ProxyThinker: Test-Time Guidance through Small Visual Reasoners
Résumé du communiqué de presse
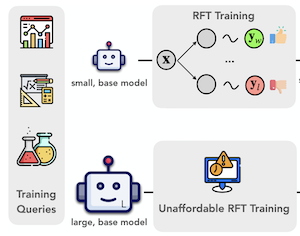
Des chercheurs de Rice University, de l'University of Illinois Urbana-Champaign et de l'University of Virginia ont mis au point une méthode appelée ProxyThinker qui permet aux grands modèles de vision-langage de raisonner plus soigneusement au moment du test — sans aucun entraînement supplémentaire. Le problème qu'ils ont cherché à résoudre est concret : apprendre aux grands modèles d'IA à « ralentir » et à résoudre des problèmes visuels complexes étape par étape nécessite généralement un coûteux ajustement fin par renforcement, un processus qui exige d'énormes ressources de calcul et qui a rarement été appliqué à des modèles dépassant les sept milliards de paramètres. ProxyThinker contourne entièrement ce coût en exécutant deux petits modèles compagnons aux côtés du grand modèle pendant l'inférence — l'un déjà ajusté pour raisonner avec soin, et l'autre non — et en utilisant la différence entre leurs distributions de sortie pour orienter la génération jeton par jeton du grand modèle vers un raisonnement plus délibéré et auto-vérifiant. En pratique, cela signifie que le grand modèle commence à présenter des comportements comme le retour en arrière, l'auto-vérification et la correction en plusieurs étapes qu'il produirait autrement rarement. En testant l'approche sur des bancs d'essai standards de mathématiques visuelles et multidisciplinaires, l'équipe a constaté qu'un modèle de base de 32 milliards de paramètres orienté par un expert de raisonnement faible de 7 milliards de paramètres pouvait égaler ou légèrement dépasser les performances d'un modèle dédié de 32 milliards de paramètres entièrement ajusté par apprentissage par renforcement. L'équipe a également conçu une implémentation parallélisée bâtie sur le cadre d'inférence vLLM qui s'exécute environ 38 fois plus vite que les méthodes antérieures d'orientation au moment du décodage, rapprochant le temps d'inférence réel de la simple exécution d'un seul grand modèle. Ce travail est important car il offre une voie computationnellement accessible vers un raisonnement visuel plus robuste dans les grands modèles, à une époque où les coûts d'entraînement de l'ajustement fin par renforcement à l'échelle de pointe restent hors de portée pour la plupart des groupes de recherche.
résumé
Les avancées récentes de l'apprentissage par renforcement avec récompenses vérifiables ont repoussé les limites des capacités de raisonnement visuel des grands modèles de vision-langage (LVLM). Cependant, l'entraînement des LVLM par ajustement fin par renforcement (RFT) est coûteux en calcul, ce qui constitue un défi majeur pour le passage à l'échelle de la taille des modèles. Dans ce travail, nous proposons ProxyThinker, une technique au moment de l'inférence qui permet aux grands modèles d'hériter des capacités de raisonnement visuel de petits raisonneurs visuels à réflexion lente sans aucun entraînement. En soustrayant les distributions de sortie des modèles de base de celles des raisonneurs RFT, ProxyThinker modifie la dynamique de décodage et suscite avec succès le raisonnement à réflexion lente démontré par les comportements sophistiqués qui émergent, tels que l'auto-vérification et l'auto-correction. ProxyThinker améliore systématiquement les performances sur des bancs d'essai visuels exigeants de raisonnement spatial, mathématique et multidisciplinaire, permettant aux modèles de base non ajustés de rivaliser avec les performances de leurs homologues RFT à pleine échelle. De plus, notre implémentation coordonne efficacement plusieurs modèles de langage à l'aide de techniques de parallélisme et atteint une inférence jusqu'à 38 $\times$ plus rapide par rapport aux méthodes antérieures au moment du décodage, ouvrant la voie au déploiement pratique de ProxyThinker. Le code est disponible à l'adresse https://github.com/MrZilinXiao/ProxyThinker.
citation
@inproceedings{xiao2026proxythinker,
title = {ProxyThinker: Test-Time Guidance through Small Visual Reasoners},
author = {Xiao, Zilin and Koo, Jaywon and Ouyang, Siru and Hernandez, Jefferson and Meng, Yu and Ordonez, Vicente},
year = {2026},
booktitle = {International Conference on Learning Representations. ICLR 2026},
url = {https://arxiv.org/abs/2505.24872},
}
questions, principales contributions et limites de cet article générées automatiquement
Questions auxquelles cet article aide à répondre
- Qu'est-ce que ProxyThinker et quel problème aborde-t-il ? ProxyThinker est une méthode sans entraînement, au moment de l'inférence, qui transfère le comportement de raisonnement visuel à réflexion lente de petits raisonneurs visuels ajustés par renforcement vers de plus grands modèles de vision-langage de base.
- Comment ProxyThinker oriente-t-il un grand modèle ? À chaque étape de décodage, il ajoute la différence de logits entre un petit expert de raisonnement RFT et son petit homologue amateur de base aux logits du grand modèle de base, encourageant le grand modèle à générer des jetons associés à l'auto-vérification et au raisonnement en plusieurs étapes.
- Pourquoi la méthode est-elle utile par rapport à l'ajustement fin par renforcement complet ? Elle évite de mettre à jour les paramètres du grand modèle, ce qui en fait une alternative pratique lorsque l'ajustement fin par renforcement à pleine échelle de modèles de vision-langage de 32 G ou 72 G est trop coûteux.
- Dans quelle mesure ProxyThinker améliore-t-il les bancs d'essai de raisonnement visuel ? Sur cinq bancs d'essai mathématiques et multidisciplinaires, ProxyThinker améliore Qwen2.5-VL-32B jusqu'à 2,4 pour cent d'amélioration relative moyenne et Qwen2.5-VL-72B jusqu'à 2,7 pour cent d'amélioration relative moyenne selon le petit expert de raisonnement.
- ProxyThinker change-t-il le style de raisonnement du grand modèle ? Oui, l'article rapporte davantage de comportements de retour en arrière, de vérification et de réflexion explicite, montrant que la méthode peut susciter des schémas de réflexion lente plutôt que de simplement modifier les probabilités de la réponse finale.
Principales contributions
- L'article introduit une formulation simple, au moment du décodage, pour le transfert de raisonnement visuel qui utilise le delta de logits au niveau du jeton entre un petit expert RFT et un petit modèle amateur comme guidage pour un plus grand modèle de base.
- ProxyThinker montre que de petits raisonneurs visuels peuvent améliorer des modèles substantiellement plus grands sans entraînement, y compris des modèles de vision-langage de 32 G et 72 G évalués sur MathVista, MathVerse, MathVision, MMMU-Pro et R1-OneVisionBench.
- La méthode permet à un modèle de base Qwen2.5-VL-32B guidé par un expert de 7 G d'égaler ou de légèrement dépasser un modèle RFT complet de 32 G dans certaines configurations de banc d'essai, y compris le résultat MathVision mis en avant dans l'article.
- L'analyse comportementale démontre que ProxyThinker peut combiner la capacité de planification de sous-objectifs du grand modèle avec les tendances d'auto-vérification et de retour en arrière du petit expert.
- L'implémentation fondée sur vLLM coordonne efficacement plusieurs modèles et rapporte une accélération de 38x par rapport aux implémentations antérieures d'orientation au moment du décodage de type HuggingFace, rendant l'approche beaucoup plus pratique.
Limites et mises en garde
- ProxyThinker dépend de l'accès à un petit raisonneur visuel RFT utile et à son modèle amateur de base correspondant, de sorte que de futurs travaux pourraient élargir la recette à davantage de familles de modèles et à des paires expert-amateur ouvertes.
- La méthode exécute plusieurs modèles au moment de l'inférence, ce qui ajoute une complexité système par rapport à une référence à modèle unique ; l'implémentation vLLM optimisée de l'article réduit substantiellement cette surcharge et montre que l'approche peut être pratique.
- Les gains de performance varient selon les bancs d'essai et les experts, certaines configurations montrant des améliorations plus faibles que d'autres ; cette variation identifie utilement la sélection de l'expert et l'intensité du guidage comme des leviers importants pour les futurs systèmes de raisonnement au moment du décodage.
- Les expériences se concentrent sur des bancs d'essai établis de mathématiques visuelles et multidisciplinaires, laissant les scénarios interactifs, à long horizon et de déploiement en conditions réelles comme prochains tests naturels pour la même idée de guidage.
- ProxyThinker oriente le comportement de raisonnement au moment du décodage plutôt que de modifier les poids sous-jacents du modèle, ce qui est un atout en matière d'accessibilité et de coût, tandis que de futurs travaux pourraient étudier comment il complète les méthodes au moment de l'entraînement.
Comment interpréter ce résultat
Cet article se lit au mieux comme une contribution solide et pratique au raisonnement visuel efficace : ProxyThinker montre que de petits raisonneurs entraînés peuvent débloquer un meilleur comportement de réflexion lente dans des modèles bien plus grands au moment du test, offrant une alternative ou un complément convaincant à l'ajustement fin par renforcement coûteux à pleine échelle.