Where and Who? Automatic Semantic-Aware Person Composition
Resumo do comunicado de imprensa
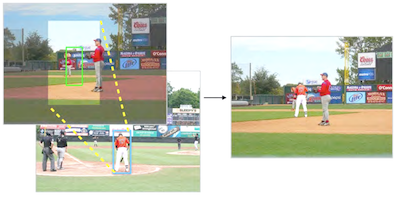
Pesquisadores da University of Virginia construíram um sistema capaz de inserir automaticamente uma figura humana de aparência realista em uma fotografia, sem qualquer orientação humana sobre onde colocá-la ou quem usar. A maioria das ferramentas de composição de fotos existentes lida com o trabalho técnico de mesclar bordas e combinar cores, mas ainda deixa a cargo do usuário escolher um sujeito de primeiro plano, decidir onde posicioná-lo e definir seu tamanho. O novo sistema enfrenta essas decisões de julgamento computacionalmente, treinando uma rede neural convolucional ramificada com dezenas de milhares de imagens anotadas do conjunto de dados MS-COCO, ensinando-a a prever localizações e tamanhos plausíveis para uma pessoa dado apenas o cenário de fundo. Uma vez prevista uma caixa delimitadora, o sistema busca em um conjunto de cerca de 4.100 recortes de pessoas segmentados manualmente, usando atributos profundos de um modelo ResNet50 pré-treinado para combinar tanto o tipo geral da cena quanto o entorno local imediato antes de mesclar a figura escolhida por meio de alpha matting. Em um estudo de usuários por crowdsourcing no Amazon Mechanical Turk, juízes humanos avaliaram as composições do sistema como reais cerca de 44 por cento das vezes, em comparação com aproximadamente 18 a 28 por cento para três abordagens de referência, embora fotografias reais ainda tivessem pontuação em torno de 90 por cento. A diferença se estreita consideravelmente quando textura e iluminação são removidas, sugerindo que incompatibilidades de cor e iluminação — e não a colocação ou a seleção da figura — são o principal obstáculo remanescente. Os pesquisadores afirmam que o trabalho representa um passo inicial em direção a ferramentas que poderiam auxiliar designers gráficos, cineastas e artistas de storyboard, que atualmente gastam um tempo considerável montando manualmente cenas desse tipo.
resumo
A composição de imagens é um método usado para gerar imagens realistas, porém falsas, inserindo conteúdos de uma imagem em outra. Trabalhos anteriores em composição focaram em melhorar a compatibilidade de aparência entre um segmento de primeiro plano selecionado pelo usuário e uma imagem de fundo (ou seja, consistência de cor e iluminação). Neste trabalho, em vez disso, desenvolvemos um modelo de composição totalmente automatizado que, adicionalmente, aprende a selecionar e transformar segmentos de primeiro plano compatíveis a partir de uma grande coleção, dado apenas um fundo de imagem de entrada. Para simplificar a tarefa, restringimos nosso problema focando na composição de instâncias humanas, porque os segmentos humanos exibem fortes correlações com seu fundo e devido à disponibilidade de grandes volumes de dados anotados. Desenvolvemos uma nova Rede Neural Convolucional (CNN) ramificada que prevê conjuntamente localizações candidatas de pessoas dada uma imagem de fundo. Em seguida, usamos representações de atributos profundos pré-treinadas para recuperar instâncias de pessoas de um grande banco de dados de segmentos. Os resultados experimentais mostram que nosso modelo pode gerar imagens compostas que parecem visualmente convincentes. Também desenvolvemos uma interface de usuário para demonstrar a aplicação potencial do nosso método.
detalhes
citação
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}