Where and Who? Automatic Semantic-Aware Person Composition
Sintesi del comunicato stampa
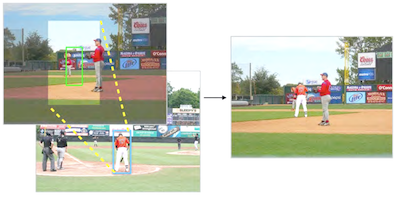
I ricercatori della University of Virginia hanno realizzato un sistema in grado di inserire automaticamente una figura umana dall'aspetto realistico in una fotografia, senza alcuna indicazione umana su dove collocarla o quale utilizzare. La maggior parte degli strumenti di compositing fotografico esistenti gestisce il lavoro tecnico di fusione dei bordi e di abbinamento dei colori, ma lascia comunque all'utente il compito di scegliere un soggetto in primo piano, decidere dove collocarlo e quanto grande debba essere. Il nuovo sistema affronta queste valutazioni in modo computazionale addestrando una rete neurale convoluzionale a diramazione su decine di migliaia di immagini annotate del dataset MS-COCO, insegnandole a predire posizioni e dimensioni plausibili per una persona dato unicamente lo sfondo della scena. Una volta predetto un riquadro di delimitazione, il sistema effettua una ricerca in un insieme di circa 4.100 ritagli di persone segmentati manualmente, utilizzando le caratteristiche profonde di un modello ResNet50 pre-addestrato per far corrispondere sia il tipo complessivo di scena sia l'ambiente locale immediato, prima di fondere la figura scelta tramite alpha matting. In uno studio condotto con persone tramite crowdsourcing su Amazon Mechanical Turk, i giudici umani hanno valutato le immagini composite del sistema come reali circa il 44 percento delle volte, rispetto a un valore tra circa il 18 e il 28 percento per tre approcci di riferimento, sebbene le fotografie reali ottenessero comunque punteggi intorno al 90 percento. Il divario si riduce considerevolmente quando texture e illuminazione vengono rimosse, suggerendo che le discrepanze di colore e illuminazione — e non il posizionamento o la selezione della figura — siano il principale ostacolo residuo. I ricercatori affermano che il lavoro rappresenta un primo passo verso strumenti che potrebbero assistere grafici, registi e disegnatori di storyboard, i quali attualmente dedicano molto tempo all'assemblaggio manuale di tali scene.
abstract
Il compositing di immagini è un metodo utilizzato per generare immagini realistiche ma artefatte, inserendo contenuti di un'immagine in un'altra. I lavori precedenti sul compositing si sono concentrati sul migliorare la compatibilità d'aspetto tra un segmento in primo piano selezionato dall'utente e un'immagine di sfondo (ossia la coerenza di colore e illuminazione). In questo lavoro, sviluppiamo invece un modello di compositing completamente automatizzato che apprende inoltre a selezionare e trasformare segmenti di primo piano compatibili da un'ampia raccolta, dato unicamente uno sfondo di immagine in input. Per semplificare il compito, restringiamo il nostro problema concentrandoci sulla composizione di istanze umane, perché i segmenti umani presentano forti correlazioni con il loro sfondo e per la disponibilità di grandi quantità di dati annotati. Sviluppiamo una nuova rete neurale convoluzionale (CNN) a diramazione che predice congiuntamente le posizioni candidate delle persone data un'immagine di sfondo. Utilizziamo poi rappresentazioni di caratteristiche profonde pre-addestrate per recuperare istanze di persone da un ampio database di segmenti. I risultati sperimentali mostrano che il nostro modello è in grado di generare immagini composite dall'aspetto visivamente convincente. Sviluppiamo inoltre un'interfaccia utente per dimostrare la potenziale applicazione del nostro metodo.
dettagli
citazione
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}