Instance-level Image Retrieval using Reranking Transformers
Résumé du communiqué de presse
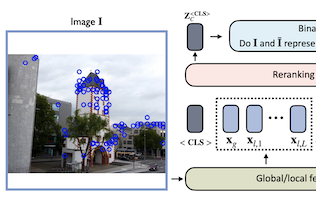
Des chercheurs de l'Université de Virginie, d'eBay et de l'Université Rice ont mis au point un modèle de réseau de neurones léger appelé Reranking Transformer, ou RRT, qui améliore la précision des systèmes de recherche d'images cherchant à identifier des objets ou des monuments spécifiques plutôt que de larges catégories. Le problème que l'équipe a abordé est un processus en deux étapes courant en recherche d'images : une première passe utilise un descripteur d'image global compact pour établir une liste restreinte de correspondances candidates, et une seconde passe affine cette liste à l'aide de caractéristiques locales plus détaillées — une étape traditionnellement assurée par la vérification géométrique, une technique coûteuse en calcul qui tente d'estimer comment une image peut être déformée géométriquement pour correspondre à une autre. Les chercheurs ont remplacé cette seconde étape par un petit modèle fondé sur les transformers, empruntant l'architecture fondée sur l'attention qui a porté les récentes avancées en traitement automatique du langage naturel, et l'ont entraîné à prédire directement si deux images montrent le même objet ou la même scène. Avec seulement environ 2,2 millions de paramètres — soit à peu près 9 pour cent de la taille d'un réseau dorsal ResNet50 standard — et ne nécessitant que la moitié des descripteurs de caractéristiques locales de la vérification géométrique, RRT a néanmoins surpassé la vérification géométrique et d'autres approches concurrentes sur des benchmarks standard, notamment les jeux de données Revisited Oxford et Paris et Google Landmarks v2. Un avantage pratique majeur est que le réordonnancement d'une liste restreinte entière de 100 images candidates ne nécessite qu'une seule passe avant à travers le réseau. Les chercheurs ont également montré que, contrairement à la vérification géométrique, RRT peut être entraîné conjointement avec l'extracteur de caractéristiques sous-jacent, ce qui permet d'optimiser les deux composants ensemble et d'obtenir des gains de précision supplémentaires, une capacité qu'ils ont démontrée sur le jeu de données Stanford Online Products.
résumé
La recherche d'images au niveau de l'instance consiste à rechercher dans une grande base de données les images qui correspondent à un objet présent dans une image requête. Pour aborder cette tâche, les systèmes s'appuient généralement sur une étape de recherche qui utilise des descripteurs d'image globaux, suivie d'une étape qui effectue des raffinements ou un réordonnancement spécifiques au domaine en exploitant des opérations telles que la vérification géométrique fondée sur des caractéristiques locales. Dans ce travail, nous proposons les Reranking Transformers (RRT) comme modèle général pour intégrer à la fois des caractéristiques locales et globales afin de réordonner les images correspondantes de manière supervisée et ainsi remplacer le processus relativement coûteux de vérification géométrique. Les RRT sont légers et peuvent être facilement parallélisés, de sorte que le réordonnancement d'un ensemble des meilleurs résultats correspondants peut être réalisé en une seule passe avant. Nous menons des expériences approfondies sur les jeux de données Revisited Oxford et Paris, ainsi que sur le jeu de données Google Landmarks v2, montrant que les RRT surpassent les approches de réordonnancement précédentes tout en utilisant beaucoup moins de descripteurs locaux. De plus, nous démontrons que, contrairement aux approches existantes, les RRT peuvent être optimisés conjointement avec l'extracteur de caractéristiques, ce qui peut conduire à des représentations de caractéristiques adaptées aux tâches en aval et à d'autres améliorations de précision. Le code et les modèles entraînés sont disponibles publiquement à l'adresse https://github.com/uvavision/RerankingTransformer.
détails
citation
@inproceedings{tan2021instance,
title = {Instance-level Image Retrieval using Reranking Transformers},
author = {Tan, Fuwen and Yuan, Jiangbo and Ordonez, Vicente},
year = {2021},
booktitle = {International Conference on Computer Vision. ICCV 2021},
url = {https://arxiv.org/abs/2103.12236},
}