Instance-level Image Retrieval using Reranking Transformers
Resumen de prensa
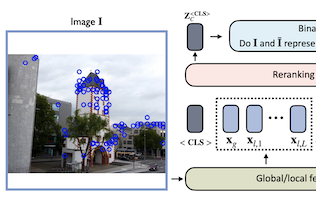
Investigadores de la Universidad de Virginia, eBay y la Universidad Rice han desarrollado un modelo de red neuronal ligero llamado Reranking Transformer, o RRT, que mejora la precisión de los sistemas de búsqueda de imágenes que intentan identificar objetos o monumentos específicos en lugar de categorías amplias. El problema que abordó el equipo es un proceso de dos pasos común en la recuperación de imágenes: una primera pasada usa un descriptor global de imagen compacto para obtener una lista corta de coincidencias candidatas, y una segunda pasada refina esa lista usando características locales más detalladas, un paso tradicionalmente gestionado por la verificación geométrica, una técnica computacionalmente costosa que intenta estimar cómo una imagen puede deformarse geométricamente para coincidir con otra. Los investigadores reemplazaron ese segundo paso con un pequeño modelo basado en transformadores, tomando prestada la arquitectura basada en atención que ha impulsado los avances recientes en el procesamiento del lenguaje natural, y lo entrenaron para predecir directamente si dos imágenes muestran el mismo objeto o escena. Con solo unos 2.2 millones de parámetros —aproximadamente el 9 por ciento del tamaño de un backbone estándar ResNet50— y requiriendo solo la mitad de descriptores de características locales que la verificación geométrica, el RRT no obstante superó a la verificación geométrica y a otros enfoques competidores en benchmarks estándar incluidos los conjuntos de datos Revisited Oxford y Paris y Google Landmarks v2. Una ventaja práctica clave es que reordenar una lista corta completa de 100 imágenes candidatas requiere solo una única pasada hacia adelante a través de la red. Los investigadores también demostraron que, a diferencia de la verificación geométrica, el RRT puede entrenarse conjuntamente con el extractor de características subyacente, permitiendo que ambos componentes se optimicen juntos y produciendo mejoras adicionales de precisión, una capacidad que demostraron en el conjunto de datos Stanford Online Products.
resumen
La recuperación de imágenes a nivel de instancia es la tarea de buscar en una gran base de datos imágenes que coincidan con un objeto en una imagen de consulta. Para abordar esta tarea, los sistemas normalmente dependen de un paso de recuperación que usa descriptores globales de imagen, y un paso posterior que realiza refinamientos específicos de dominio o reordenamiento aprovechando operaciones como la verificación geométrica basada en características locales. En este trabajo, proponemos los Reranking Transformers (RRTs) como un modelo general para incorporar tanto características locales como globales con el fin de reordenar las imágenes coincidentes de manera supervisada y, así, reemplazar el proceso relativamente costoso de la verificación geométrica. Los RRTs son ligeros y pueden paralelizarse fácilmente, de modo que el reordenamiento de un conjunto de los mejores resultados coincidentes puede realizarse en una única pasada hacia adelante. Realizamos experimentos extensos en los conjuntos de datos Revisited Oxford y Paris, y en el conjunto de datos Google Landmarks v2, mostrando que los RRTs superan a los enfoques de reordenamiento previos mientras usan muchos menos descriptores locales. Además, demostramos que, a diferencia de los enfoques existentes, los RRTs pueden optimizarse conjuntamente con el extractor de características, lo que puede conducir a representaciones de características adaptadas a las tareas posteriores y a mejoras adicionales de precisión. El código y los modelos entrenados están disponibles públicamente en https://github.com/uvavision/RerankingTransformer.
detalles
cita
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}