CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations
abstract
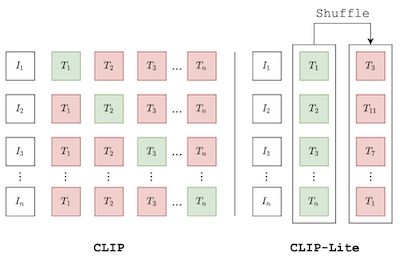
Proponiamo CLIP-Lite, un metodo efficiente dal punto di vista informativo per l'apprendimento di rappresentazioni visive tramite l'allineamento delle caratteristiche con annotazioni testuali. Rispetto al modello CLIP proposto in precedenza, CLIP-Lite richiede solo una coppia negativa immagine-testo per ogni coppia positiva immagine-testo durante l'ottimizzazione del suo obiettivo di apprendimento contrastivo. Otteniamo questo risultato sfruttando un limite inferiore efficiente dal punto di vista informativo per massimizzare l'informazione mutua tra le due modalità di input. Ciò consente di addestrare CLIP-Lite con quantità di dati e dimensioni dei batch significativamente ridotte, ottenendo al contempo prestazioni migliori di CLIP alla stessa scala. Valutiamo CLIP-Lite tramite pre-addestramento sul dataset COCO-Captions e testando il transfer learning verso altri dataset. CLIP-Lite ottiene un guadagno assoluto di +14,0% mAP nelle prestazioni sulla classificazione Pascal VOC e un guadagno di +22,1% in accuratezza top-1 su ImageNet, risultando comparabile o superiore ad altri modelli text-supervised più complessi. CLIP-Lite è inoltre superiore a CLIP nel recupero di immagini e testo, nella classificazione zero-shot e nel visual grounding. Infine, mostriamo che CLIP-Lite può sfruttare la semantica del linguaggio per favorire rappresentazioni visive prive di pregiudizi utilizzabili in compiti downstream. Implementazione: https://github.com/4m4n5/CLIP-Lite
citazione
@inproceedings{shrivastava2023clip,
title = {CLIP-Lite: Information Efficient Visual Representation Learning from Textual Annotations},
author = {Shrivastava, Aman and Selvaraju, Ramprasaath R. and Naik, Nikhil and Ordonez, Vicente},
year = {2023},
booktitle = {Int. Conf. on Artificial Intelligence and Statistics AISTATS 2023},
url = {https://arxiv.org/abs/2112.07133},
}