보도 자료 요약
라이스 대학교와 Microsoft의 연구진은 AI 언어 모델의 추측을 그럴듯해 보이는 답변을 무엇이든 생성하게 두는 대신 구체적인 지식 베이스에 고정함으로써, 이미지 속 특정 실세계 개체를 식별하는 — 예컨대 거의 동일한 비행기 모델 하나를 다른 것과 구별하는 — 컴퓨터의 능력을 극적으로 향상시키는 AutoVER라는 시스템을 개발했다. 핵심 문제는 이미지와 텍스트를 모두 처리하는 기존 멀티모달 AI 시스템이 사진 속 항공기가 ATR 42인지 British Aerospace 146인지 식별하는 것과 같은 세밀한 인식 질문을 받을 때 환각을 일으키거나 잘못된 수준의 구체성으로 답변을 생성하는 경향이 있다는 점이다. AutoVER는 두 가지 기법을 결합하여 이를 해결한다. 즉, 대조 학습 접근법을 사용하여 600만 개가 넘는 Wikipedia 항목 데이터베이스에서 시각적·의미적으로 유사한 후보 개체를 검색하도록 모델을 학습시키고, 그런 다음 답변 생성 중에는 유효하지 않은 답변으로 이어질 토큰 시퀀스를 차단하는 접두사 트리(prefix tree)를 구축하여 모델의 출력을 검색된 후보로만 제한한다. 이 시스템은 이런 종류의 시각적 개체 인식 과제를 위해 특별히 설계된 대규모 데이터셋인 Oven-Wiki 벤치마크에서 테스트되었는데, 학습 중에 본 개체에 대한 정확도를 약 32.7%에서 61.5%로 끌어올리는 한편, 보지 못한 개체와 시각적 추론을 요구하는 예제에서는 Google의 PaLI-17B와 같은 훨씬 더 큰 모델들을 능가했다. 이 연구가 중요한 이유는 이미지로부터의 신뢰할 수 있는 개체 인식이 검색 엔진에서 접근성 도구에 이르는 분야에서 실용적인 응용을 갖기 때문이며, 이 접근법은 검색과 제약 생성을 긴밀하게 결합하는 것이 단순히 모델을 키우고 충분히 구체적인 답변을 맞히기를 바라는 것보다 더 신뢰할 수 있는 길임을 입증한다.
초록
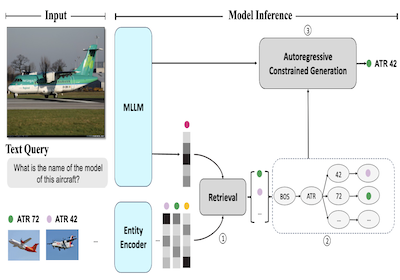
우리는 시각적 개체 인식(Visual Entity Recognition)을 위한 자기회귀 모델인 AutoVER를 소개한다. 우리 모델은 검색 증강 제약 생성(retrieval augmented constrained generation)을 사용하여 자기회귀 멀티모달 대규모 언어 모델을 확장한다. 이는 시각적으로 위치한 추론을 요구하는 질의에서 뛰어난 성능을 보이는 한편, 도메인 외 개체에 대한 낮은 성능을 완화한다. 우리 방법은 외부 검색기 없이 시퀀스-투-시퀀스 목표와 병행하여 어려운 음성 쌍(hard negative pairs)에 대해 대조 학습함으로써 방대한 레이블 공간 내에서 유사한 개체를 구별하는 법을 학습한다. 추론 중에는 검색된 후보 답변 목록이 유효하지 않은 디코딩 경로를 제거함으로써 언어 생성을 명시적으로 안내한다. 제안된 방법은 최근 제안된 Oven-Wiki 벤치마크의 여러 데이터셋 분할에 걸쳐 상당한 개선을 달성한다. Entity seen 분할에서의 정확도는 32.7%에서 61.5%로 상승한다. 또한 unseen 및 query 분할에서도 상당한 두 자릿수 차이로 우수한 성능을 입증한다.
세부 정보
인용
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
이 논문의 자동 생성된 질문, 주요 기여 및 한계
이 논문이 답하는 데 도움이 되는 질문
- AutoVER란 무엇인가? AutoVER는 시각적 개체 인식을 위한 자기회귀 멀티모달 언어 모델로, 답변이 대규모 지식 베이스의 특정 개체에 고정되어야 한다.
- 이 논문은 어떤 문제를 다루는가? 모델이 시각적으로 유사한 개체를 구별하고 유효한 개체 공간 밖의 답변을 환각하는 것을 피해야 하는 세밀한 이미지 기반 개체 인식을 다룬다.
- 여기서 검색 증강 제약 생성은 어떻게 작동하는가? AutoVER는 가능성 있는 개체를 검색하고, 그 후보들로부터 동적 접두사 트리를 구축하며, 생성이 유효한 개체명 토큰 경로만을 따르도록 디코딩을 제약한다.
- 왜 대조 학습과 어려운 음성(hard negatives)을 사용하는가? 모델은 시각적·지식적으로 유사한 어려운 음성을 사용하여 질의-개체 검색을 학습하며, 이는 외형이나 범주 구조를 공유하는 개체들을 분리하는 데 도움이 된다.
- AutoVER는 어디에서 평가되는가? 논문은 Oven-Wiki에서 평가하며 A-OKVQA의 개체 고정 하위 집합에 대한 제로샷 전이도 테스트한다.
주요 기여
- 본 논문은 멀티모달 언어 모델 출력을 Wikipedia 규모의 시각적 개체에 고정하기 위한 검색 증강 자기회귀 프레임워크인 AutoVER를 소개한다.
- 이는 질의-개체 대조 학습을 멀티모달 언어 모델에 직접 통합하여, 별도의 외부 검색기에 대한 의존을 피한다.
- 제약 디코딩 메커니즘은 생성된 답변이 검색된 후보 개체에 고정되도록 보장하여, 유효하지 않거나 고정되지 않은 생성을 직접적으로 줄인다.
- 시각적 유사성과 지식 베이스 계층 구조로부터의 어려운 음성 마이닝은 시각적으로 유사한 개체 간의 세밀한 구별을 향상시킨다.
- AutoVER는 보고된 비교에서 Entity seen 정확도를 32.7%에서 61.5%로 높이고 unseen 및 query 분할에서 더 큰 PaLI 기준선들을 능가하는 것을 포함하여 Oven-Wiki 성능을 상당히 향상시킨다.
한계 및 유의 사항
- AutoVER는 개체 지식 베이스의 범위와 품질에 의존하는데, 이는 시각적 개체 인식에 적합하며 고정 대상을 명시적으로 만든다.
- 이 방법은 제약 디코딩 전에 후보 집합을 검색하므로, 검색이 놓칠 경우 매우 드물거나 시각적으로 모호한 개체는 여전히 어렵다. 논문은 개체 측 시각적 특징과 어려운 음성 학습으로 이를 직접 다룬다.
- Wikipedia 규모의 학습은 상당한 데이터와 연산을 요구하지만, 그 결과는 대규모 지식 베이스를 사용 가능한 시각적 인식 대상으로 전환하는 실용적인 프레임워크이다.
- 논문은 여전히 인간 평가 집합에서 인간과 검색 결합 성능과의 격차를 보여주는데, 이는 핵심 접근법의 약점이라기보다 향후 발전을 위한 유용한 벤치마크이다.
- AutoVER는 개체 고정 답변에 특화되어 있어, 원하는 출력이 정확한 명명된 개체여야 할 때 더 폭넓은 개방형 VQA 시스템을 보완한다.
이 결과를 읽는 방법
본 논문은 고정된(grounded) 멀티모달 인식에 대한 강력한 기여로 읽는 것이 가장 적절하다. AutoVER는 검색, 대조적 개체 학습, 제약 생성이 Wikipedia 규모의 시각적 개체 인식에서 언어 모델 답변을 훨씬 더 정확하고 신뢰할 수 있게 만들 수 있음을 보여준다.