Taming Data and Transformers for Audio Generation
Resumen de prensa
Investigadores de la Universidad Rice y Snap Inc. han abordado un cuello de botella persistente en el sonido ambiental generado por IA: la escasez de datos de entrenamiento grandes y bien etiquetados y de modelos que no mejoran al crecer en tamaño. Para resolver el problema de los datos, el equipo desarrolló una canalización automatizada que extrae clips de audio ambiental de conjuntos de datos de vídeo existentes basados en YouTube, identificando segmentos en los que no hay transcripción de habla ni de música, evitando así la necesidad de descargar y ejecutar costosos clasificadores sobre el vídeo en bruto. El resultado es AutoReCap-XL, un conjunto de datos de 47 millones de clips de audio ambiental con descripciones de texto, aproximadamente 75 veces más grande que lo que estaba disponible anteriormente. Para generar esas descripciones, construyeron AutoCap, un modelo de descripción de audio que incorpora un módulo Q-Former junto con metadatos visuales como títulos de vídeo y descripciones a nivel de fotograma, alcanzando una puntuación CIDEr de 83,2 en el benchmark estándar AudioCaps, una mejora del 3,2 % respecto a métodos anteriores. En el lado de la generación, introdujeron GenAu, un modelo de difusión basado en transformadores escalado hasta 1.250 millones de parámetros que toma prestada una arquitectura «FIT» diseñada originalmente para vídeo, usando capas de atención local y global para concentrar el cómputo en segmentos de audio informativos en lugar de distribuirlo de manera uniforme sobre porciones silenciosas o redundantes. En comparación con líneas base equiparables, GenAu mejoró la Inception Score en un 11,1 %, la Fréchet Audio Distance en un 4,7 % y la puntuación de alineación texto-audio CLAP en un 13,5 % y —a diferencia de modelos de audio grandes anteriores— continuó mejorando de forma consistente a medida que aumentaban tanto el tamaño del modelo como el del conjunto de datos, lo que sugiere que el campo podría tener por fin una receta para escalar la generación de sonido ambiental del mismo modo en que ya se ha escalado la generación de imágenes y vídeo.
resumen
La escalabilidad de los generadores de sonido ambiental se ve obstaculizada por la escasez de datos, la insuficiente calidad de las descripciones y la limitada escalabilidad de la arquitectura del modelo. Este trabajo aborda estos desafíos avanzando tanto en el escalado de datos como en el de modelos. En primer lugar, proponemos una canalización de recopilación de datos eficiente y escalable, adaptada a la generación de audio ambiental, que da lugar a AutoReCap-XL, el mayor conjunto de datos de audio-texto ambiental, con más de 47 millones de clips. Para proporcionar anotaciones textuales de alta calidad, proponemos AutoCap, un modelo de descripción automática de audio de alta calidad. Al adoptar un módulo Q-Former y aprovechar los metadatos del audio, AutoCap mejora sustancialmente la calidad de las descripciones, alcanzando una puntuación CIDEr de $83.2$, una mejora del $3.2\%$ respecto a modelos de descripción anteriores. Por último, proponemos GenAu, una arquitectura de generación de audio escalable basada en transformadores que escalamos hasta 1.250 millones de parámetros. Demostramos sus beneficios derivados del escalado de datos con descripciones sintéticas, así como del escalado del tamaño del modelo. En comparación con generadores de audio de referencia entrenados a una escala similar de tamaño y datos, GenAu obtiene mejoras significativas del $4.7\%$ en la puntuación FAD, del $11.1\%$ en IS y del $13.5\%$ en la puntuación CLAP. Nuestro código, los puntos de control del modelo y el conjunto de datos están disponibles públicamente.
detalles
cita
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
preguntas, contribuciones principales y limitaciones de este artículo generadas automáticamente
Preguntas que ayuda a responder este artículo
- ¿Qué problema resuelve este artículo? Aborda las principales barreras para la generación escalable de sonido ambiental: la escasez de datos de audio-texto, la baja calidad de las descripciones y las arquitecturas de generadores que no se han beneficiado de forma fiable del escalado.
- ¿Qué es AutoReCap-XL? AutoReCap-XL es un conjunto de datos de audio-texto ambiental muy grande, con más de 47 millones de clips, recopilado filtrando segmentos de vídeo en línea para obtener audio sin habla ni música y describiéndolos automáticamente de nuevo.
- ¿Qué es AutoCap? AutoCap es un modelo de descripción automática de audio que combina características de audio, un Q-Former, decodificación con BART y metadatos como títulos de vídeo y descripciones visuales para producir descripciones de audio de mayor calidad.
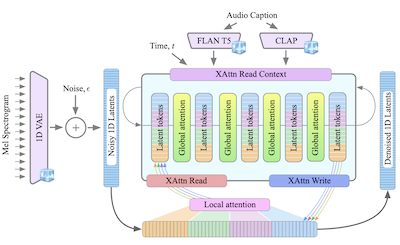
- ¿Qué es GenAu? GenAu es un modelo de difusión latente basado en transformadores para la generación de texto a audio que adapta una arquitectura de estilo FIT con atención local y global a la estructura temporal del audio.
- ¿Por qué es importante el escalado en este trabajo? El artículo muestra que GenAu mejora tanto con más datos descritos sintéticamente como con un mayor tamaño de modelo, lo cual es importante porque los generadores de audio ambiental anteriores a menudo mostraban un comportamiento de escalado débil o inconsistente.
Contribuciones principales
- El artículo introduce AutoReCap-XL, descrito como el mayor conjunto de datos de audio-texto ambiental del trabajo, con 47 millones de clips y aproximadamente 123,5 mil horas de audio extraídas de fuentes de vídeo a gran escala.
- Propone AutoCap, un potente generador de descripciones de audio que utiliza un Q-Former y metadatos para mejorar la calidad de las descripciones, alcanzando una puntuación CIDEr de 83,2 en AudioCaps.
- Presenta GenAu, una arquitectura de difusión de texto a audio escalable basada en transformadores que utiliza un espacio latente de VAE 1D y atención local/global inspirada en FIT para una generación de audio eficiente.
- Los experimentos muestran mejoras claras respecto a líneas base comparables de texto a audio, incluidas ganancias en FAD, Inception Score y alineación CLAP.
- El artículo proporciona una receta de escalado inusualmente completa para la generación de audio ambiental al mejorar conjuntamente el conjunto de datos, la canalización de descripción y la arquitectura del modelo, en lugar de tratarlos como problemas separados.
Limitaciones y advertencias
- AutoCap se afina sobre AudioCaps, cuyo vocabulario es limitado, por lo que los prompts muy detallados o inusuales pueden seguir siendo un reto; el artículo plantea esto como una vía directa para futuras mejoras del generador de descripciones y del conjunto de datos.
- AutoReCap-XL se valida principalmente mediante experimentos de generación de audio, lo que constituye un primer caso de uso sólido y deja la recuperación de audio, la comprensión de audio y las tareas de audio-vídeo como extensiones prometedoras.
- La canalización de recopilación de datos se apoya en transcripciones, metadatos y heurísticas de filtrado, pero es precisamente eso lo que la hace lo bastante eficiente como para escalar mucho más allá de los conjuntos de datos de audio ambiental descritos manualmente.
- GenAu se centra en el sonido ambiental en lugar de en la generación de habla o música, lo que da al artículo una contribución enfocada y deja los dominios de audio relacionados como oportunidades naturales de adaptación.
- El entrenamiento a gran escala y un modelo de 1.250 millones de parámetros requieren un cómputo considerable, pero los resultados defienden con fuerza que esta inversión produce un mejor comportamiento de escalado para la generación de audio ambiental.
Cómo interpretar este resultado
Este artículo se lee mejor como un gran avance a nivel de sistemas para la generación de audio ambiental: al combinar un conjunto de datos masivo re-descrito, un modelo de descripción más potente y un generador de difusión basado en transformadores escalable, ofrece al campo una receta práctica para mejorar la calidad de texto a audio mediante el escalado tanto de datos como de modelos.