Grounding Language Models for Visual Entity Recognition
Zusammenfassung der Pressemitteilung
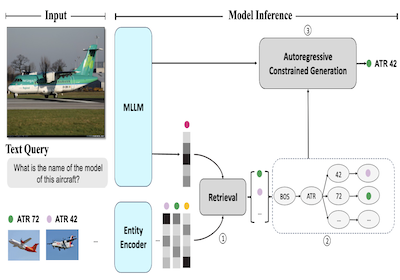
Forschende an der Rice University und bei Microsoft haben ein System namens AutoVER entwickelt, das die Fähigkeit eines Computers, bestimmte reale Entitäten in Bildern zu identifizieren, drastisch verbessert — man denke an die Unterscheidung eines bestimmten Flugzeugmodells von einem anderen, nahezu identischen — indem es die Vermutungen eines KI-Sprachmodells an einer konkreten Wissensbasis verankert, statt es einfach irgendeine plausibel erscheinende Antwort generieren zu lassen. Das Kernproblem besteht darin, dass bestehende multimodale KI-Systeme, die sowohl Bilder als auch Text verarbeiten, dazu neigen, zu halluzinieren oder Antworten auf der falschen Detailebene zu produzieren, wenn sie nach feinkörnigen Erkennungsfragen gefragt werden, etwa ob ein abgebildetes Flugzeug eine ATR 42 oder eine British Aerospace 146 ist. AutoVER geht dies an, indem es zwei Techniken kombiniert: Es trainiert das Modell mit einem kontrastiven Lernansatz darauf, visuell und semantisch ähnliche Kandidaten-Entitäten aus einer Datenbank mit über sechs Millionen Wikipedia-Einträgen abzurufen, und schränkt dann während der Antwortgenerierung die Ausgabe des Modells auf nur diese abgerufenen Kandidaten ein, indem es einen Präfixbaum aufbaut, der jegliche Token-Sequenzen blockiert, die zu ungültigen Antworten führen würden. Das System wurde auf dem Oven-Wiki-Benchmark getestet, einem groß angelegten Datensatz, der speziell für diese Art von Herausforderung der visuellen Entitätserkennung entworfen wurde, wo es die Genauigkeit bei Entitäten, die das Modell im Training gesehen hatte, von etwa 32,7 Prozent auf 61,5 Prozent steigerte, während es zugleich viel größere Modelle wie Googles PaLI-17B bei Beispielen mit ungesehenen Entitäten und Fragen, die visuelles Schlussfolgern erfordern, übertraf. Die Arbeit ist von Bedeutung, weil eine zuverlässige Entitätserkennung aus Bildern praktische Anwendungen in Bereichen von Suchmaschinen bis hin zu Barrierefreiheits-Werkzeugen hat, und der Ansatz zeigt, dass die enge Kopplung von Retrieval mit eingeschränkter Generierung ein verlässlicherer Weg ist, als einfach ein Modell hochzuskalieren und zu hoffen, dass es spezifische Antworten richtig genug trifft.
Zusammenfassung
Wir stellen AutoVER vor, ein autoregressives Modell für die Visual Entity Recognition. Unser Modell erweitert ein autoregressives multimodales Large Language Model durch den Einsatz von retrieval-augmentierter eingeschränkter Generierung. Es mildert die geringe Leistung bei domänenfremden Entitäten ab, während es bei Anfragen brilliert, die visuell situiertes Schlussfolgern erfordern. Unsere Methode lernt, ähnliche Entitäten innerhalb eines riesigen Label-Raums zu unterscheiden, indem sie parallel zu einem Sequence-to-Sequence-Ziel kontrastiv auf Hard-Negative-Paaren trainiert wird, ohne einen externen Retriever. Während der Inferenz leitet eine Liste abgerufener Kandidatenantworten die Sprachgenerierung explizit an, indem ungültige Decodierungspfade entfernt werden. Die vorgeschlagene Methode erzielt deutliche Verbesserungen über verschiedene Datensatz-Splits im kürzlich vorgeschlagenen Oven-Wiki-Benchmark. Die Genauigkeit auf dem Split mit gesehenen Entitäten steigt von 32,7 % auf 61,5 %. Sie zeigt zudem eine überlegene Leistung auf den Splits mit ungesehenen Entitäten und mit Anfragen mit einem erheblichen zweistelligen Abstand.
Details
Zitation
@inproceedings{xiao2024grounding,
title = {Grounding Language Models for Visual Entity Recognition},
author = {Xiao, Zilin and Gong, Ming and Cascante-Bonilla, Paola and Zhang, Xingyao and Wu, Jie and Ordonez, Vicente},
year = {2024},
booktitle = {European Conference on Computer Vision ECCV 2024},
url = {https://arxiv.org/abs/2402.18695},
}
automatisch generierte Fragen, wichtigste Beiträge und Grenzen dieses Artikels
Fragen, die dieser Artikel beantworten hilft
- Was ist AutoVER? AutoVER ist ein autoregressives multimodales Sprachmodell für die visuelle Entitätserkennung, bei dem Antworten an bestimmten Entitäten in einer großen Wissensbasis verankert sein müssen.
- Welches Problem adressiert die Arbeit? Sie befasst sich mit der feinkörnigen bildbasierten Entitätserkennung, bei der Modelle visuell ähnliche Entitäten unterscheiden und das Halluzinieren von Antworten außerhalb des gültigen Entitätsraums vermeiden müssen.
- Wie funktioniert die retrieval-augmentierte eingeschränkte Generierung hier? AutoVER ruft wahrscheinliche Entitäten ab, baut aus diesen Kandidaten einen dynamischen Präfixbaum auf und schränkt die Decodierung so ein, dass die Generierung nur gültigen Token-Pfaden von Entitätsnamen folgt.
- Warum kontrastives Lernen und Hard Negatives verwenden? Das Modell lernt das Retrieval von Anfrage zu Entität mit visuell und wissensmäßig ähnlichen Hard Negatives, was ihm hilft, Entitäten zu trennen, die Erscheinungsbild oder Kategoriestruktur teilen.
- Wo wird AutoVER bewertet? Die Arbeit bewertet auf Oven-Wiki und testet außerdem den Zero-Shot-Transfer auf einer entitätsverankerten Teilmenge von A-OKVQA.
Wichtigste Beiträge
- Die Arbeit führt AutoVER ein, ein retrieval-augmentiertes autoregressives Framework, um die Ausgaben multimodaler Sprachmodelle an visuellen Entitäten im Wikipedia-Maßstab zu verankern.
- Sie integriert das kontrastive Training von Anfrage zu Entität direkt in das multimodale Sprachmodell und vermeidet so die Abhängigkeit von einem separaten externen Retriever.
- Der Mechanismus zur eingeschränkten Decodierung stellt sicher, dass generierte Antworten in abgerufenen Kandidaten-Entitäten verankert sind, was ungültige oder unverankerte Generierungen direkt verringert.
- Das Hard-Negative-Mining aus visueller Ähnlichkeit und der Hierarchie der Wissensbasis verbessert die feinkörnige Unterscheidung zwischen visuell ähnlichen Entitäten.
- AutoVER verbessert die Oven-Wiki-Leistung erheblich, einschließlich der Steigerung der Genauigkeit bei gesehenen Entitäten von 32,7 % auf 61,5 % im berichteten Vergleich und übertrifft größere PaLI-Baselines auf den Splits mit ungesehenen Entitäten und mit Anfragen.
Grenzen und Vorbehalte
- AutoVER hängt von der Abdeckung und Qualität der Entitäts-Wissensbasis ab, was für die visuelle Entitätserkennung angemessen ist und das Verankerungsziel explizit macht.
- Die Methode ruft vor der eingeschränkten Decodierung eine Kandidatenmenge ab, sodass sehr seltene oder visuell mehrdeutige Entitäten herausfordernd bleiben, wenn das Retrieval sie verfehlt; die Arbeit begegnet dem direkt mit visuellen Merkmalen auf der Entitätsseite und Hard-Negative-Training.
- Das Training im Wikipedia-Maßstab erfordert erhebliche Daten und Rechenleistung, aber das Ergebnis ist ein praktisches Framework, um große Wissensbasen in nutzbare Ziele für die visuelle Erkennung zu verwandeln.
- Die Arbeit zeigt nach wie vor einen Abstand zur Leistung von Mensch plus Suche auf der menschlichen Bewertungsmenge, was eher ein nützlicher Benchmark für zukünftigen Fortschritt als eine Schwäche des Kernansatzes ist.
- AutoVER ist auf entitätsverankerte Antworten spezialisiert und ergänzt breitere offene VQA-Systeme, wenn die gewünschte Ausgabe eine präzise benannte Entität sein soll.
Wie dieses Ergebnis zu lesen ist
Diese Arbeit lässt sich am besten als ein starker Beitrag zur verankerten multimodalen Erkennung lesen: AutoVER zeigt, dass Retrieval, kontrastives Entitätslernen und eingeschränkte Generierung die Antworten von Sprachmodellen für die visuelle Entitätserkennung im Wikipedia-Maßstab deutlich präziser und vertrauenswürdiger machen können.