Grounding Language Models for Visual Entity Recognition
Краткое изложение пресс-релиза
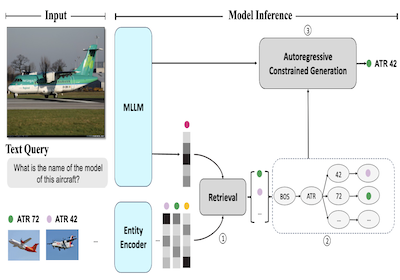
Исследователи из Rice University и Microsoft разработали систему под названием AutoVER, которая радикально улучшает способность компьютера идентифицировать конкретные реальные сущности на изображениях — например, отличать одну конкретную модель самолёта от другой, почти идентичной — путём привязки догадок AI-языковой модели к конкретной базе знаний, вместо того чтобы позволять ей генерировать любой правдоподобный ответ. Основная проблема в том, что существующие мультимодальные AI-системы, которые обрабатывают как изображения, так и текст, склонны галлюцинировать или выдавать ответы на неверном уровне конкретности, когда им задают вопросы детального распознавания, например, идентифицировать, является ли изображённый самолёт ATR 42 или British Aerospace 146. AutoVER решает это, сочетая две техники: она обучает модель извлекать визуально и семантически похожие сущности-кандидаты из базы из более чем шести миллионов записей Wikipedia с помощью подхода Contrastive Learning, а затем во время генерации ответа ограничивает вывод модели только этими извлечёнными кандидатами, строя префиксное дерево, которое блокирует любые последовательности токенов, ведущие к недопустимым ответам. Систему протестировали на бенчмарке Oven-Wiki — крупномасштабном датасете, специально разработанном для такого рода задачи распознавания визуальных сущностей, — где она подняла точность на сущностях, которые модель видела при обучении, примерно с 32,7 процента до 61,5 процента, при этом также превосходя гораздо более крупные модели, такие как PaLI-17B от Google, на примерах с невиданными ранее сущностями и на вопросах, требующих визуального рассуждения. Работа важна, поскольку надёжное распознавание сущностей на изображениях имеет практические применения в областях от поисковых систем до инструментов доступности, а подход демонстрирует, что тесная связка поиска с генерацией с ограничениями — более надёжный путь, чем просто масштабирование модели в надежде, что она достаточно точно угадает конкретные ответы.
аннотация
Мы представляем AutoVER — авторегрессионную модель для распознавания визуальных сущностей (Visual Entity Recognition). Наша модель расширяет авторегрессионную мультимодальную большую языковую модель за счёт применения дополненной поиском генерации с ограничениями. Она смягчает низкую производительность на сущностях вне домена, при этом превосходно справляясь с запросами, требующими визуально-ситуативного рассуждения. Наш метод учится различать похожие сущности в обширном пространстве меток, контрастно обучаясь на парах сложных негативов параллельно с целевой функцией sequence-to-sequence без внешнего ретривера. Во время инференса список извлечённых кандидатов-ответов явно направляет генерацию языка, удаляя недопустимые пути декодирования. Предложенный метод достигает значительных улучшений на различных сплитах датасета в недавно предложенном бенчмарке Oven-Wiki. Точность на сплите Entity seen возрастает с 32,7% до 61,5%. Он также демонстрирует превосходную производительность на сплитах unseen и query со значительным двузначным отрывом.
подробности
цитирование
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
автоматически сгенерированные вопросы, основные вклады и ограничения этой статьи
Вопросы, на которые помогает ответить эта статья
- Что такое AutoVER? AutoVER — это авторегрессионная мультимодальная языковая модель для распознавания визуальных сущностей, где ответы должны быть привязаны к конкретным сущностям в большой базе знаний.
- Какую проблему решает статья? Она решает детальное распознавание сущностей на основе изображений, где модели должны различать визуально похожие сущности и избегать галлюцинирования ответов вне допустимого пространства сущностей.
- Как здесь работает дополненная поиском генерация с ограничениями? AutoVER извлекает вероятные сущности, строит динамическое префиксное дерево из этих кандидатов и ограничивает декодирование так, чтобы генерация следовала только допустимым путям токенов имён сущностей.
- Зачем использовать Contrastive Learning и сложные негативы? Модель учится поиску от запроса к сущности с визуально и по знаниям похожими сложными негативами, что помогает ей разделять сущности, разделяющие внешний вид или категориальную структуру.
- Где оценивается AutoVER? Статья оценивает на Oven-Wiki, а также тестирует перенос в режиме zero-shot на подмножестве A-OKVQA с привязкой к сущностям.
Основные вклады
- Статья представляет AutoVER — дополненный поиском авторегрессионный фреймворк для привязки выводов мультимодальной языковой модели к визуальным сущностям масштаба Wikipedia.
- Она интегрирует контрастное обучение от запроса к сущности непосредственно в мультимодальную языковую модель, избегая зависимости от отдельного внешнего ретривера.
- Механизм декодирования с ограничениями гарантирует, что сгенерированные ответы привязаны к извлечённым сущностям-кандидатам, напрямую сокращая недопустимые или непривязанные генерации.
- Майнинг сложных негативов на основе визуального сходства и иерархии базы знаний улучшает детальное различение визуально похожих сущностей.
- AutoVER существенно улучшает производительность на Oven-Wiki, в том числе повышая точность Entity seen с 32,7% до 61,5% в приведённом сравнении и превосходя более крупные базовые модели PaLI на сплитах unseen и query.
Ограничения и предостережения
- AutoVER зависит от охвата и качества базы знаний сущностей, что уместно для распознавания визуальных сущностей и делает цель привязки явной.
- Метод извлекает набор кандидатов перед декодированием с ограничениями, поэтому очень редкие или визуально неоднозначные сущности остаются сложными, когда поиск их пропускает; статья решает это напрямую за счёт визуальных признаков на стороне сущностей и обучения на сложных негативах.
- Обучение в масштабе Wikipedia требует значительных данных и вычислений, но результатом является практичный фреймворк для превращения больших баз знаний в пригодные цели визуального распознавания.
- Статья всё же показывает отрыв от производительности человека с поиском на наборе для человеческой оценки, что является полезным бенчмарком для будущего прогресса, а не слабостью основного подхода.
- AutoVER специализирован на ответах с привязкой к сущностям, дополняя более широкие открытые VQA-системы, когда желаемый вывод должен быть точной именованной сущностью.
Как интерпретировать этот результат
Эту статью лучше всего рассматривать как сильный вклад в мультимодальное распознавание с привязкой: AutoVER показывает, что поиск, контрастное обучение сущностей и генерация с ограничениями могут сделать ответы языковой модели гораздо более точными и заслуживающими доверия для распознавания визуальных сущностей масштаба Wikipedia.