Where and Who? Automatic Semantic-Aware Person Composition
Краткое изложение пресс-релиза
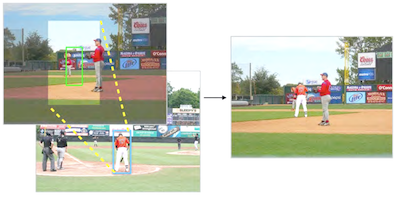
Исследователи из University of Virginia построили систему, которая может автоматически вставить реалистично выглядящую человеческую фигуру в фотографию без какого-либо человеческого указания на то, куда её поместить или кого использовать. Большинство существующих инструментов фотокомпозитинга справляются с технической работой по смешиванию краёв и согласованию цветов, но всё ещё оставляют пользователю выбор субъекта переднего плана, выбор места его размещения и решение о том, насколько большим он должен быть. Новая система решает эти оценочные задачи вычислительно, обучая ветвящуюся свёрточную нейронную сеть на десятках тысяч аннотированных изображений из набора данных MS-COCO, обучая её предсказывать правдоподобные местоположения и размеры для человека при наличии лишь фоновой сцены. Как только ограничивающая рамка предсказана, система ищет в пуле из примерно 4 100 вручную сегментированных вырезок людей, используя глубокие признаки из предобученной модели ResNet50, чтобы сопоставить как общий тип сцены, так и непосредственное локальное окружение, прежде чем вписать выбранную фигуру с помощью альфа-маттинга. В краудсорсинговом пользовательском исследовании на Amazon Mechanical Turk человеческие судьи оценивали композиты системы как реальные примерно в 44 процентах случаев, по сравнению с примерно 18-28 процентами для трёх базовых подходов, хотя реальные фотографии всё ещё набирали около 90 процентов. Разрыв значительно сокращается, когда текстура и освещение убираются, что указывает на то, что несоответствия цвета и освещения — а не размещение или выбор фигуры — являются основным оставшимся препятствием. Исследователи говорят, что работа представляет собой ранний шаг к инструментам, которые могли бы помочь графическим дизайнерам, кинематографистам и художникам по раскадровке, которые в настоящее время тратят значительное время на ручную сборку таких сцен.
аннотация
Композитинг изображений — это метод, используемый для генерации реалистичных, но поддельных изображений путём вставки содержимого из одного изображения в другое. Предыдущая работа по композитингу была сосредоточена на улучшении совместимости внешнего вида выбранного пользователем сегмента переднего плана и фонового изображения (т. е. согласованности цвета и освещения). В этой работе мы вместо этого разрабатываем полностью автоматизированную модель композитинга, которая дополнительно учится выбирать и трансформировать совместимые сегменты переднего плана из большой коллекции, имея на входе лишь фон изображения. Чтобы упростить задачу, мы ограничиваем нашу проблему, сосредоточившись на композиции экземпляров людей, потому что сегменты людей демонстрируют сильные корреляции со своим фоном и из-за доступности большого объёма аннотированных данных. Мы разрабатываем новую ветвящуюся свёрточную нейронную сеть (Convolutional Neural Network, CNN), которая совместно предсказывает возможные местоположения людей при заданном фоновом изображении. Затем мы используем предобученные глубокие представления признаков для извлечения экземпляров людей из большой базы данных сегментов. Экспериментальные результаты показывают, что наша модель может генерировать композитные изображения, которые выглядят визуально убедительно. Мы также разрабатываем пользовательский интерфейс, чтобы продемонстрировать потенциальное применение нашего метода.
подробности
цитирование
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}