wiki et teste également le transfert zero-shot sur un sous-ensemble d'A-OKVQA ancré sur des entités.
Principales contributions
- L'article présente AutoVER, un cadre autorégressif augmenté par récupération pour ancrer les sorties d'un modèle de langage multimodal à des entités visuelles à l'échelle de Wikipédia.
- Il intègre l'entraînement contrastif requête-vers-entité directement dans le modèle de langage multimodal, évitant la dépendance à un dispositif de récupération externe distinct.
- Le mécanisme de décodage contraint garantit que les réponses générées sont ancrées dans les entités candidates récupérées, réduisant directement les générations invalides ou non ancrées.
- L'extraction de négatifs difficiles à partir de la similarité visuelle et de la hiérarchie de la base de connaissances améliore la discrimination fine entre entités visuellement similaires.
- AutoVER améliore substantiellement les performances sur Oven-Wiki, faisant notamment passer la précision sur les entités vues de 32,7% à 61,5% dans la comparaison rapportée et surpassant des références PaLI plus grandes sur les partitions inédites et de requêtes.
Limites et mises en garde
- AutoVER dépend de la couverture et de la qualité de la base de connaissances d'entités, ce qui est approprié pour la reconnaissance d'entités visuelles et rend explicite la cible d'ancrage.
- La méthode récupère un ensemble de candidats avant le décodage contraint, de sorte que les entités très rares ou visuellement ambiguës restent difficiles lorsque la récupération les manque ; l'article aborde cela directement avec des caractéristiques visuelles côté entité et un entraînement par négatifs difficiles.
- L'entraînement à l'échelle de Wikipédia nécessite des données et une puissance de calcul substantielles, mais le résultat est un cadre pratique pour transformer de grandes bases de connaissances en cibles de reconnaissance visuelle exploitables.
- L'article montre encore un écart par rapport à la performance d'un humain assisté de la recherche sur l'ensemble d'évaluation humaine, ce qui constitue un repère utile pour les progrès futurs plutôt qu'une faiblesse de l'approche centrale.
- AutoVER est spécialisé pour les réponses ancrées sur des entités, complétant les systèmes de questions-réponses visuelles ouverts plus larges lorsque la sortie souhaitée doit être une entité nommée précise.
Comment interpréter ce résultat
Cet article se lit au mieux comme une contribution solide à la reconnaissance multimodale ancrée : AutoVER montre que la récupération, l'apprentissage contrastif d'entités et la génération contrainte peuvent rendre les réponses des modèles de langage bien plus précises et dignes de confiance pour la reconnaissance d'entités visuelles à l'échelle de Wikipédia.