Commonly Uncommon: Semantic Sparsity in Situation Recognition
Resumen de prensa
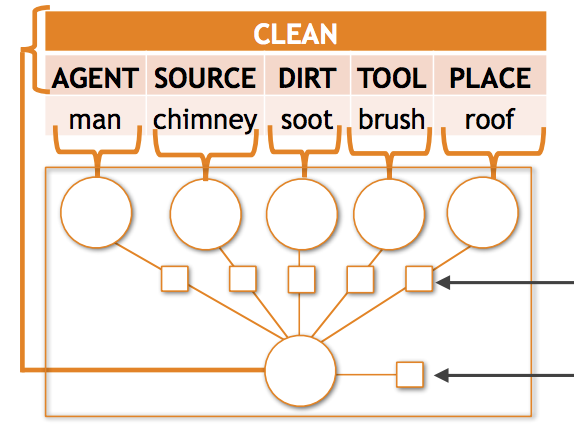
Investigadores de la Universidad de Washington y el Allen Institute for Artificial Intelligence han abordado un problema persistente en la visión por computadora: cuando los sistemas de IA intentan describir con detalle estructurado lo que está sucediendo en una foto —identificando no solo una actividad como "cargar" sino también quién está cargando, qué están cargando y dónde— tienden a fallar cada vez que la escena involucra una combinación inusual de objetos y roles. El equipo descubrió que en el conjunto de datos de referencia imSitu, aproximadamente el 35 por ciento de las predicciones requeridas involucran emparejamientos objeto-rol vistos menos de diez veces durante el entrenamiento, y los modelos existentes pierden una precisión significativa precisamente en esos casos. Para abordar esto, los investigadores desarrollaron dos técnicas complementarias. Primero, diseñaron un nuevo modelo matemático llamado potencial tensorial composicional, integrado dentro de un marco de Campo Aleatorio Condicional (Conditional Random Field), que aprende representaciones compartidas de sustantivos a través de diferentes roles, de modo que el conocimiento sobre cómo se ve un "bebé", por ejemplo, puede informar las predicciones independientemente de si el bebé aparece como la cosa que se carga o como la persona que carga. Segundo, construyeron una canalización de aumento semántico de datos que convierte situaciones de entrenamiento anotadas en frases de texto cortas, usa esas frases para recuperar aproximadamente cinco millones de imágenes de la búsqueda de imágenes de Google, e incorpora los resultados ruidosos mediante entrenamiento de verosimilitud marginal y autoentrenamiento iterativo. La combinación de ambos enfoques mejoró la precisión top-5 de verbo en aproximadamente un 6 por ciento y la precisión de rol-sustantivo en casi un 10 por ciento sobre el estado del arte previo, con ganancias relativas aún mayores en los casos raros que el trabajo aborda específicamente. Los hallazgos importan porque la escasez semántica —demasiadas combinaciones de salida posibles, demasiados pocos ejemplos de la mayoría de ellas— es un obstáculo generalizado en las tareas de comprensión visual estructurada, y este trabajo ofrece una estrategia concreta y escalable para hacer que los sistemas de IA sean más fiables al encontrarse con las situaciones poco comunes que son, en la práctica, bastante comunes en el mundo real.
resumen
La escasez semántica es un desafío común en los problemas de clasificación visual estructurada; cuando el espacio de salida es complejo, la gran mayoría de las predicciones posibles rara vez, o nunca, se observan en el conjunto de entrenamiento. Este artículo estudia la escasez semántica en el reconocimiento de situaciones, la tarea de producir resúmenes estructurados de lo que está sucediendo en las imágenes, incluyendo actividades, objetos y los roles que los objetos desempeñan dentro de la actividad. Para este problema, encontramos empíricamente que la mayoría de las combinaciones objeto-rol son raras, y que los modelos actuales de estado del arte tienen un rendimiento significativamente inferior en este régimen de datos escasos. Evitamos muchos de estos errores (1) introduciendo una novedosa función de composición tensorial que aprende a compartir ejemplos entre combinaciones rol-sustantivo y (2) aumentando semánticamente nuestros datos de entrenamiento con ejemplos recopilados automáticamente de salidas raramente observadas usando datos de la web. Cuando se integra dentro de un modelo completo de predicción estructurada basado en CRF, el enfoque basado en tensores supera el estado del arte existente con una mejora relativa del 2.11% y el 4.40% en la precisión top-5 de verbo y de rol-sustantivo, respectivamente. Añadir 5 millones de imágenes con nuestras técnicas de aumento semántico produce mejoras relativas adicionales del 6.23% y el 9.57% en la precisión top-5 de verbo y de rol-sustantivo.
cita
@inproceedings{yatskar2017commonly,
title = {Commonly Uncommon: Semantic Sparsity in Situation Recognition},
author = {Yatskar, Mark and Ordonez, Vicente and Zettlemoyer, Luke and Farhadi, Ali},
year = {2017},
booktitle = {Intl. Conference on Computer Vision and Pattern Recognition. CVPR 2017},
url = {https://arxiv.org/abs/1612.00901},
}