Taming Data and Transformers for Audio Generation
Résumé du communiqué de presse
Des chercheurs de l'université Rice et de Snap Inc. se sont attaqués à un goulot d'étranglement persistant dans la génération de sons d'ambiance par IA : la pénurie de données d'entraînement vastes et bien annotées, et des modèles qui ne s'améliorent pas à mesure qu'ils grandissent. Pour résoudre le problème des données, l'équipe a développé un pipeline automatisé qui extrait des clips audio d'ambiance à partir de jeux de données vidéo existants issus de YouTube, en identifiant les segments où aucune transcription de parole ou de musique n'est présente, évitant ainsi de télécharger et d'exécuter des classifieurs coûteux sur la vidéo brute. Le résultat est AutoReCap-XL, un jeu de données de 47 millions de clips audio d'ambiance accompagnés de descriptions textuelles, environ 75 fois plus grand que ce qui était disponible auparavant. Pour générer ces descriptions, ils ont construit AutoCap, un modèle de légendage audio qui intègre un module Q-Former aux côtés de métadonnées visuelles telles que les titres de vidéos et les légendes au niveau des images, atteignant un score CIDEr de 83,2 sur le banc d'essai standard AudioCaps, soit une amélioration de 3,2 % par rapport aux méthodes antérieures. Côté génération, ils ont introduit GenAu, un modèle de diffusion fondé sur des transformeurs porté à 1,25 milliard de paramètres, qui emprunte une architecture « FIT » initialement conçue pour la vidéo, utilisant des couches d'attention locale et globale pour concentrer le calcul sur les segments audio informatifs plutôt que de le répartir uniformément sur des portions silencieuses ou redondantes. Comparé à des références équivalentes, GenAu a amélioré l'Inception Score de 11,1 %, la distance audio de Fréchet de 4,7 % et le score d'alignement texte CLAP de 13,5 %, et, contrairement aux grands modèles audio précédents, a continué à s'améliorer de manière constante à mesure que la taille du modèle et celle du jeu de données augmentaient, suggérant que le domaine dispose peut-être enfin d'une recette pour mettre à l'échelle la génération de sons d'ambiance comme l'ont déjà été la génération d'images et de vidéos.
résumé
La capacité de passage à l'échelle des générateurs de sons d'ambiance est entravée par la rareté des données, la qualité insuffisante des légendes et la mise à l'échelle limitée de l'architecture des modèles. Ce travail relève ces défis en faisant progresser à la fois la mise à l'échelle des données et celle des modèles. Premièrement, nous proposons un pipeline de collecte de données efficace et évolutif, adapté à la génération d'audio d'ambiance, qui aboutit à AutoReCap-XL, le plus grand jeu de données audio-texte d'ambiance avec plus de 47 millions de clips. Pour fournir des annotations textuelles de haute qualité, nous proposons AutoCap, un modèle automatique de légendage audio de haute qualité. En adoptant un module Q-Former et en exploitant les métadonnées audio, AutoCap améliore substantiellement la qualité des légendes, atteignant un score CIDEr de $83.2$, soit une amélioration de $3.2\%$ par rapport aux modèles de légendage précédents. Enfin, nous proposons GenAu, une architecture évolutive de génération audio fondée sur des transformeurs, que nous portons jusqu'à 1,25 milliard de paramètres. Nous démontrons les bénéfices qu'elle tire de la mise à l'échelle des données avec des légendes synthétiques ainsi que de la mise à l'échelle de la taille du modèle. Comparé à des générateurs audio de référence entraînés à une taille et à une échelle de données similaires, GenAu obtient des améliorations significatives de $4.7\%$ sur le score FAD, $11.1\%$ sur l'IS et $13.5\%$ sur le score CLAP. Notre code, nos points de contrôle de modèle et notre jeu de données sont disponibles publiquement.
détails
citation
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Quel problème cet article résout-il ? Il s'attaque aux principaux obstacles à la génération de sons d'ambiance passant à l'échelle : la rareté des données audio-texte, la faible qualité des légendes et des architectures de générateurs qui n'ont pas profité de manière fiable de la mise à l'échelle.
- Qu'est-ce qu'AutoReCap-XL ? AutoReCap-XL est un très grand jeu de données audio-texte d'ambiance comptant plus de 47 millions de clips, collectés en filtrant les segments de vidéos en ligne pour ne retenir que l'audio sans parole ni musique, puis en les relégendant automatiquement.
- Qu'est-ce qu'AutoCap ? AutoCap est un modèle automatique de légendage audio qui combine des caractéristiques audio, un Q-Former, un décodage BART et des métadonnées telles que les titres de vidéos et les légendes visuelles pour produire des descriptions audio de meilleure qualité.
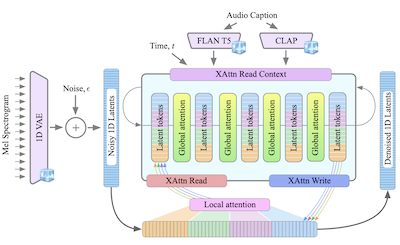
- Qu'est-ce que GenAu ? GenAu est un modèle de diffusion latente fondé sur des transformeurs pour la génération texte-vers-audio, qui adapte une architecture de type FIT avec attention locale et globale à la structure temporelle de l'audio.
- Pourquoi la mise à l'échelle est-elle importante dans ce travail ? L'article montre que GenAu s'améliore à la fois avec davantage de données synthétiquement légendées et avec une taille de modèle plus grande, ce qui est important car les générateurs de sons d'ambiance antérieurs présentaient souvent un comportement de mise à l'échelle faible ou incohérent.
Principales contributions
- L'article introduit AutoReCap-XL, décrit dans le travail comme le plus grand jeu de données audio-texte d'ambiance, avec 47 millions de clips et environ 123 500 heures d'audio issues de sources vidéo à grande échelle.
- Il propose AutoCap, un solide modèle de légendage audio qui utilise un Q-Former et des métadonnées pour améliorer la qualité des légendes, atteignant un score CIDEr de 83,2 sur AudioCaps.
- Il présente GenAu, une architecture de diffusion texte-vers-audio évolutive fondée sur des transformeurs, qui utilise un espace latent VAE 1D et une attention locale/globale inspirée de FIT pour une génération audio efficace.
- Les expériences montrent des améliorations nettes par rapport à des références texte-vers-audio comparables, notamment des gains en FAD, en Inception Score et en alignement CLAP.
- L'article fournit une recette de mise à l'échelle exceptionnellement complète pour la génération d'audio d'ambiance en améliorant conjointement le jeu de données, le pipeline de légendage et l'architecture du modèle plutôt qu'en les traitant comme des problèmes distincts.
Limites et mises en garde
- AutoCap est affiné sur AudioCaps, dont le vocabulaire est limité, de sorte que des invites très détaillées ou inhabituelles peuvent encore poser problème ; l'article présente cela comme une voie directe pour de futures améliorations du modèle de légendage et du jeu de données.
- AutoReCap-XL est validé principalement par des expériences de génération audio, ce qui constitue un premier cas d'usage solide tout en laissant la recherche audio, la compréhension audio et les tâches audio-vidéo comme extensions prometteuses.
- Le pipeline de collecte de données s'appuie sur des transcriptions, des métadonnées et des heuristiques de filtrage, mais c'est aussi ce qui le rend suffisamment efficace pour passer à l'échelle bien au-delà des jeux de données d'audio d'ambiance légendés manuellement.
- GenAu cible le son d'ambiance plutôt que la génération de parole ou de musique, ce qui donne à l'article une contribution ciblée tout en laissant les domaines audio connexes comme opportunités naturelles d'adaptation.
- L'entraînement à grande échelle et un modèle de 1,25 milliard de paramètres nécessitent une puissance de calcul conséquente, mais les résultats plaident fortement en faveur du fait que cet investissement produit un meilleur comportement de mise à l'échelle pour la génération d'audio d'ambiance.
Comment interpréter ce résultat
Cet article se lit avant tout comme une avancée majeure au niveau système pour la génération d'audio d'ambiance : en associant un jeu de données massif relégendé, un modèle de légendage plus performant et un générateur de diffusion évolutif fondé sur des transformeurs, il offre au domaine une recette pratique pour améliorer la qualité texte-vers-audio grâce à la mise à l'échelle conjointe des données et des modèles.