Evolving Image Compositions for Feature Representation Learning
Resumen de prensa
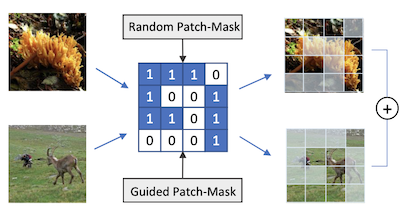
Investigadores de la Universidad de Virginia y la Universidad Rice han desarrollado una técnica de aumento de datos llamada PatchMix que ayuda a las redes neuronales de reconocimiento de imágenes a aprender mejor entrenándose con imágenes híbridas construidas artificialmente. El problema central es que los modelos de aprendizaje profundo para el reconocimiento visual tienden a sobreajustarse a sus datos de entrenamiento y, aunque métodos existentes como Mixup y CutMix ya combinan pares de imágenes para combatir esto, están limitados en cuán flexiblemente pueden combinar esas imágenes. PatchMix aborda esto dividiendo dos imágenes en una cuadrícula de parches del mismo tamaño e intercambiando parches entre ellas según una máscara binaria, para luego asignar a la imagen compuesta resultante una etiqueta combinada proporcional a cuántos parches provienen de cada fuente. El equipo también añadió una función de pérdida secundaria que entrena a la red para identificar correctamente a qué clase pertenece cada parche individual, no solo la imagen en su conjunto, lo que obliga al modelo a construir representaciones con mayor conciencia local. Yendo más allá, los investigadores usaron un algoritmo de búsqueda genética para descubrir automáticamente qué pares de categorías de imágenes son más útiles para mezclar entre sí, y qué patrones de cuadrícula producen los ejemplos de entrenamiento más desafiantes —y por tanto más informativos—, todo ello sin necesidad de reentrenar el modelo desde cero para cada configuración candidata. Probado frente a benchmarks estándar, un modelo ResNet-50 entrenado con PatchMix superó a los modelos de referencia en CIFAR-10, CIFAR-100, Tiny ImageNet e ImageNet, y mostró un rendimiento de aprendizaje por transferencia más fuerte en tareas que incluyen detección de objetos, reconocimiento de escenas y generación de descripciones de imágenes, lo que sugiere que el método produce características visuales de propósito más general que los enfoques competidores.
resumen
Las redes neuronales convolucionales para el reconocimiento visual requieren grandes cantidades de muestras de entrenamiento y normalmente se benefician del aumento de datos. Este artículo propone PatchMix, un método de aumento de datos que crea nuevas muestras componiendo parches de pares de imágenes en un patrón de cuadrícula. A estas nuevas muestras se les asignan puntuaciones de etiqueta proporcionales al número de parches tomados de cada imagen. Luego añadimos un conjunto de pérdidas adicionales a nivel de parche para regularizar y fomentar buenas representaciones tanto a nivel de parche como de imagen. Un modelo ResNet-50 entrenado en ImageNet usando PatchMix exhibe capacidades superiores de aprendizaje por transferencia en una amplia gama de benchmarks. Aunque PatchMix puede basarse en emparejamientos aleatorios y patrones de cuadrícula aleatorios para la mezcla, exploramos la búsqueda evolutiva como estrategia orientadora para descubrir conjuntamente patrones de cuadrícula y emparejamientos de imágenes óptimos. Para este propósito, concebimos una función de aptitud que evita la necesidad de reentrenar un modelo para evaluar cada elección posible. De esta manera, PatchMix supera a un modelo base en CIFAR-10 (+1,91), CIFAR-100 (+5,31), Tiny Imagenet (+3,52) e ImageNet (+1,16).
detalles
cita
@inproceedings{cascantebonilla2021evolving,
title = {Evolving Image Compositions for Feature Representation Learning},
author = {Cascante-Bonilla, Paola and Sekhon, Arshdeep and Qi, Yanjun and Ordonez, Vicente},
year = {2021},
booktitle = {British Machine Vision Conference. BMVC 2021},
url = {https://arxiv.org/abs/2106.09011},
}