プレスリリース要約
ライス大学とMicrosoftの研究者らは、AIの言語モデルの推測を、もっともらしく見える答えを何でも生成させるのではなく、具体的な知識ベースに固定することで、画像内の特定の現実世界の実体を識別するコンピュータの能力を劇的に向上させる、AutoVERと呼ばれるシステムを開発しました。たとえば、ある特定の飛行機の機種をほぼ同一の別の機種から区別するといったことです。中心的な問題は、画像とテキストの両方を処理する既存のマルチモーダルAIシステムが、写っている航空機がATR 42なのかBritish Aerospace 146なのかを識別するといった細粒度の認識質問を尋ねられたときに、幻覚を起こしたり、誤った具体性のレベルで答えを生成したりする傾向があることです。AutoVERは2つの技術を組み合わせることでこれに取り組みます。まず、対照学習のアプローチを用いて、600万件を超えるWikipedia項目のデータベースから視覚的・意味的に類似した候補実体を検索するようモデルを訓練します。次に、回答生成時には、不正な答えにつながるトークン列をブロックする接頭辞木を構築することで、モデルの出力をそれら検索された候補のみに制限します。このシステムは、この種の視覚的実体認識の課題のために特別に設計された大規模データセットであるOven-Wikiベンチマークでテストされ、訓練中にモデルが見た実体に対する精度を約32.7パーセントから61.5パーセントへと押し上げるとともに、未知の実体や視覚推論を必要とする質問を含む事例では、GoogleのPaLI-17Bのようなはるかに大きなモデルをも上回りました。この研究が重要なのは、画像からの信頼性の高い実体認識が検索エンジンからアクセシビリティツールに至るまでの分野で実用的な応用を持つからであり、また、このアプローチは、検索と制約付き生成を緊密に結合することが、単にモデルを大規模化して十分に具体的な答えを正しく出すことを期待するよりも信頼できる道筋であることを実証しているからです。
要旨
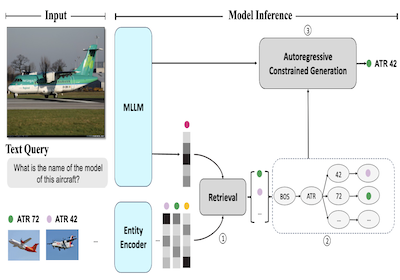
私たちは、視覚的実体認識のための自己回帰モデルであるAutoVERを紹介します。私たちのモデルは、検索拡張による制約付き生成を採用することで、自己回帰型のマルチモーダル大規模言語モデルを拡張します。これにより、ドメイン外の実体に対する低い性能を緩和しつつ、視覚的状況に基づく推論を必要とするクエリで優れた性能を発揮します。私たちの手法は、外部の検索器を用いることなく、ハードネガティブのペアに対する対照学習をシーケンス・ツー・シーケンスの目的と並行して行うことで、広大なラベル空間内の類似した実体を区別することを学習します。推論時には、検索された候補回答のリストが、不正なデコード経路を除去することによって言語生成を明示的に導きます。提案手法は、最近提案されたOven-Wikiベンチマークのさまざまなデータセット分割にわたって大幅な改善を達成します。Entity seen分割での精度は32.7%から61.5%に上昇します。また、unseenおよびquery分割でも、二桁という大きな差で優れた性能を示します。
詳細
引用
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
この論文について自動生成された質問、主な貢献、および限界
この論文が答える助けとなる質問
- AutoVERとは何ですか。AutoVERは視覚的実体認識のための自己回帰型マルチモーダル言語モデルであり、答えは大規模な知識ベース内の特定の実体にグラウンディングされなければなりません。
- この論文はどのような問題に対処しますか。細粒度の画像ベース実体認識に取り組んでおり、そこではモデルは視覚的に類似した実体を区別し、有効な実体空間の外にある答えを幻覚しないようにしなければなりません。
- ここでの検索拡張による制約付き生成はどのように機能しますか。AutoVERは可能性の高い実体を検索し、それらの候補から動的な接頭辞木を構築し、生成が有効な実体名のトークン経路のみをたどるようデコードを制約します。
- なぜ対照学習とハードネガティブを用いるのですか。モデルは視覚的および知識的に類似したハードネガティブを用いてクエリから実体への検索を学習し、外見やカテゴリ構造を共有する実体を分離するのに役立ちます。
- AutoVERはどこで評価されますか。この論文はOven-Wikiで評価するとともに、A-OKVQAの実体グラウンディングされたサブセットでのゼロショット転移もテストしています。
主な貢献
- この論文は、マルチモーダル言語モデルの出力をWikipedia規模の視覚的実体にグラウンディングするための、検索拡張型の自己回帰フレームワークであるAutoVERを導入しています。
- クエリから実体への対照学習をマルチモーダル言語モデルに直接統合し、別個の外部検索器への依存を回避しています。
- 制約付きデコード機構は、生成された答えが検索された候補実体にグラウンディングされることを保証し、不正な、またはグラウンディングされていない生成を直接的に減らします。
- 視覚的類似性と知識ベースの階層からのハードネガティブマイニングは、視覚的に類似した実体間の細粒度の識別を改善します。
- AutoVERはOven-Wikiの性能を大幅に改善し、報告された比較ではEntity seenの精度を32.7%から61.5%に高め、unseenおよびquery分割でより大きなPaLIのベースラインを上回っています。
限界と注意点
- AutoVERは実体知識ベースの網羅性と品質に依存しますが、これは視覚的実体認識にとって適切であり、グラウンディングの対象を明示的にします。
- この手法は制約付きデコードの前に候補集合を検索するため、非常に稀な、または視覚的に曖昧な実体は、検索がそれらを取りこぼした場合に依然として困難なままです。この論文は、実体側の視覚特徴とハードネガティブ訓練によってこれに直接対処しています。
- Wikipedia規模での訓練にはかなりのデータと計算資源が必要ですが、その結果は、大規模な知識ベースを利用可能な視覚認識の対象へと変える実用的なフレームワークです。
- この論文は、人間評価セットにおいて「人間+検索」の性能との差を依然として示していますが、これは中心的アプローチの弱点というよりも、将来の進歩に向けた有用なベンチマークです。
- AutoVERは実体グラウンディングされた答えに特化しており、望ましい出力が正確な固有実体であるべき場合に、より広範なオープンエンドのVQAシステムを補完します。
この結果の読み解き方
この論文は、グラウンディングされたマルチモーダル認識への力強い貢献として読むのが最適です。AutoVERは、検索、対照的な実体学習、制約付き生成によって、Wikipedia規模の視覚的実体認識において言語モデルの答えをはるかに正確で信頼できるものにできることを示しています。