Going Beyond Nouns With Vision & Language Models Using Synthetic Data
Resumen de prensa
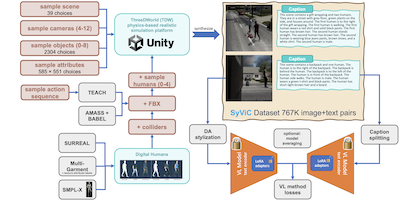
Investigadores del MIT, IBM, la Universidad Rice y varias otras instituciones han identificado y dado un paso práctico hacia la solución de un punto ciego persistente en populares modelos de visión y lenguaje como CLIP: estos sistemas son sorprendentemente malos para comprender cualquier cosa que vaya más allá de los objetos de una imagen, y les cuesta captar atributos, relaciones espaciales, acciones y el orden de las palabras de formas que a los humanos les resultan triviales. Para abordar esto, el equipo construyó un conjunto de datos sintético de un millón de imágenes llamado SyViC —Synthetic Visual Concepts— ejecutando simulaciones 3D basadas en física en el motor ThreeDWorld, poblando las escenas con objetos, materiales y avatares humanos animados aleatorizados, vestidos con ropa diversa, y luego generando automáticamente subtítulos de texto detallados a partir de los metadatos de la escena. La idea clave es que los entornos sintéticos permiten a los investigadores crear de forma económica pares imagen-texto que resaltan deliberadamente los conceptos que no son sustantivos que los modelos pasan por alto, algo prohibitivamente difícil y costoso de lograr con fotografías del mundo real. Cuando ajustaron finamente CLIP y CyCLIP en SyViC usando una combinación de adaptación de parámetros de bajo rango (LoRA), adaptación de dominio basada en transferencia de estilo y una técnica de división de subtítulos para manejar texto descriptivo más largo, los modelos mejoraron hasta en un 9,9 % en el benchmark de razonamiento composicional ARO y un 4,3 % en la evaluación VL-Checklist, sacrificando menos del uno por ciento de su precisión de clasificación zero-shot en 21 tareas. El trabajo es importante porque demuestra que datos sintéticos dirigidos, sin ninguna imagen real, pueden corregir de forma significativa una debilidad estructural bien documentada en el entrenamiento contrastivo de visión y lenguaje, y el equipo ha publicado tanto el conjunto de datos como el código.
resumen
Los modelos de Visión y Lenguaje (VL) preentrenados a gran escala han mostrado un rendimiento notable en muchas aplicaciones, permitiendo reemplazar un conjunto fijo de clases soportadas por un razonamiento zero-shot de vocabulario abierto sobre indicaciones en lenguaje natural (casi arbitrarias). Sin embargo, trabajos recientes han revelado una debilidad fundamental de estos modelos. Por ejemplo, su dificultad para comprender Conceptos de Lenguaje Visual (VLC) que van 'más allá de los sustantivos', como el significado de palabras que no designan objetos (p. ej., atributos, acciones, relaciones, estados, etc.), o su dificultad para realizar razonamiento composicional, como comprender la relevancia del orden de las palabras en una oración. En este trabajo, investigamos en qué medida se pueden aprovechar datos puramente sintéticos para enseñar a estos modelos a superar tales deficiencias sin comprometer sus capacidades zero-shot. Aportamos Synthetic Visual Concepts (SyViC), un conjunto de datos sintéticos a escala de millones y una base de código de generación de datos que permite generar datos adicionales adecuados para mejorar la comprensión de VLC y el razonamiento composicional de los modelos VL. Además, proponemos una estrategia general de ajuste fino de VL para aprovechar eficazmente SyViC en la consecución de estas mejoras. Nuestros extensos experimentos y ablaciones en los benchmarks VL-Checklist, Winoground y ARO demuestran que es posible adaptar modelos VL preentrenados sólidos con datos sintéticos, mejorando significativamente su comprensión de VLC (p. ej., en un 9,9 % en ARO y un 4,3 % en VL-Checklist) con una caída inferior al 1 % en su precisión zero-shot.
detalles
cita
@inproceedings{cascantebonilla2023going,
title = {Going Beyond Nouns With Vision & Language Models Using Synthetic Data},
author = {Cascante-Bonilla, Paola and Shehada, Khaled and Smith, James Seale and Doveh, Sivan and Kim, Donghyun and Panda, Rameswar and Varol, Gül and Oliva, Aude and Ordonez, Vicente and Feris, Rogerio and Karlinsky, Leonid},
year = {2023},
booktitle = {International Conference on Computer Vision. ICCV 2023},
url = {https://arxiv.org/abs/2303.17590},
}