Where and Who? Automatic Semantic-Aware Person Composition
보도 자료 요약
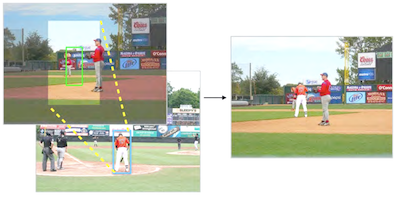
버지니아 대학교의 연구자들은 인물을 어디에 두어야 할지 또는 누구를 사용해야 할지에 대한 어떤 인간의 안내도 없이 사실적으로 보이는 인물 형상을 사진에 자동으로 떨어뜨려 넣을 수 있는 시스템을 구축했다. 기존 대부분의 사진 합성 도구는 가장자리를 섞고 색상을 맞추는 기술적 작업을 처리하지만, 전경 대상을 고르고, 어디에 배치할지 선택하고, 얼마나 크게 할지 결정하는 일은 여전히 사용자에게 맡긴다. 새로운 시스템은 MS-COCO 데이터셋의 수만 장의 주석 이미지로 분기형 합성곱 신경망을 학습시켜, 배경 장면만 주어졌을 때 인물에 대한 그럴듯한 위치와 크기를 예측하도록 가르침으로써 이러한 판단의 문제를 연산적으로 다룬다. 바운딩 박스가 예측되면, 시스템은 약 4,100개의 수작업 분할된 인물 컷아웃 풀을 탐색하는데, 사전학습된 ResNet50 모델의 심층 특징을 사용하여 전체 장면 유형과 직접적인 국소 주변 환경을 모두 매칭한 뒤 선택된 형상을 알파 매팅(alpha matting)으로 섞어 넣는다. Amazon Mechanical Turk에서의 크라우드소싱 사용자 연구에서, 인간 심사자들은 시스템의 합성물을 약 44 퍼센트의 경우 실제라고 평가했으며, 이는 세 가지 베이스라인 접근법의 대략 18에서 28 퍼센트와 대비되지만, 실제 사진은 여전히 약 90 퍼센트의 점수를 받았다. 질감과 조명을 제거하면 격차가 상당히 좁혀지는데, 이는 배치나 형상 선택이 아니라 색상과 조명의 불일치가 남아 있는 주요 장애물임을 시사한다. 연구자들은 이 연구가 현재 그러한 장면을 수작업으로 조립하는 데 상당한 시간을 쓰는 그래픽 디자이너, 영화 제작자, 스토리보드 아티스트를 도울 수 있는 도구를 향한 초기 단계를 나타낸다고 말한다.
초록
이미지 합성(image compositing)은 한 이미지의 내용을 다른 이미지에 삽입함으로써 사실적이면서도 가짜인 이미지를 생성하는 데 사용되는 방법이다. 합성에 관한 이전 연구는 사용자가 선택한 전경 세그먼트와 배경 이미지의 외형 호환성(즉, 색상 및 조명 일관성)을 향상시키는 데 초점을 맞춰 왔다. 본 연구에서 우리는 그 대신, 입력 이미지 배경만 주어졌을 때 대규모 컬렉션에서 호환되는 전경 세그먼트를 선택하고 변환하는 것까지 학습하는 완전 자동화된 합성 모델을 개발한다. 작업을 단순화하기 위해, 우리는 인간 세그먼트가 배경과 강한 상관관계를 보이고 대규모 주석 데이터를 이용할 수 있다는 점에서 인간 인스턴스 합성에 초점을 맞춰 문제를 한정한다. 우리는 배경 이미지가 주어졌을 때 후보 인물 위치를 공동으로 예측하는 새로운 분기형(branching) 합성곱 신경망(CNN)을 개발한다. 그런 다음 우리는 사전학습된 심층 특징 표현을 사용하여 대규모 세그먼트 데이터베이스에서 인물 인스턴스를 검색한다. 실험 결과는 우리의 모델이 시각적으로 설득력 있어 보이는 합성 이미지를 생성할 수 있음을 보인다. 우리는 또한 우리 방법의 잠재적 응용을 시연하기 위한 사용자 인터페이스를 개발한다.
세부 정보
인용
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}