Where and Who? Automatic Semantic-Aware Person Composition
Zusammenfassung der Pressemitteilung
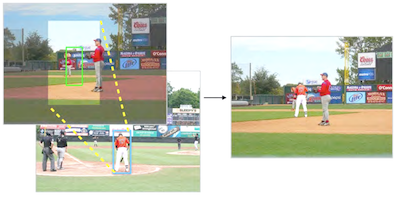
Forscher der University of Virginia haben ein System entwickelt, das automatisch eine realistisch aussehende menschliche Figur in ein Foto einfügen kann, ohne dass ein Mensch vorgeben muss, wohin sie zu setzen oder wen zu verwenden ist. Die meisten bestehenden Foto-Compositing-Werkzeuge erledigen die technische Arbeit des Verschmelzens von Kanten und des Abgleichs von Farben, überlassen es aber weiterhin dem Nutzer, ein Vordergrundmotiv auszuwählen, dessen Platzierung zu bestimmen und über seine Größe zu entscheiden. Das neue System bewältigt diese Ermessensentscheidungen rechnerisch, indem es ein verzweigendes konvolutionales neuronales Netz an zehntausenden annotierten Bildern aus dem MS-COCO-Datensatz trainiert und ihm beibringt, plausible Positionen und Größen für eine Person vorherzusagen, wenn nur die Hintergrundszene gegeben ist. Sobald ein Begrenzungsrahmen vorhergesagt ist, durchsucht das System einen Pool von etwa 4.100 manuell segmentierten Personenausschnitten und nutzt dabei tiefe Merkmale aus einem vortrainierten ResNet50-Modell, um sowohl den Gesamttyp der Szene als auch die unmittelbare lokale Umgebung abzugleichen, bevor es die ausgewählte Figur mittels Alpha-Matting einfügt. In einer per Crowdsourcing durchgeführten Nutzerstudie auf Amazon Mechanical Turk bewerteten menschliche Beurteiler die Kompositionen des Systems in etwa 44 Prozent der Fälle als echt, verglichen mit etwa 18 bis 28 Prozent bei drei Vergleichsansätzen, während echte Fotografien noch immer rund 90 Prozent erreichten. Die Lücke verringert sich erheblich, wenn Textur und Beleuchtung entfernt werden, was darauf hindeutet, dass Farb- und Beleuchtungsabweichungen – nicht die Platzierung oder die Auswahl der Figur – die wesentliche verbleibende Hürde sind. Die Forscher sagen, dass die Arbeit einen frühen Schritt hin zu Werkzeugen darstellt, die Grafikdesignern, Filmemachern und Storyboard-Künstlern helfen könnten, die derzeit erhebliche Zeit für das manuelle Zusammenstellen solcher Szenen aufwenden.
Zusammenfassung
Image Compositing ist eine Methode, mit der realistische und doch unechte Bilder erzeugt werden, indem Inhalte aus einem Bild in ein anderes eingefügt werden. Frühere Arbeiten zum Compositing haben sich darauf konzentriert, die Erscheinungskompatibilität eines vom Nutzer ausgewählten Vordergrundsegments und eines Hintergrundbildes zu verbessern (d. h. Farb- und Beleuchtungskonsistenz). In dieser Arbeit entwickeln wir stattdessen ein vollautomatisiertes Compositing-Modell, das zusätzlich lernt, kompatible Vordergrundsegmente aus einer großen Sammlung auszuwählen und zu transformieren, wobei nur ein Eingabebild als Hintergrund gegeben ist. Um die Aufgabe zu vereinfachen, schränken wir unser Problem ein, indem wir uns auf die Komposition menschlicher Instanzen konzentrieren, da menschliche Segmente starke Korrelationen mit ihrem Hintergrund aufweisen und weil große annotierte Daten verfügbar sind. Wir entwickeln ein neuartiges, verzweigendes Convolutional Neural Network (CNN), das bei gegebenem Hintergrundbild gemeinsam Kandidatenpositionen für Personen vorhersagt. Anschließend verwenden wir vortrainierte tiefe Merkmalsrepräsentationen, um Personeninstanzen aus einer großen Segmentdatenbank abzurufen. Experimentelle Ergebnisse zeigen, dass unser Modell zusammengesetzte Bilder erzeugen kann, die visuell überzeugend wirken. Wir entwickeln außerdem eine Benutzeroberfläche, um die potenzielle Anwendung unserer Methode zu demonstrieren.
Details
Zitation
@inproceedings{tan2018where,
title = {Where and Who? Automatic Semantic-Aware Person Composition},
author = {Tan, Fuwen and Bernier, Crispin and Cohen, Benjamin and Ordonez, Vicente and Barnes, Connelly},
year = {2018},
booktitle = {Winter Conference on Applications of Computer Vision. WACV 2018},
url = {https://arxiv.org/abs/1706.01021},
}