Where and Who? Automatic Semantic-Aware Person Composition
Résumé du communiqué de presse
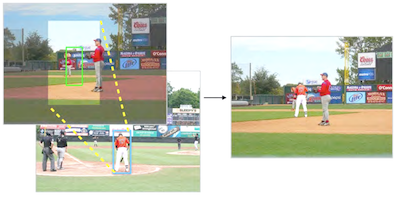
Des chercheurs de l'Université de Virginie ont construit un système capable d'insérer automatiquement une figure humaine à l'aspect réaliste dans une photographie, sans aucune intervention humaine sur l'endroit où la placer ni sur la personne à utiliser. La plupart des outils de compositing photographique existants prennent en charge le travail technique de fusion des bords et d'harmonisation des couleurs, mais laissent encore à l'utilisateur le soin de choisir un sujet de premier plan, de décider où le placer et de déterminer sa taille. Le nouveau système traite ces décisions de jugement de manière algorithmique en entraînant un réseau de neurones convolutif à branches sur des dizaines de milliers d'images annotées du jeu de données MS-COCO, lui apprenant à prédire des emplacements et des tailles plausibles pour une personne à partir de la seule scène de fond. Une fois une boîte englobante prédite, le système parcourt un ensemble d'environ 4 100 découpes de personnes segmentées manuellement, en utilisant des caractéristiques profondes issues d'un modèle ResNet50 préentraîné pour faire correspondre à la fois le type de scène global et l'environnement local immédiat, avant d'intégrer la figure choisie par matting alpha. Dans une étude utilisateur par crowdsourcing sur Amazon Mechanical Turk, les juges humains ont estimé que les composites du système étaient réels environ 44 pour cent du temps, contre environ 18 à 28 pour cent pour trois approches de référence, bien que les photographies réelles aient tout de même obtenu un score d'environ 90 pour cent. L'écart se réduit considérablement lorsque la texture et l'éclairage sont supprimés, ce qui suggère que les discordances de couleur et d'éclairage — et non le placement ou la sélection de la figure — constituent le principal obstacle restant. Les chercheurs affirment que ce travail représente une première étape vers des outils susceptibles d'assister les graphistes, les cinéastes et les concepteurs de storyboards qui consacrent actuellement un temps considérable à l'assemblage manuel de telles scènes.
résumé
Le compositing d'images est une méthode permettant de générer des images réalistes mais factices en insérant le contenu d'une image dans une autre. Les travaux antérieurs sur le compositing se sont concentrés sur l'amélioration de la compatibilité d'apparence entre un segment de premier plan sélectionné par l'utilisateur et une image de fond (c'est-à-dire la cohérence des couleurs et de l'éclairage). Dans ce travail, nous développons au contraire un modèle de compositing entièrement automatisé qui apprend en outre à sélectionner et à transformer des segments de premier plan compatibles à partir d'une vaste collection, à partir d'une seule image de fond en entrée. Pour simplifier la tâche, nous restreignons notre problème en nous concentrant sur la composition d'instances humaines, car les segments humains présentent de fortes corrélations avec leur arrière-plan et en raison de la disponibilité de grandes quantités de données annotées. Nous développons un nouveau réseau de neurones convolutif (CNN) à branches qui prédit conjointement des emplacements candidats pour la personne à partir d'une image de fond. Nous utilisons ensuite des représentations de caractéristiques profondes préentraînées pour récupérer des instances de personnes dans une grande base de données de segments. Les résultats expérimentaux montrent que notre modèle peut générer des images composites visuellement convaincantes. Nous développons également une interface utilisateur pour démontrer l'application potentielle de notre méthode.
détails
citation
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}