GViT: Representing Images as Gaussians for Visual Recognition
Sintesi del comunicato stampa
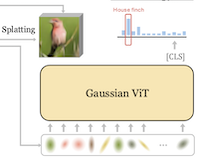
I ricercatori della Rice University e della UC Irvine hanno costruito un nuovo sistema di classificazione di immagini che abbandona l'approccio convenzionale di fornire a una rete neurale una griglia di pixel o patch rettangolari, sostituendo quell'input con un insieme compatto di macchie matematiche chiamate gaussiane 2D. Il sistema, chiamato GViT, funziona addestrando una piccola rete encoder a descrivere ogni immagine utilizzando poche centinaia di gaussiane, dove ciascuna macchia trasporta informazioni sulla sua posizione, dimensione, orientamento, colore e opacità. La parte ingegnosa dell'impostazione di addestramento è che il modello di classificazione e l'encoder gaussiano vengono addestrati insieme in un ciclo di feedback: i gradienti del classificatore — essenzialmente segnali su quali parti di un'immagine contino per identificarne il contenuto — vengono restituiti per indirizzare le gaussiane verso le regioni effettivamente utili per il riconoscimento, anziché lasciarle distribuire uniformemente su sfondo poco informativo. Utilizzando questo approccio sul benchmark standard ImageNet-1k, la versione migliore di GViT ha raggiunto un'accuratezza top-1 del 76,9% con un'architettura ViT-Base, rispetto a circa il 78,7% di un ViT convenzionale basato su patch di dimensioni simili — un divario di meno di due punti percentuali pur utilizzando una rappresentazione di input fondamentalmente diversa e molto più compatta. Il lavoro è importante non perché superi immediatamente i sistemi esistenti, ma perché dimostra che primitive geometriche intermedie e interpretabili dall'uomo possono supportare un riconoscimento visivo competitivo, e come effetto collaterale le gaussiane apprese tendono a raggrupparsi attorno alle parti di una scena che il modello trova più discriminanti, offrendo una forma leggera di spiegabilità che i modelli a griglia di pixel non forniscono naturalmente.
abstract
Introduciamo GVIT, un framework di classificazione che abbandona le convenzionali rappresentazioni di input a griglia di pixel o patch in favore di un insieme compatto di gaussiane 2D apprendibili. Ogni immagine è codificata come poche centinaia di gaussiane le cui posizioni, scale, orientamenti, colori e opacità sono ottimizzati congiuntamente con un classificatore ViT addestrato su queste rappresentazioni. Riutilizziamo i gradienti del classificatore come guida costruttiva, indirizzando le gaussiane verso regioni salienti per la classe mentre un renderer differenziabile ottimizza una loss di ricostruzione dell'immagine. Dimostriamo che le rappresentazioni di input a gaussiane 2D, abbinate alla nostra guida GVIT e utilizzando un'architettura ViT relativamente standard, eguagliano da vicino le prestazioni di un ViT tradizionale basato su patch, raggiungendo un'accuratezza top-1 del 76,9% su Imagenet-1k utilizzando un'architettura ViT-B.
citazione
@article{hernandezgvit,
title = {GViT: Representing Images as Gaussians for Visual Recognition},
author = {Hernandez, Jefferson and He, Ruozhen and Balakrishnan, Guha and Berg, Alexander C. and Ordonez, Vicente},
journal = {arXiv preprint arXiv:2506.23532},
url = {https://arxiv.org/abs/2506.23532},
}
domande, principali contributi e limiti di questo articolo generati automaticamente
Domande a cui questo articolo aiuta a rispondere
- Che cos'è GViT e quale problema affronta? GViT è un framework di riconoscimento visivo che sostituisce gli input fissi a griglia di pixel o patch con un insieme compatto di primitive gaussiane 2D apprendibili, verificando se rappresentazioni geometriche di livello intermedio possano supportare una classificazione di immagini competitiva.
- Come vengono apprese le gaussiane? Un encoder gaussiano di denoising predice i centri, le scale, gli orientamenti, i colori e le opacità delle gaussiane, mentre un renderer differenziabile ottimizza la ricostruzione dell'immagine e un classificatore ViT fornisce gradienti costruttivi che indirizzano le gaussiane verso regioni salienti per la classe.
- Quanto bene si comporta GViT su ImageNet-1k? Il modello guidato GViT-B raggiunge un'accuratezza top-1 del 76,9 percento su ImageNet-1k, vicina al 78,7 percento riportato per un ViT-B/16 basato su patch di dimensioni simili, pur utilizzando una rappresentazione di input gaussiana sostanzialmente diversa.
- Perché la guida tramite gradienti del classificatore è importante? L'articolo riporta che la guida migliora GViT-B dal 73,6 percento al 76,9 percento su ImageNet-1k e migliora analogamente modelli più piccoli, mostrando che un posizionamento delle gaussiane consapevole del compito è centrale per rendere la rappresentazione utile al riconoscimento.
- GViT offre benefici di interpretabilità? Sì, le covarianze gaussiane apprese e le mappe di attenzione discriminanti per la classe tendono a concentrarsi su regioni dell'immagine rilevanti per la classe, conferendo alla rappresentazione una spiegazione visiva geometrica che i token a patch standard non espongono naturalmente.
Principali contributi
- L'articolo introduce una rappresentazione di immagini compatibile con ViT basata su insiemi di primitive gaussiane 2D anziché su pixel, patch, byte grezzi o coefficienti di frequenza compressi.
- GViT propone uno schema di addestramento cooperativo in cui le loss di ricostruzione preservano la fedeltà dell'immagine mentre i gradienti del classificatore riposizionano attivamente le gaussiane verso evidenze visive discriminanti.
- Gli esperimenti su ImageNet-1k mostrano che gli input gaussiani possono raggiungere un'accuratezza top-1 del 76,9 percento con un backbone ViT-B, superando diverse alternative di input non basate su patch elencate nell'articolo e arrivando a 1,8 punti da un ViT-B/16 convenzionale basato su patch.
- Le ablazioni su Mini-ImageNet-100 mostrano che il denoising e la guida tramite gradienti del classificatore migliorano in modo significativo il posizionamento delle gaussiane, con la versione completa e guidata che supera l'adattamento offline delle gaussiane, le query apprese e il denoising senza guida.
- L'analisi mostra che la scala delle gaussiane e i segnali di attenzione si allineano con le regioni discriminanti per la classe, a sostegno dell'affermazione che GViT offre una rappresentazione di riconoscimento compatta con una componente di interpretabilità naturale.
Limiti e avvertenze
- I ViT basati su patch restano oggi la scelta più pragmatica per molte implementazioni su larga scala, ma il piccolo divario di accuratezza di GViT su ImageNet-1k dimostra in modo convincente che le primitive gaussiane sono già una rappresentazione alternativa praticabile e sorprendentemente competitiva.
- Il numero di gaussiane è fissato prima dell'addestramento, perciò versioni future potrebbero trarre beneficio da generazione, potatura o riallocazione dinamiche; i guadagni monotoni osservati all'aumentare del budget di gaussiane forniscono utili indicazioni per quel successivo passo di progettazione.
- Il rendering differenziabile aggiunge un sovraccarico di memoria e calcolo, specialmente ad alte risoluzioni o con più di 512 gaussiane nell'addestramento alla scala di ImageNet; si tratta di un collo di bottiglia ingegneristico attorno a una rappresentazione per il resto promettente, anziché di una debolezza dell'idea di fondo.
- Gli esperimenti si concentrano su benchmark di classificazione di immagini e di classificazione per transfer anziché su compiti di predizione densa come il rilevamento o la segmentazione; le disposizioni gaussiane salienti per la classe suggeriscono che tali compiti siano i luoghi naturali in cui esplorare la rappresentazione successivamente.
- L'approccio attuale comprime per scelta progettuale parte del dettaglio fine a livello di pixel, il che contribuisce a rendere la rappresentazione compatta e interpretabile, pur lasciando spazio a lavori futuri per regolare l'equilibrio tra fedeltà di ricostruzione e discriminazione semantica.
Come interpretare questo risultato
Questo articolo è meglio interpretato come un argomento solido e supportato da evidenze a favore del fatto che il riconoscimento visivo non debba essere legato a griglie di pixel o patch: GViT mantiene le prestazioni su ImageNet vicine a quelle dei ViT standard pur introducendo una rappresentazione gaussiana interpretabile che apre una direzione promettente per i futuri backbone di visione.