Where and Who? Automatic Semantic-Aware Person Composition
プレスリリース要約
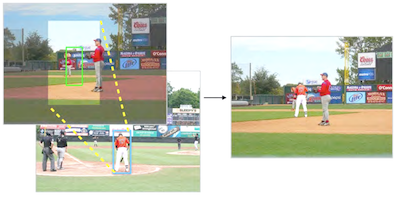
バージニア大学の研究者らは、どこに人物を配置するか、あるいは誰を使うかについての人間の指示なしに、写実的に見える人物像を写真に自動的に挿入できるシステムを構築した。既存の写真合成ツールの多くは、エッジをなじませたり色を合わせたりする技術的な作業を担うものの、前景の被写体を選び、どこに配置するかを決め、どれほどの大きさにするかを判断することは依然としてユーザーに委ねている。新しいシステムは、MS-COCOデータセットの数万枚のアノテーション付き画像で分岐型畳み込みニューラルネットワークを訓練し、背景シーンのみが与えられたときに人物のもっともらしい位置とサイズを予測するよう学習させることで、こうした判断を計算的に処理する。バウンディングボックスが予測されると、本システムは約4,100枚の手動でセグメント化された人物の切り抜きのプールを検索し、事前学習済みのResNet50モデルから得た深層特徴量を用いて、全体的なシーンの種類と直近の局所的な周囲環境の両方を一致させてから、選ばれた人物像をアルファマッティングでなじませる。Amazon Mechanical Turk上でのクラウドソーシングによるユーザー調査では、人間の判定者は本システムの合成画像を約44パーセントの割合で本物だと評価したのに対し、3つのベースライン手法ではおよそ18から28パーセントであった。ただし、本物の写真は依然として約90パーセントのスコアであった。テクスチャと照明を取り除くとこの差はかなり縮まり、配置や人物像の選択ではなく、色と照明の不一致が残る主要な障壁であることが示唆される。研究者らは、本研究が、現在こうしたシーンを手作業で組み立てるのにかなりの時間を費やしているグラフィックデザイナー、映画製作者、絵コンテのアーティストを支援しうるツールへ向けた初期の一歩であると述べている。
要旨
画像合成は、ある画像のコンテンツを別の画像に挿入することにより、写実的だが偽の画像を生成するために使われる手法である。合成に関する従来の研究は、ユーザーが選択した前景セグメントと背景画像の外観の整合性(すなわち色と照明の一貫性)の向上に焦点を当ててきた。本研究では、その代わりに、入力画像の背景のみが与えられた状態で、大規模なコレクションから整合する前景セグメントを選択し変換することも学習する、完全に自動化された合成モデルを開発する。タスクを単純化するため、人物インスタンスの合成に焦点を当てることで問題を制限する。これは、人物のセグメントがその背景と強い相関を示すこと、および大規模なアノテーション付きデータが利用可能であることによる。我々は、背景画像が与えられたときに候補となる人物の位置を同時に予測する、新規の分岐型畳み込みニューラルネットワーク(CNN)を開発する。次に、事前学習済みの深層特徴表現を用いて、大規模なセグメントデータベースから人物インスタンスを検索する。実験結果は、我々のモデルが視覚的に説得力のある合成画像を生成できることを示している。また、本手法の潜在的な応用を実証するためのユーザーインターフェースも開発する。
詳細
引用
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}