Taming Data and Transformers for Audio Generation
Sintesi del comunicato stampa
I ricercatori della Rice University e di Snap Inc. hanno affrontato un collo di bottiglia persistente nei suoni ambientali generati dall'IA: la carenza di dati di addestramento ampi e ben etichettati e i modelli che non riescono a migliorare man mano che crescono di dimensioni. Per affrontare il problema dei dati, il team ha sviluppato una pipeline automatizzata che estrae clip audio ambientali da dataset video esistenti basati su YouTube, identificando i segmenti in cui non è presente alcuna trascrizione di parlato o musica, evitando così la necessità di scaricare ed eseguire costosi classificatori sui video grezzi. Il risultato è AutoReCap-XL, un dataset di 47 milioni di clip audio ambientali con descrizioni testuali, circa 75 volte più grande di quanto fosse disponibile in precedenza. Per generare tali descrizioni, hanno costruito AutoCap, un modello di captioning audio che incorpora un modulo Q-Former insieme a metadati visivi come i titoli dei video e le didascalie a livello di fotogramma, raggiungendo un punteggio CIDEr di 83.2 sul benchmark standard AudioCaps, un miglioramento del 3.2% rispetto ai metodi precedenti. Sul versante della generazione, hanno introdotto GenAu, un modello di diffusione basato su transformer scalato fino a 1,25 miliardi di parametri, che riprende un'architettura "FIT" originariamente progettata per il video, utilizzando livelli di attenzione locale e globale per concentrare il calcolo sui segmenti audio informativi anziché distribuirlo uniformemente su porzioni silenziose o ridondanti. Rispetto a baseline comparabili, GenAu ha migliorato l'Inception Score dell'11.1%, la Fréchet Audio Distance del 4.7% e il punteggio di allineamento testo CLAP del 13.5% e, a differenza dei precedenti grandi modelli audio, ha continuato a migliorare in modo costante all'aumentare sia della dimensione del modello sia di quella del dataset, suggerendo che il settore potrebbe finalmente disporre di una ricetta per scalare la generazione di suoni ambientali nello stesso modo in cui è già stata scalata la generazione di immagini e video.
abstract
La scalabilità dei generatori di suoni ambientali è ostacolata dalla scarsità di dati, dalla qualità insufficiente delle didascalie e dalla limitata scalabilità dell'architettura del modello. Questo lavoro affronta tali sfide facendo progredire sia lo scaling dei dati sia quello del modello. In primo luogo, proponiamo una pipeline di raccolta dati efficiente e scalabile, pensata per la generazione di audio ambientale, che dà origine ad AutoReCap-XL, il più grande dataset audio-testo ambientale con oltre 47 milioni di clip. Per fornire annotazioni testuali di alta qualità, proponiamo AutoCap, un modello automatico di captioning audio di alta qualità. Adottando un modulo Q-Former e sfruttando i metadati audio, AutoCap migliora sostanzialmente la qualità delle didascalie, raggiungendo un punteggio CIDEr di $83.2$, un miglioramento del $3.2\%$ rispetto ai precedenti modelli di captioning. Infine, proponiamo GenAu, un'architettura scalabile per la generazione audio basata su transformer che scaliamo fino a 1.25B parametri. Ne dimostriamo i benefici derivanti dallo scaling dei dati con didascalie sintetiche, oltre che dallo scaling della dimensione del modello. Rispetto ai generatori audio di riferimento addestrati a dimensioni e scala di dati simili, GenAu ottiene miglioramenti significativi del $4.7\%$ nel punteggio FAD, dell'$11.1\%$ nell'IS e del $13.5\%$ nel punteggio CLAP. Il nostro codice, i checkpoint del modello e il dataset sono disponibili pubblicamente.
dettagli
citazione
@article{hajiali2026taming,
title = {Taming Data and Transformers for Audio Generation},
author = {Haji-Ali, Moayed and Menapace, Willi and Siarohin, Aliaksandr and Balakrishnan, Guha and Ordonez, Vicente},
year = {2026},
journal = {International Journal of Computer Vision. IJCV 2026},
url = {https://arxiv.org/abs/2406.19388},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Quale problema risolve questo articolo? Affronta le principali barriere alla generazione scalabile di suoni ambientali: la scarsità di dati audio-testo, la debole qualità delle didascalie e le architetture di generazione che non hanno tratto beneficio in modo affidabile dallo scaling.
- Cos'è AutoReCap-XL? AutoReCap-XL è un dataset audio-testo ambientale molto grande, con oltre 47 milioni di clip raccolte filtrando i segmenti di video online per individuare audio privo di parlato e musica e ridotitolandoli automaticamente.
- Cos'è AutoCap? AutoCap è un modello automatico di captioning audio che combina caratteristiche audio, un Q-Former, la decodifica BART e metadati come i titoli dei video e le didascalie visive per produrre descrizioni audio di qualità superiore.
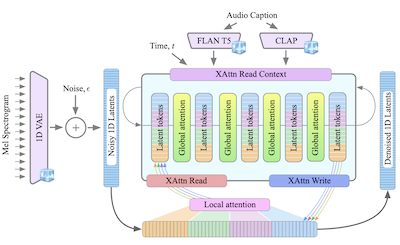
- Cos'è GenAu? GenAu è un modello di diffusione latente basato su transformer per la generazione text-to-audio che adatta un'architettura in stile FIT con attenzione locale e globale alla struttura temporale dell'audio.
- Perché lo scaling è importante in questo lavoro? L'articolo mostra che GenAu migliora sia con una maggiore quantità di dati con didascalie sintetiche sia con una dimensione del modello più grande, il che è importante perché i precedenti generatori di audio ambientale mostravano spesso un comportamento di scaling debole o incoerente.
Principali contributi
- L'articolo introduce AutoReCap-XL, descritto nel lavoro come il più grande dataset audio-testo ambientale, con 47 milioni di clip e circa 123,5k ore di audio tratte da fonti video su larga scala.
- Propone AutoCap, un potente sistema di captioning audio che utilizza un Q-Former e i metadati per migliorare la qualità delle didascalie, raggiungendo un punteggio CIDEr di 83.2 su AudioCaps.
- Presenta GenAu, un'architettura scalabile di diffusione text-to-audio basata su transformer che utilizza uno spazio latente VAE 1D e un'attenzione locale/globale ispirata a FIT per una generazione audio efficiente.
- Gli esperimenti mostrano chiari miglioramenti rispetto a baseline text-to-audio comparabili, inclusi guadagni in FAD, Inception Score e allineamento CLAP.
- L'articolo fornisce una ricetta di scaling insolitamente completa per la generazione di audio ambientale, migliorando insieme il dataset, la pipeline di captioning e l'architettura del modello anziché trattarli come problemi separati.
Limiti e avvertenze
- AutoCap è sottoposto a fine-tuning su AudioCaps, il cui vocabolario è limitato, quindi prompt molto dettagliati o insoliti possono ancora risultare impegnativi; l'articolo inquadra questo aspetto come una via diretta per futuri miglioramenti del sistema di captioning e del dataset.
- AutoReCap-XL è validato principalmente attraverso esperimenti di generazione audio, che costituiscono un solido primo caso d'uso, lasciando il recupero audio, la comprensione audio e i compiti audio-video come promettenti estensioni.
- La pipeline di raccolta dati si basa su trascrizioni, metadati ed euristiche di filtraggio, ma è proprio questo a renderla abbastanza efficiente da scalare ben oltre i dataset di audio ambientale con didascalie manuali.
- GenAu è orientato ai suoni ambientali anziché alla generazione di parlato o musica, il che conferisce all'articolo un contributo mirato, lasciando i domini audio correlati come naturali opportunità di adattamento.
- L'addestramento su larga scala e un modello da 1.25B parametri richiedono risorse di calcolo significative, ma i risultati dimostrano in modo convincente che tale investimento produce un migliore comportamento di scaling per la generazione di audio ambientale.
Come interpretare questo risultato
Questo articolo si legge al meglio come un importante avanzamento a livello di sistema per la generazione di audio ambientale: abbinando un enorme dataset ridotitolato, un modello di captioning più potente e un generatore di diffusione basato su transformer scalabile, offre al settore una ricetta pratica per migliorare la qualità del text-to-audio attraverso lo scaling sia dei dati sia del modello.